What is SQL Clone?
Published 27 October 2016
SQL Clone allows you to make editable copies of databases which can be created within seconds and which use very little additional disk space.
It is often useful to make copies of production databases available for development, QA, reporting, staging and UAT. These databases often contain large amounts of data, which means they can take many hours to restore when provisioning a new environment or performing a refresh, and each copy consumes significant amounts of disk space. Sometimes, an empty schema or sample data generated by SQL Data Generator is sufficient. But access to production data is usually necessary to investigate faults or generate offline reports, and developing and testing against it helps to identify edge cases and performance issues which may not otherwise appear until code is in production. This means that long restore times become inevitable, resulting in refreshes happening infrequently, and the number of copies is constrained by available disk space, making it more difficult to parallelize work.
Before SQL Clone - full disk footprint and long wait times to copy databases for multiple targets
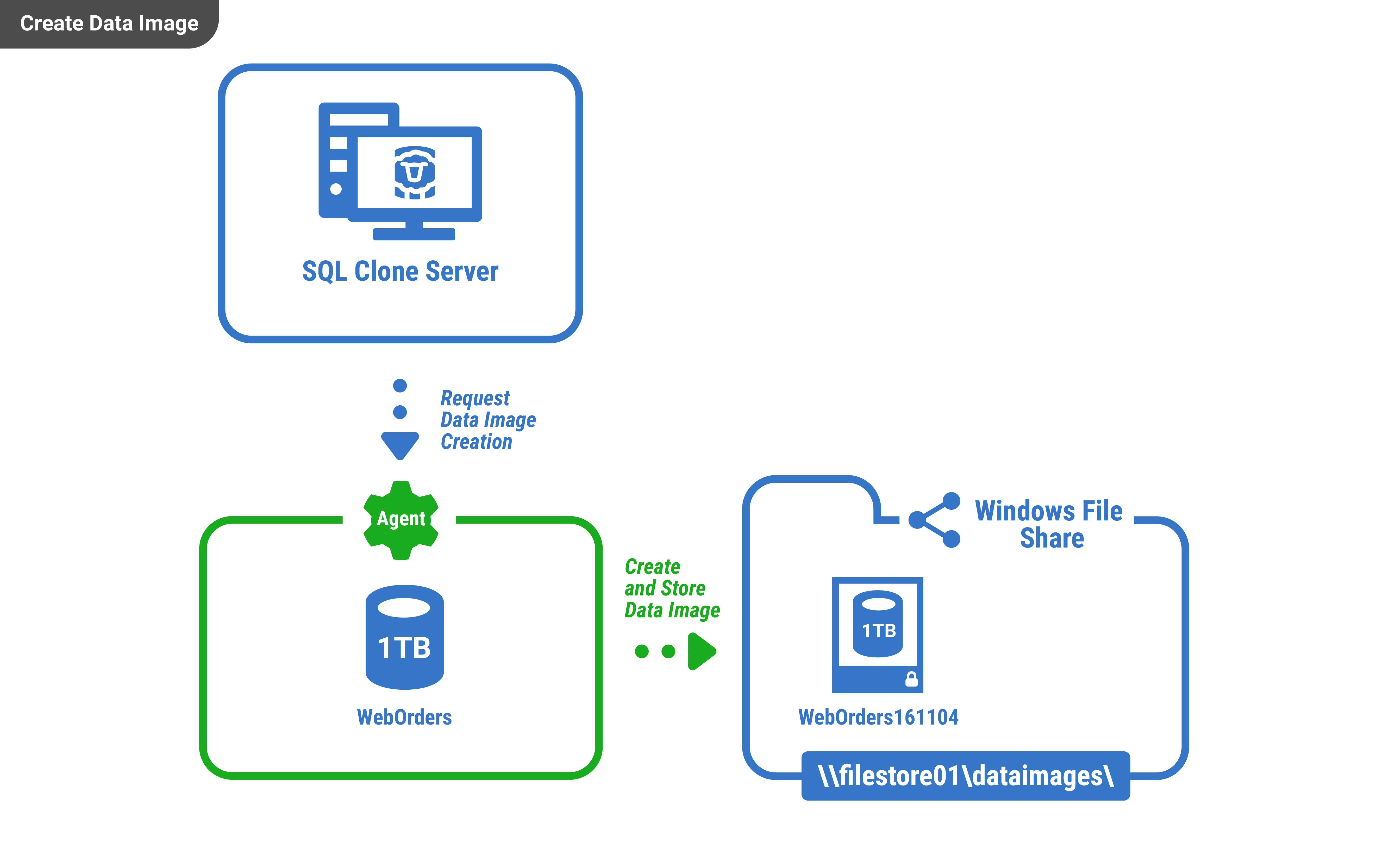
SQL Clone makes it possible to provision copies of databases quickly by using a two-step process in which an image file is created. An image contains the source data from which clones can be derived. It can be created either from a live SQL Server database or from a backup, and is a full copy of the source database at one point in time. This takes about as long as a restoring a backup to create, and consumes as much disk space as a single restore.
