What is SQL Clone?
Published 27 October 2016
SQL Clone is a server-based software technology that makes it very quick and easy to create many copies, or clones, of a Microsoft SQL Server database, such as for database development and testing purposes.
SQL Clone creates one complete, point-in-time image of the original database, and from this image it can create many clones, exact replicas with the same data, very quickly. Each clone works just like normal SQL Server databases, and can be connected to and edited from Visual Studio or SQL Server Management Studio, just like any other database. However, it's initial size is a small fraction of the original database.
How is this possible? SQL Clone uses virtual hard disk technology built into the Windows operating system to make it possible for many SQL Server instances to share access to the original database's files, held in the image. This means that SQL Clone can install multiple clones of a large database very quickly, wherever they are required in the network, because it doesn't need to copy the files to every machine. Each clone takes up minimal initial storage space on its host. Any subsequent changes to a clone are stored locally, affect only that clone, and won't affect the image.
So, for example, creating four copies of a 500 GB database would, by traditional database copying techniques such as restoring a backup, require 2TB of initial extra storage space, and might take several hours. With SQL Clone it requires 500 GB of initial extra storage space (for the image) and then tens of MB of initial storage for each clone. Creating each clone takes only seconds.
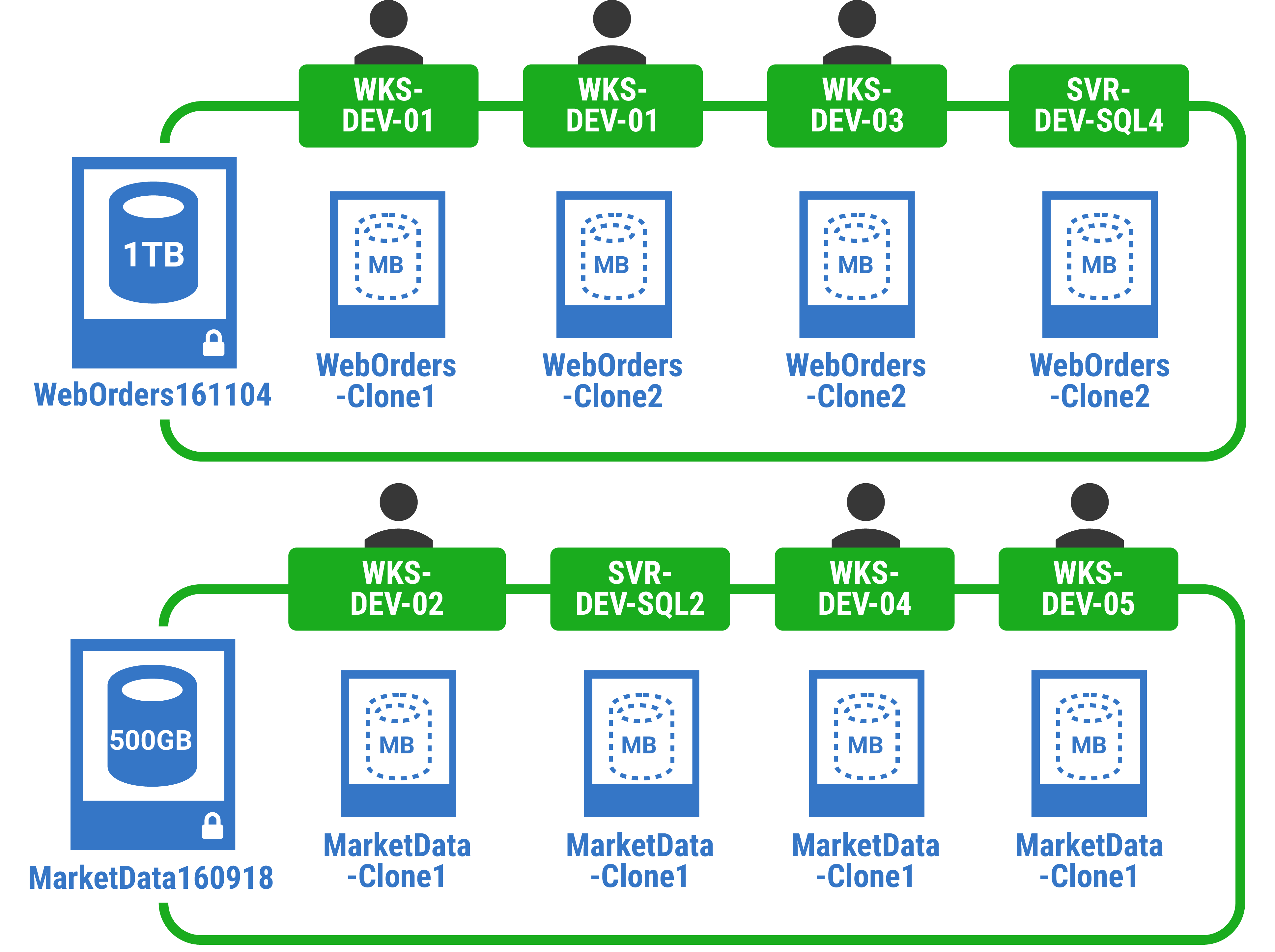
When providing multiple copies of large databases, SQL Clone will save a lot of time and plenty of disk space. Beyond that, it is designed specifically to encourage a DevOps approach to database development and deployment processes.
For the Ops team, SQL Clone removes much of the administrative burden from the task of making copies of large production databases available for development, test, QA, reporting, staging and UAT. It allows them to control where database copies are deployed, who can access them, and to ensure data remains safe. SQL Clone can incorporate data masking to obfuscate or remove personal and sensitive data, before copies are distributed.
For the Dev team, SQL Clone represents a database service that can provide as many copies of a source database as they need, quickly, and on demand. The source database could be the latest development build, stocked with test data, or a large production database. Each developer can work on their own local copy of the same version of this database, with the same data. Any subsequent changes affect only their local copy. Suddenly, they can treat even a very large database as a lightweight, ephemeral resource that they can spin up, use, destroy and recreate, as required. Each time, this takes seconds rather than hours.
Is a clone exactly like a real database?
In short, yes. Cloning, in general, means "producing similar populations of genetically identical individuals". Similarly, a database 'clone', produced using SQL Clone, is a complete copy of a SQL Server database, 'genetically identical' to the original in terms of its files, schema, metadata, statistics and data. SQL Clone makes no changes to SQL Server or the way it works, and SQL Server treats a clone exactly as it would any other database. The underlying difference is that whereas a biological clone, like "dolly the sheep", can function completely independently, a database clone must always retain a connection to its progenitor, i.e. to the image from which it was created. See How Clones Work for more details.
This documentation contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved




