The Misc. Setup Tab
Published 23 March 2018
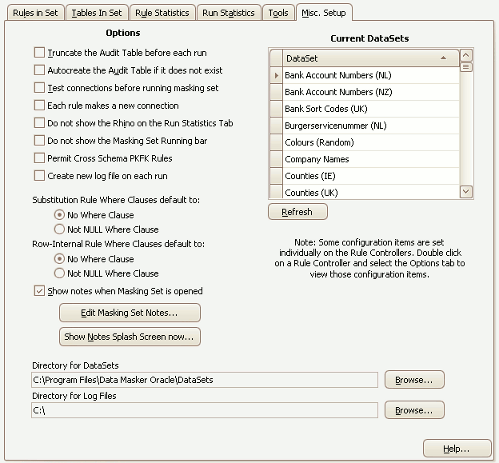
The Data Masker Misc. Setup Tab
Current DataSets
Some masking rules (such as Substitution rules) use datasets which the supply replacement values used to mask the columns in the schema tables. The Current DataSets panel lists the datasets known to the Data Masker software and offers the ability to refresh the list. More information regarding the available datasets can be found on the datasets help page.
Options
Test connections before running masking set
If checked, the login details for all Rule Controllers will be tested before any masking rules are executed. This option is useful if the masking set is configured with multiple Rule Controllers as it can prevent a login failure resulting in a partially run masking set.
Truncate audit table before each run
The Data Masker software requires an audit table to be present in the target schema. This audit table is used to record the execution state of the rules and it also enables a masking set to restart a run which failed due to error. By default, the audit table records the state of multiple masking runs. If it should be required to have only the results from the last run stored in the audit table, then this option can be enabled to remove the existing rows from the audit table contents prior to each masking set execution.
Autocreate audit table if it does not exist
If enabled, this option will automatically create the audit table if it does not already exist in the database and schema to which the rule controller is connecting. The audit table is required in order for the masking set to successfully execute. Note that if the Autocreate option is used, the audit table will be created in the default tablespace with the default storage parameters of that tablespace.
Show notes when masking set loads
A masking set can be configured to display a notes splash screen when it is opened. These notes are saved with the masking set and are intended to provide useful comments and documentation regarding the masking set and masking rules. If checked, this option enables the display of the masking set notes at startup.
Show Notes Splash Screen
Immediately displays the notes splash screen. This can be used to review the contents of the masking set notes.
Edit Notes Splash Screen
Launches a form which enables the contents of the masking set notes screen to be created and edited.
Do not show the Rhino on the Run Statistics tab
The Run Statistics tab contains a graphic of a small pink running rhino which serves as a visual indicator that the masking set is executing. The rhino graphic first appeared in an early beta version of Data Masker as a humorous icon and has become something of a mascot. So much so that we get complaints if we try to leave it out of newer versions. Its presence is optional, however, and if you do not wish to see it then enabling this option will remove it.
Each rule makes a new connection
The normal method of operation for the Data Masker software is for each thread to make and hold open a connection to the target schema. This connection is used by all rules running on the thread and is only closed when the masking set run is finished. Under some circumstances it is better to have each rule connect and disconnect rather than using a pooled set of connections. This option is slower since it requires to overhead of making a connection for each rule but can be useful if network timeouts or other errors such as ORA-03113 End of file on communication channel are being received.
Permit Cross Schema PKFK Rules
PKFK Synchronization Rules are designed to synchronize the anonymization of the values in columns of tables which form the join keys between those tables. Usually the rule is only applied to tables within the same schema. If it should be needed to apply PKFK Synchronization operations between tables in different schemas this option must be enabled. Always discuss this enabling this option with the Data Masker Support Team at Support@DataMasker.com prior to activation. They will provide you with information on the possible complications associated with cross schema PKFK Synchronization operations.
Create New Log File on Each Run
The Data Masker software creates a new log file in the specified log directory (see below) each time it is launched. This log file will contain a record of all the actions taken by the Data Masker software. If the software has been operational for some time, these log files can become large and will contain a great deal of information and this can make it hard to interpret the contents. This option will create a new log file each time a masking set is run. Thus the log file will contain only the information specific to those operations. The Tools Tab also contains a button which can force the creation of a new log file at any time. Note that the previous log file is not overwritten or deleted when a new log file is created, the log files are timestamped and will remain in the log directory until manually removed.
Substitution Rule Where Clauses default to
The Where Clause panel on Substitution rules contains a options to configure the rule to operate only on NOT NULL values. This setting determines the default state of those options when a new Substitution rule is created.
Row-Internal Rule Where Clauses default to
The Where Clause panel on Row-Internal rules contains a options to configure the rule to operate only on NOT NULL values. This setting determines the default state of those options when a new Row-Internal rule is created.
Configuration Details
Directory for Log Files
The Data Masker software writes out various informational messages to a log in order to record its progress. A new log file is created each time the application starts and this field indicates the directory in which the log files will be placed.
Directory for Datasets
Some masking rules (such as Substitution rules) use datasets which the supply replacement values used to mask the columns in the schema tables. This field indicates the directory in which the Data Masker software will look for the dataset files. The Data Masker software ships with a wide variety of datasets and it is possible to create your own user-defined datasets.
This documentation contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved




