Can I make a Row-Internal rule faster?
Published 06 January 2020
Performance improvements in Version 7
Version 7 includes significant performance improvements. If you're trying to speed up an existing masking set, check legacy performance mode is disabled before trying these steps.
It’s not unusual to have one (or many) columns in a table which contain other column(s) content. As an example, a FULL_NAME will be FIRST_NAME linked with LAST_NAME. The ultimate objective of a credibly masked database starts at this row-level based function. Data Masker provides this along with the ability to add replacement dataset values.Before going too much further let’s explain what a Row-Internal rule is and how it works.
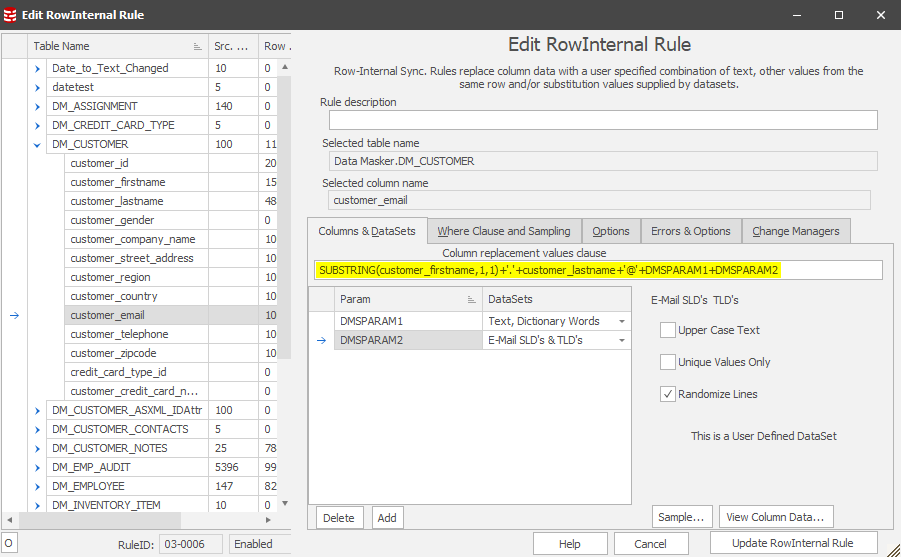
How does it work?
The Row-Internal rule issues update statements with 1,000 row commit intervals against the database. The advantage of this approach is that progress statistics can be displayed in the Rule Statistics tab.
For instance:
UPDATE [dbo].[DM_CUSTOMER] set [customer_email] = SUBSTRING(customer_firstname,1,1)+'.'+customer_lastname+'@'+@DMSPARAM1+@DMSPARAM2 WHERE [customer_id] = @j_customer_id
In this case the update block is a TSQL statement containing functions, column references and literals as well as the replacement values for DMSPARAM1 and DMSPARAM2 (parameter substitution) driven by the customer_id.
UPDATE DM_CUSTOMER set customer_email = SUBSTR(customer_firstname,1,1)||'.'||customer_lastname||'@'||DMOPARAM1||DMOPARAM2 WHERE ROWID = rowID
In this case the update block is a TSQL statement containing functions, column references and literals as well as the replacement values for DMOPARAM1 and DMOPARAM2 (parameter substitution) driven by the customer_id.
How does Data Masker identify rows to update?
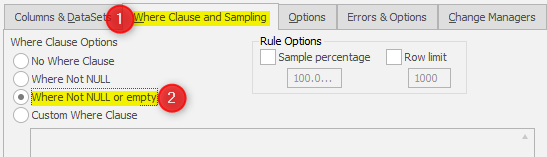
Prior to the update statement being issued Data Masker queries the database for the “row identifiers” of those rows which match the where clause:
Data Masker for SQL Server requires the presence of a Primary or Unique index to be able to identify each row as a masking candidate and therefore be able to select or update based upon the where clause. Data Masker for Oracle uses ROWIDs as its row identifiers. Row identifiers are downloaded to the Data Masker client and temporarily stored in one of its working directories. This temporary file is removed at the end of the update process.
Should a PK or UK not exist on the table Data Masker will stop the masking rule process.