Creating an image from a live database requires a SQL Clone agent to be running on the same machine as the SQL Server instance which contains the database. If the image is created from a backup, a SQL Clone agent is needed on a machine with a copy of SQL Server which is capable of reading the backup.
Once you have an image file, you can create an unlimited number of clones from it on any number of machines which can access the file.
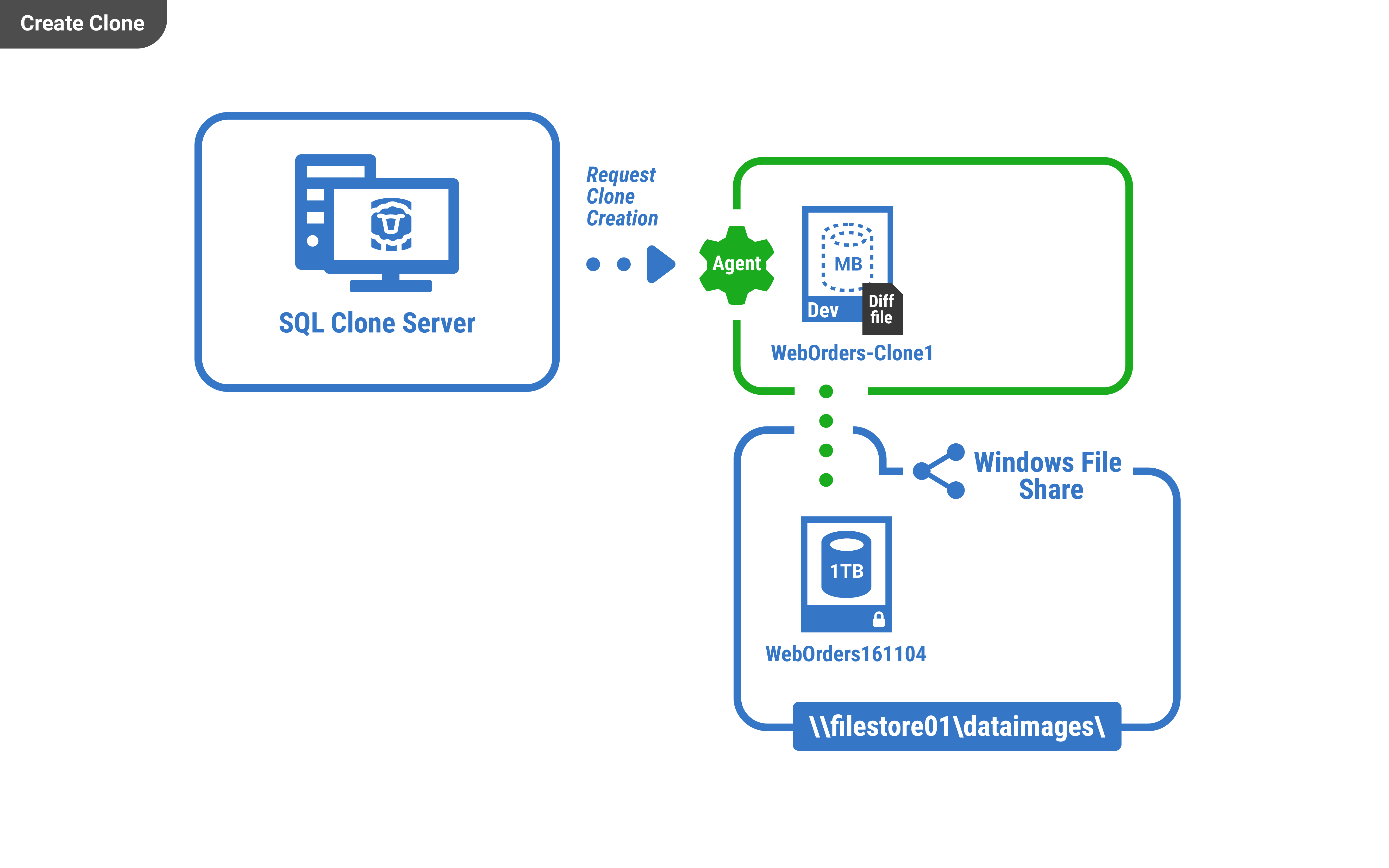
