Data Image Definition Examples
Published 30 November 2021
Contents
Empty
Similar to Docker, a data image is created based on a definition contained in a .yaml file. To get started quickly, we will create a simple empty data image which will allow us to create an empty SQL Server 2019 data container.
Create a file development.yaml with your data image specifications using the empty source for a SQL Server 2019 database engine:
sourceType: empty name: dev engine: mssql version: 2019
And here's an equivalent example but for PostgreSQL 14:
sourceType: empty name: empty-pg engine: postgresql version: 14
Likewise, one for MySQL 8.0:
sourceType: empty name: empty-mysql engine: mysql version: 8
You can now jump to Creating a data image (or alternatively, choose a different source type below for your data image definition).
Backups
Another option is to provide a database backup file as a source for a data image:
sourceType: Backup name: backup-mssql engine: mssql version: 2019 backups: - path: my-backups/backup1.bak
The backup will be processed from a file share. The file path has to be provided relative to the configured file share root. The entire file share will be mounted to the temporary database to perform the backup restore
Because the application uses Linux filesystem you need to use Linux format for backup file paths (i.e. use / as path delimiters).
You can restore multiple backup files by adding multiple entries in the backups section.
sourceType: Backup name: backup-mssql engine: mssql version: 2019 backups: - path: my-backups/backup1.bak - path: my-backups/backup2.bak
In this example we want to create an image by restoring two backup files: backup1.bak and backup2.bak.
For PostgreSQL custom backups, please see the examples on this additional page.
Striped Backups
For SQL Server, Redgate Clone supports striped backup files.
Place all the backup files into a single directory on the share and then provide the path to the directory as the path . Redgate Clone will use all the files in this directory as part of a single restore operation in SQL Server.
Pre and post scripts
You can run a SQL script as a part of data image creation process to modify the databases included in the image. The scripts can be specified as a pre- or a postScript, allowing to make modifications both before and after an empty database is created (for empty images) or a backup is restored (for data images created from backups). For example, a script can be used to add tables and/or data to an empty data image, or to modify user permissions on a data image restored from a backup. These changes is stored in the data image and will be included into all data containers created from it.
To run a pre-script:
sourceType: Backup name: backup-mssql engine: mssql version: 2019 backups: - path: my-backups/backup1.bak preScript: | CREATE DATABASE [myDatabase]
In this example, the pre-script creates an empty database called "myDatabase" before restoring the backup file.
Likewise, you can also add a post-script to perform SQL operations after the database backup has been restored (or the empty data container has been created) (e.g. set permissions). Here's an example:
sourceType: Backup name: backup-mssql engine: mssql version: 2019 backups: - path: bak/AdventureWorksLT2019.bak preScript: | CREATE DATABASE prescript postScript: | CREATE TABLE [AdventureWorksLT2019].[dbo].[Sheep] (id INT)
Note: If your pre or post script is multi-line, make sure you indent it or you may get an error about " Operation failed (OperationFailed=41):" and "could not find expected ':'"
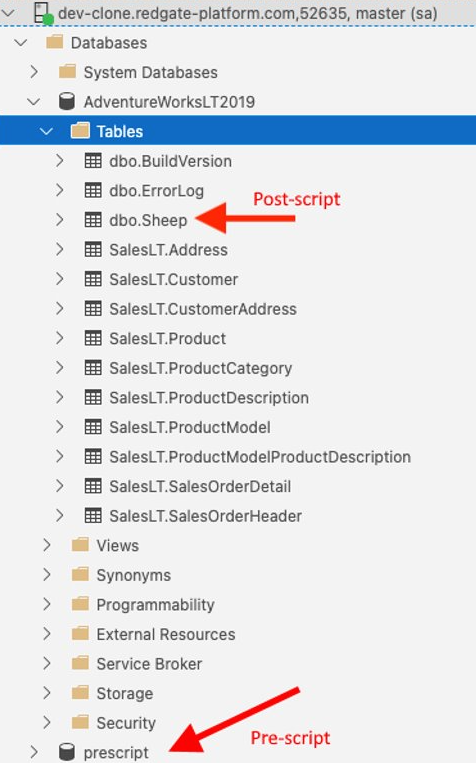
The order of operations during data image creation will be as follows:
- An empty SQL Server instance is spin up.
- Database
prescriptis created (pre-script). - Database
AdventureWorksLT2019is created (database restore). - Table
dbo.Sheepis added to theAdventureWorksLT2019database (post-script).
And the outcome will be:
This documentation contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved




