Can I create my own replacement datasets?
Published 06 January 2020
Data Masker delivers more than 100 replacement datasets which will help you achieve a like-for-like data masking policy as well as manage items where a variance may be a better option. These datasets fall into several categories which are dependent upon the data type and the nature of the item to be replaced. As examples:
- A name replacement. Character based, no validation required, but must have gender options and be able to provide concatenated values to create a “Full Name”.
- The place an individual may live – town/county/province/state/zip or postal code.
- A replacement for an item which is algorithmic (i.e. typically it must checksum) and as an example a National Identification number in many countries. It could also be a randomly generated credit card number or perhaps a Medicaid/Medicare number.
- Comment column text replacement. The comment column may contain Personal Information and it must be changed.
- Date Management. Guidance tells us that a Date of Birth is protected and so must be changed. We advocate the use of variance practices so that data demographics are not significantly changed. Legislation also directs us to consider any date/time item which will place a living person at a place at a point in time.
- Numeric data where you may wish to randomly replace or, perhaps, slightly vary a number.
These features and functions are available from Data Masker at installation time, but it is fair to note that there may be some data replacement requirements which are country, marketplace or language specific.
Therefore, Data Masker was engineered to support “User Defined Replacement Datasets”.
There are two replacement dataset types which could readily be described as “Simple” and “Correlated.
A “Simple” replacement dataset contains one replacement entry for each row in the replacement file.
A “Correlated” replacement dataset has a number of elements which are related and which we would like to fetch into our newly masked rows “side by side” - for instance:

Which in this case is Zip Code, Town, State and County.
Data Masker contains examples of both the “Simple” and “Correlated” replacement datasets and you can replicate them with your own specific requirements.
The “Simple” example delivered with Data Masker is “Endangered Mammals”. This is a file which is positioned in the Data Masker “DataSets” installation directory:
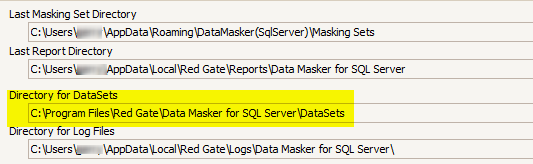

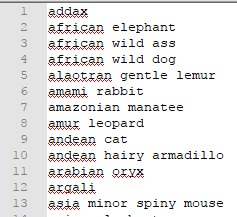
Notice that the file type is .UDEF – a simple DOS file extension which denotes the file as a Data Masker User Defined Replacement DataSet and will be available to Data Masker so long as it is positioned in the DataSets directory.
You can make your own simple replacement datasets in just the same way. The guidance is:
- One entry per row, no blank or empty rows.
- Save the file with the .UDEF extension in the DataSets directory
- If you have Data Masker open then either stop it and restart or go to the Misc Setup tab and “Refresh” the dataset list
Correlated Replacement datasets are just as easy. The differences are:
- Each row may contain up to 8 items, delimited as you see fit
- The file naming convention is the DOS file extension of .UDEFC
As an example:
El Arish International Airport;1.07329941;33.83580017;EG;El Arish;AAC
Annaba Airport;36.82220078;7.809169769;DZ;Annabah;AAE
Apalachicola Regional Airport;29.72750092;-85.02749634;US;Apalachicola;AAF
Arapoti Airport;-24.10390091;-49.78910065;BR;Arapoti;AAG
Aachen-Merzbrück Airport;50.82305527;6.186388969;DE;Aachen;AAH
Arraias Airport;-13.02388859;-46.88555527;BR;Arraias;AAI
Cayana Airstrip;3.898681;-55.577907;SR;Awaradam;AAJ
Buariki Airport;0.185277998;173.6369934;KI;Buariki;AAK
Aalborg Airport;57.09275891;9.849243164;DK;Aalborg;AAL
Malamala Airport;-24.81809998;31.54459953;ZA;Malamala;AAM
Al Ain International Airport;24.26169968;55.60919952;AE;Al Ain;AAN
Anaco Airport;9.430225372;-64.47072601;VE;Anaco;AAO
Andrau Airpark;29.72249985;-95.58830261;US;Houston;AAP
Anapa Vityazevo Airport;45.0021019;37.34730148;RU;Anapa;AAQ
Aarhus Airport;56.29999924;10.61900043;DK;Aarhus;AAR
Which represents an airport name, latitude, longitude, country, municipality and IATA code – all separated by a semi-colon delimiter (which was our choice).
Using user defined datasets
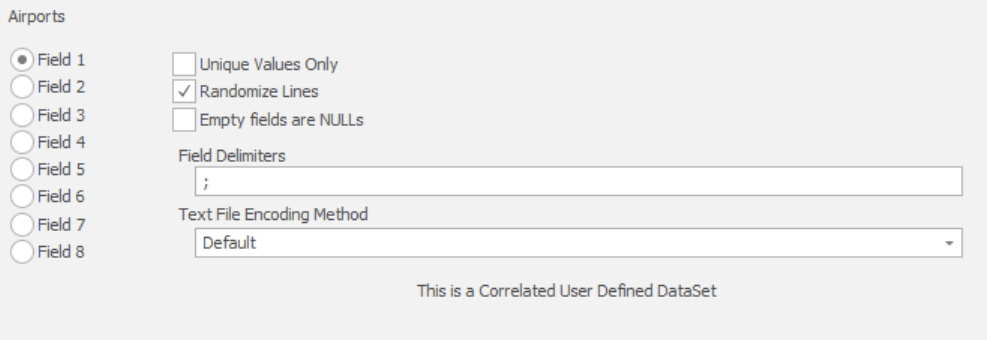
User defined datasets will be available alongside built-in datasets. All user defined dataset will have the following options.
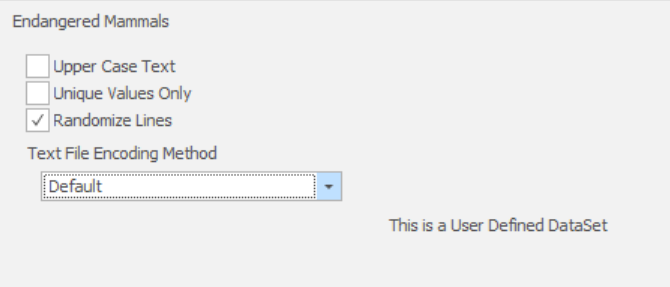
"Text File Encoding Method" should be set to the text encoding the file is using. If you have issues with incorrectly displayed characters after masking, you should ensure your text encoding is correct. "Default" will use the current system's default text encoding.
Correlated user defined datasets will include additional options to choose the field to use, and how to separate each field (field delimiter). In the airports example above, we're using a semicolon as our field delimiter.
Further help in implementing User Defined Datasets is available from support@red-gate.com .
Some Notes on User Defined Datasets
- Numerous datasets suitable for a wide variety of purposes ship with Data Masker software and are installed when Data Masker software is installed. By default the datasets are stored in a directory named DataSets located below Data Masker installation directory. The location of this directory can be changed through the use of the configuration options on the Misc. Setup Tab. Any user defined datasets which are created must be placed in the same directory as Data Masker supplied datasets. If this is not done Data Masker software will not be able to configure any rules to use it.
- Be careful not to allow any blank lines (particularly at the very end of the file) in the text file. Data Masker will happily accept an empty line as a valid dataset value and will insert or substitute it as with any other data.
- Be careful to trim off any leading and trailing space characters from each line. Data Masker will use the data "as-is".
- The text file containing the data must have an extension of .udef
- Any underscore "_" characters in the file name will be replaced by spaces when the name appears in the dataset list inside Data Masker software. Thus a filename of Endangered_Mammals.udef will appear on the display as Endangered Mammals.
- As with all datasets, you do not need to worry about field length considerations. For example, a rule applied to a varchar(20) field will not generate errors if there are some lines in the user defined dataset that are longer than 20 characters. Data Masker will ignore the lines in the user defined dataset which are too long for the field into which they are being written.
- It is possible to use all of the sampling and Where Clause options with user defined datasets - just as with the supplied datasets.
- It is possible to enable Randomize and Unique Values Only options on user defined datasets.
- The sample user defined dataset entitled Endangered_Mammals.udef is installed (by default) along with the standard datasets in the DataSets directory.
This documentation contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved