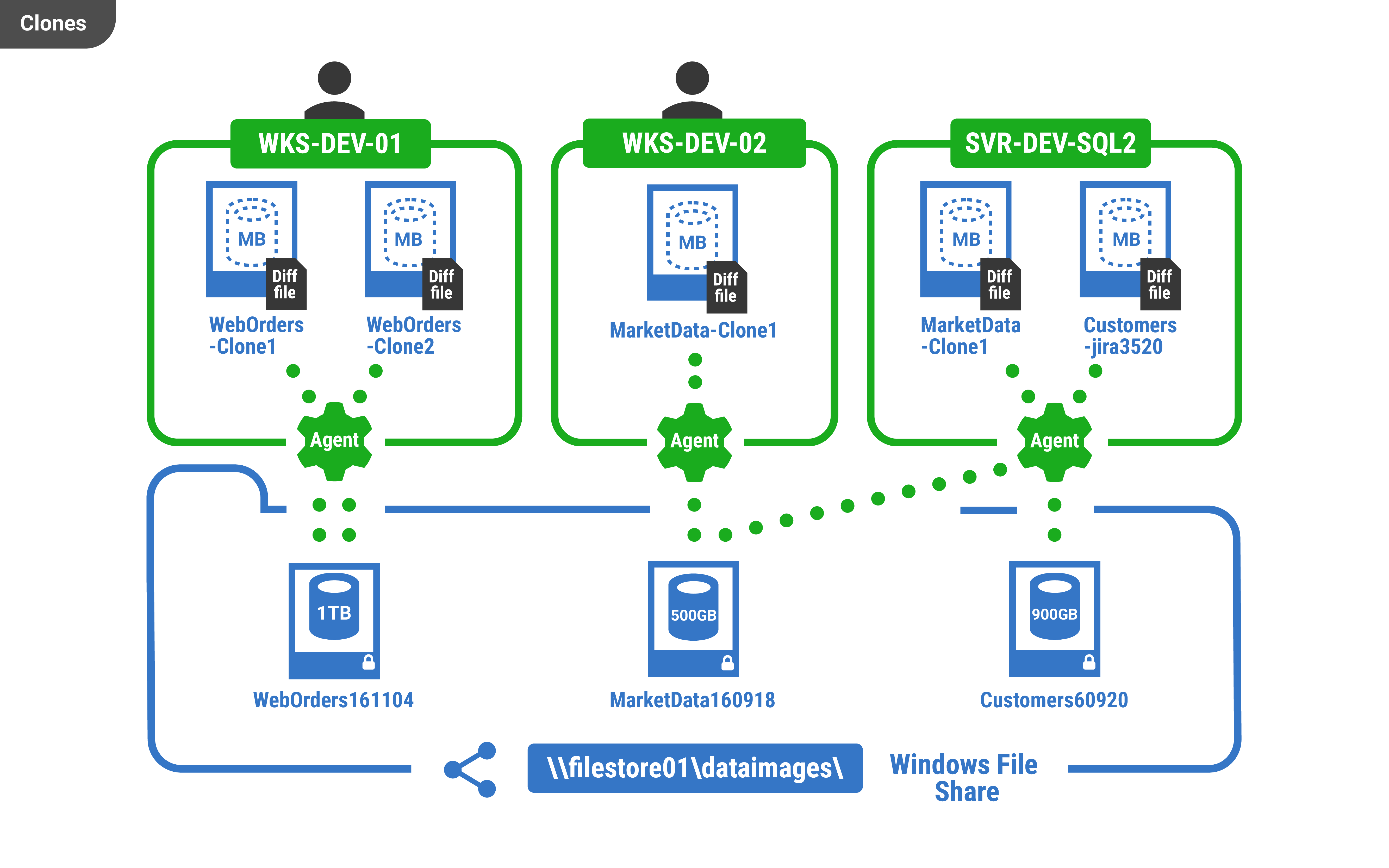
Creating clones usually takes only a few seconds and a few megabytes of local disk space. They work just like normal SQL Server databases, and can be connected to and edited using any program. The changes made are specific to each clone and are persisted to a local diff file. The size of this file is proportional to the amount of changes which have been made. The rest of the data is accessed using the image file.
