About XML Masker Rules
Published 23 March 2018
<customer id="122336">
<customer_name>Tom Smith</customer_name>
<address>Apt 46a</address>
<address>21 Main Street</address>
<town>Anytown</town>
<region>Region1</region>
<country>Ireland</country>
<telephone>123 456 789</telephone>
</customer>
An Example of a XML Masking Requirement
Consider the above simple example XML data - the customer_name element (as well as other elements) clearly contains sensitive personally identifiable information (PII data). The entire XML structure is stored in a column of the XMLTYPE datatype in a table named customer_data. In order to mask this information the rule must reach down into the XML and modify the text between the two <customer_name> tags without changing anything else.
Note: if your XML data is not stored in a column with a datatype of XMLTYPE, the Data Masker software can still mask it. The XMLMasker rule works transparently on columns such as VARCHAR2 as long as the .xml data they contain has a valid structure.
Fundamentally, there are four things which need to be specified when masking XML data. First the rule needs to know how to find the element of to be masked. Second, the rule needs to know what information needs to be masked - this is not necessarily the text value of the element as it could also be the text value of an attribute belonging to that element. Thirdly, the rule needs to know how to deal with XML namespaces and lastly the rule needs to know what information to use to mask the found element or attribute text - this last data is generated from the specified dataset.
The XML Masker rule finds the data to be masked using an XPath statement. If just the name (it is case sensitive) of the element is provided, a suitable wildcard XPath statement to locate the text data for any and every element with that name will be automatically generated. If the Full XPath option is chosen, then that specific statement will be used to locate the data to be masked.
Important Note: XML namespaces, if used, strictly determine the processing rules in force and a XML processor configured with one namespace cannot process XML which has a different namespace - even if the XML structure is identical. The value will simply be ignored and no error will be returned - the data will not be masked. This is quite problematic if multiple namespaces are present in the XML in the individual rows of the table or if multiple namespaces are used within one XML entity. If the namespace is specified in the first element of the XML, the XML Masker rule has an option to figure this out and use the specified namespace for each XML row. If the namespace is not specified in the first element of the XML then you can specify a namespace manually - if there are multiple namespaces present in any one XML construct the data can still be masked - however this is very advanced topic and you should contact the Data Masker Support Team for assistance prior to attempting this.
The data content to be masked is specified by an additional option. It is possible to mask the text content (the value) of the element itself or to choose to mask the text value of an attribute belonging to that found element.
For each row in the table (or a subset selected via the Where Clause and Sampling options) the XML data content is located using the rules XPath configuration. Then the text contents of that XML element (or one of its attributes) are replaced with new data derived from the specified dataset.
The dataset is specified on the Datasets tab of the New XML Masker rule form. To configure the dataset simply select it and configure its options as you would for a standard Substitution rule.
After the rule has executed, each XML value to be masked will have its content updated with a suitable item from the datasets. Note that each row in the table will get a new value but if there are multiple elements in the XML of any one row, both of those elements will receive the same updated data. In order to configure a rule to modify only the contents of the second customer_name XML tag in each row, a custom Full XPath to that tag would need to be specified.
The configuration of a XML Masker rule is straight forward. The target table and column is chosen and the section on How to Find the XML Element is filled in. This can either be a wild card XPath or a full XPath string. Next, the Part of the XML Element to Mask section is filled in. This can either be the value of the element or the value of an attribute belonging to that element. The third action is to specify the Namespace Option and either let the XML Masker rule figure out the namespace or to fully specify one via the option. The dataset and Where Clause parameters are specified on the remaining tabs of the rule. clause information entered into the field provided. The help file for the New XML Masker rule form provides more details on the mechanics of this process.
XML Masker Rule Example Configurations
Given the XML example data below...
<customer id="122336">
<customer_name>Tom Smith</customer_name>
<address>Apt 46a</address>
<address>21 Main Street</address>
<town>Anytown</town>
<region>Region1</region>
<country>Ireland</country>
<telephone>123 456 789</telephone>
</customer>
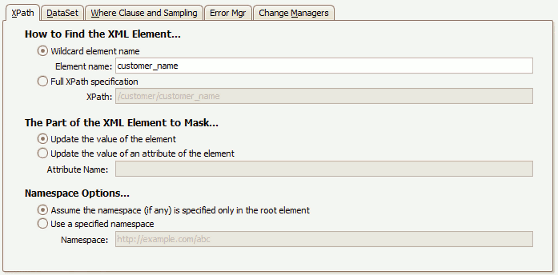
...the above configuration will successfully mask the values of all customer_name elements which appear anywhere within the XML.
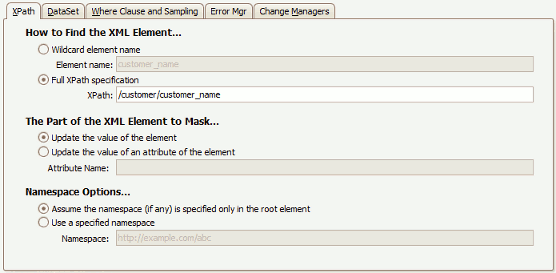
..the above configuration will successfully mask the values of all customer_name elements which appear on the XPath of /customer/customer_name within the XML. Other values for customer_name elements which are not on this path will not be masked.
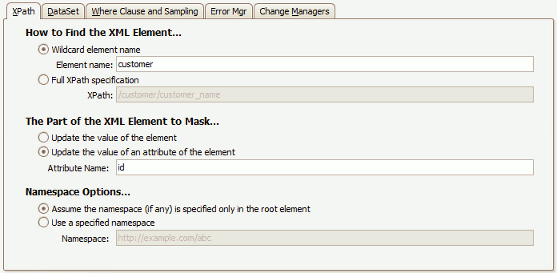
...the above configuration will mask the values of all id attributes belonging to any customer element which appears anywhere within the XML.id attributes belonging to other elements will not be masked.
XML Masker rules are created by launching the New XML Masker rule form using the New Rule button located on the bottom of the Rules in Set tab.
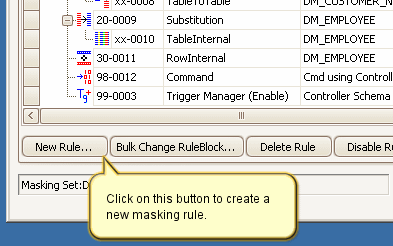
Adding a XML Masker rule
This documentation contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved