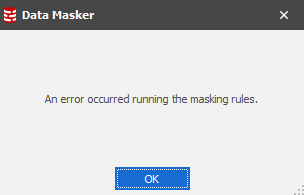
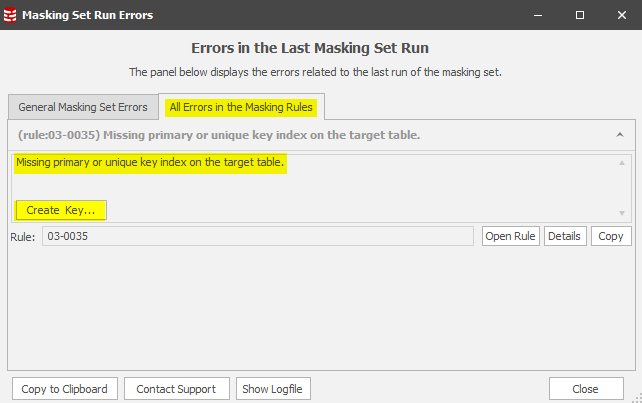
Notice the Create Key feature. This will give us everything we need to create an Identity Column (a unique row identifier) on the table and assign it as a Primary Key:
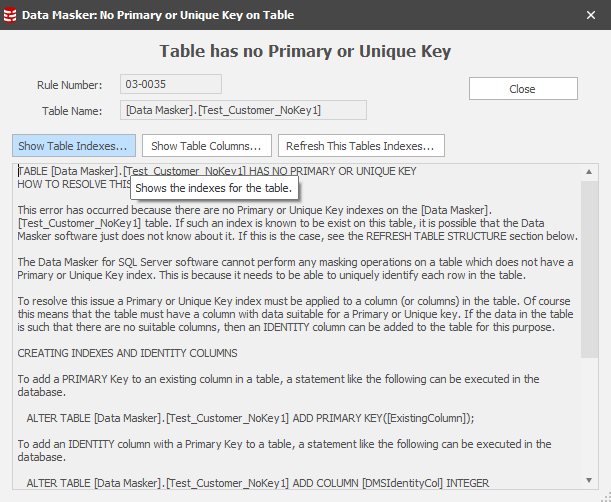
Note also the final statement in this panel. You must refresh Data Masker’s understanding of the table structure and save the masking set away.
So, can I make it faster?
With the way the rule above is configured, using the Data Masker replacement dataset parameters, the answer is “No”. Data Masker needs to provide those replacement values, so the approach can’t be changed.
But what if I’m not using Data Masker replacement datasets?
Very often that can be the case. You don’t need to use replacement datasets since the row contents combined, perhaps, with functions and literals may do everything you need:
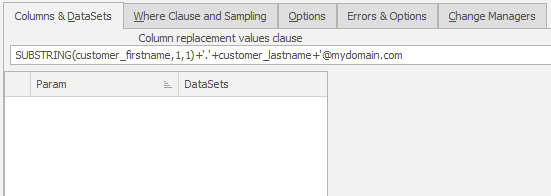
If this is the case, we can simplify the approach and therefore save time. There’s a switch you can enable in the Options tab:
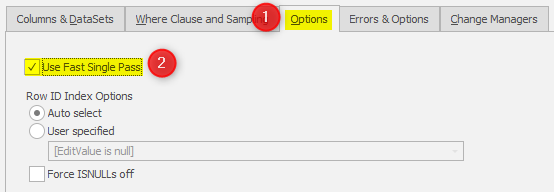
If enabled, the update statement is simplified to:
UPDATE DM1 set [customer_email]=SUBSTRING(customer_firstname,1,1)+'.'+customer_lastname+'@mydomain.com' FROM [dbo].[DM_CUSTOMER] DM1 WHERE [customer_email] Is Not Null and [customer_email] <> ''
UPDATE DM1 set customer_email=SUBSTR(customer_firstname,1,1)||'.'||customer_lastname||'@mydomain.com' FROM DM_CUSTOMER DM1 WHERE customer_email IS NOT NULL
Performance is improved because the row identifiers do not need to be gathered in the initial instance nor is there a “wait” scenario as 1,000 row update statements are transmitted to the server.
There are two considerations in using this switch:
- There’s no control of the commit interval
- Run statistics won’t be available until the statement has completed and rule elapsed runtime will not be displayed
Validating this approach is as simple as setting the switch and running the rule using the right mouse button action / Run Rule. Validate the data change using a data viewer of your choice and be sure to save the masking set!
This documentation contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved