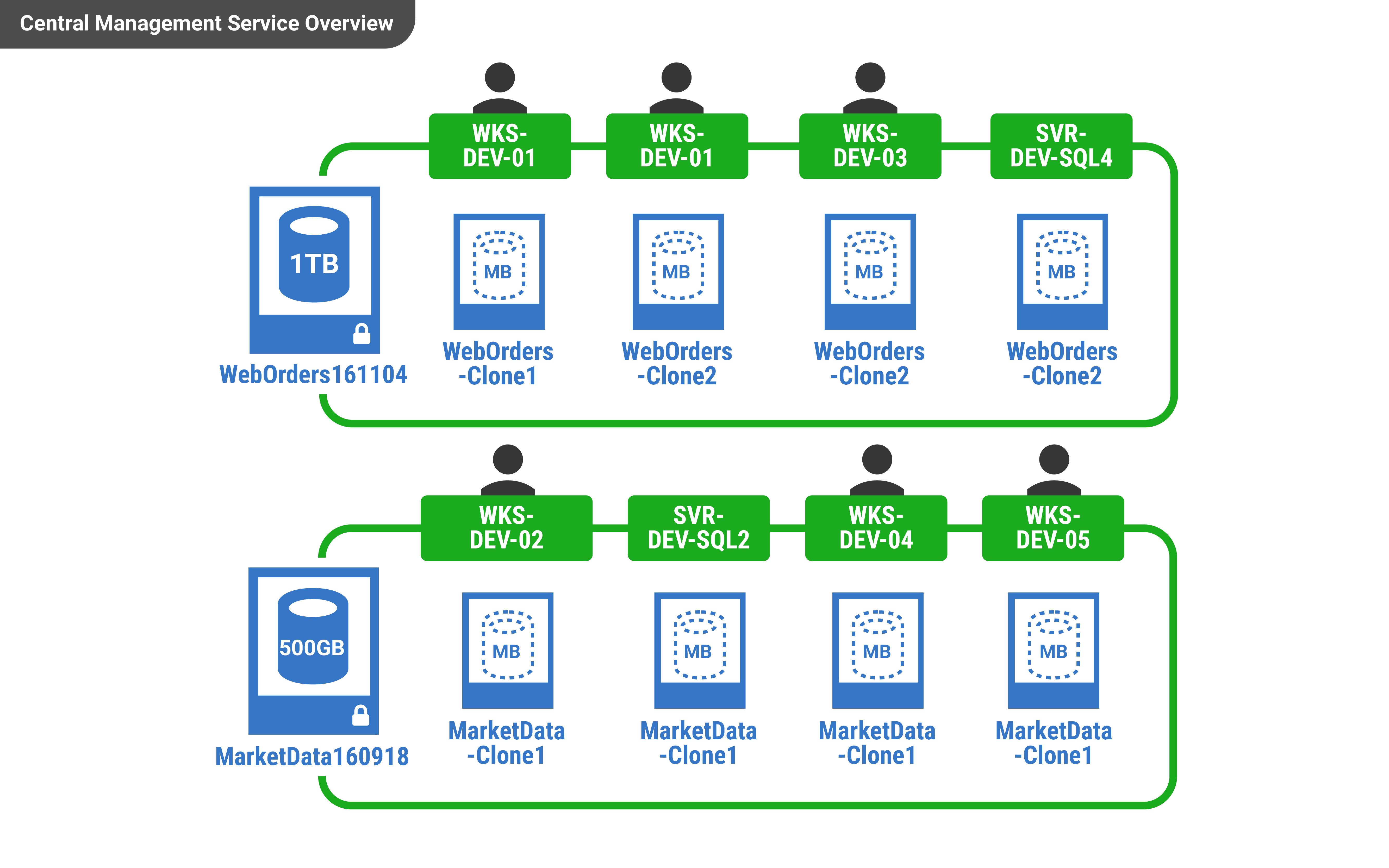
SQL Clone especially shines within a team environment. Once you have data images in place, you can create clones from them under different SQL Server instances.
This documentation contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved




