Split Table
Published 15 May 2013
You may want to split a table into two separate tables, for example if new requirements arise, or if you need to enforce referential integrity on a set of columns. The Split Table refactoring enables you to do this, by generating a script to move or copy columns to a new table whilst retaining the original data in the table. The script also modifies referencing objects so that queries that accessed the original table return the same result after the split has taken place.
To use Split Table to create constraints with referential integrity, copy the required columns to the new table (but do not move any columns). The new table is then the referential integrity table. Referencing objects are not modified.
In this feature, the existing table that you want to split is called the primary table; the new table to which the columns are moved or copied is called the secondary table.
Before you split a table, you are recommended to read this page, to ensure you understand fully what will happen when you split the table.
- Preparing the table describes some points you may want to consider prior to generating the split table script.
- Splitting the table describes how you use the Split Table feature to generate the script.
- The split table script describes in detail what happens to your tables and referencing objects when you run the script.
- Script failure or cancellation describes what happens if the script fails or is cancelled.
You are advised to back up your database prior to running the split table script.
Preparing the table
You may wish to consider the following points to plan how the columns are to be split and to prepare your data appropriately. You should also read The split table script for a full understanding of what will happen when the table is split.
When you split a table, the primary table retains its name. You supply the owner and name for the secondary table, and choose which columns are to be included in the secondary table.
Note the following:
Shared columns
You must ensure that at least one column is copied to the secondary table so that it exists in both tables (is shared). SQL Refactor uses the shared columns to create the foreign key, and the primary key for the secondary table. Therefore, before you select the Split Table feature, you must ensure that the primary table contains the columns that you want to be shared. The values contained within the shared columns must uniquely identify each row of data in the secondary table.
Data
For columns that remain in the primary table, all data is retained.
For columns that are copied or moved to the secondary table, SQL Refactor uses the DISTINCT keyword when possible to ensure that only unique data is copied or moved.
However, for the following data types the DISTINCT keyword cannot be used:
- XML data
- SQL Server 2000 large object (LOB) data (text, ntext, image)
Therefore, if you choose to move or copy any of these data types, SQL Refactor cannot use theDISTINCTkeyword when the secondary table is populated. This means that all data is moved or copied to the secondary table, including any duplicate data. If the shared columns contain duplicate data, the primary key cannot be created on these columns and the script will fail. Therefore, if you know you will be moving or copying one of the data types listed above, prior to splitting the table you must ensure that there is no duplicate data in any of the columns that will be shared.
Computed columns
If you move or copy a computed column, you must ensure that any columns that are referenced by the computed column are also moved or copied. If you do not do this, SQL Refactor displays a warning, and you cannot generate the script.
If you copy a computed column and all its referenced columns, and the computed column is persisted, SQL Refactor converts the computed column to a normal column in the secondary table so that data is retained. For example, a column that computes two columns that have data type char(50) is changed to a normal column of data type char(100).
If you copy a computed column and all its referenced columns, and the computed column is not persisted, SQL Refactor displays a warning; if you have chosen to create the foreign key on the secondary table, the script will fail because it is not possible to create a foreign key on a column that is not persisted.
If you move a computed column and all its referenced columns, the computed column remains a computed column in the secondary table.
You cannot move a column from the primary table if it is required by a computed column in the primary table (but you can copy it).
XML columns
XML columns cannot be shared because a primary key cannot be created on an XML column.
The DISTINCT keyword cannot be used with XML columns; for details, see Data.
Timestamp columns
Timestamp columns cannot be copied or moved. This is because data cannot be inserted into timestamp columns and the original values cannot, therefore, be inserted into the secondary table.
Common language runtime data
If a common language runtime (CLR) data column is copied or moved to the secondary table and the CLR data is not byte ordered (IsByteOrder is false), the script will fail. This is because the DISTINCT keyword cannot be used on a CLR column that is not byte ordered.
Large object data
- Columns that contain large object (LOB) data cannot be shared because a primary key cannot be created on LOB data.
- For SQL Server 2000 databases, the DISTINCT keyword cannot be used with LOB data; for details, see Data above.
Null values
Null values are not allowed in shared columns in the secondary table. This is because the shared columns are used to create the primary key on the secondary table, and primary key columns cannot contain null values.
If any columns that you share (copy to the secondary table) allow null values, a warning is displayed. When the script is run, these columns will be modified to disallow nulls (set to NOT NULL).
If any of the data in the shared columns contains null values, the script will fail when it is run.
Identities
If you copy or move an identity column, the identity is copied or moved, and data will be inserted using the IDENTITY_INSERT setting.
Partition schemes
You cannot move a column over which the primary table is partitioned to the secondary table. If you attempt to do this, SQL Refactor displays a warning. You can, however, copy the column if required.
DML triggers
All DML triggers that access the data in the primary table are dropped. You are recommended to save these triggers prior to running the split table script if you will want to recreate them following the split.
Triggers that do not access the primary table are preserved, but are not duplicated on the secondary table.
Splitting the table
To split a table:
- On the SQL Refactor menu click Split Table, or in the Object Explorer pane, right-click the table and click
 Split Table.
Split Table.
The Split Table dialog box is displayed.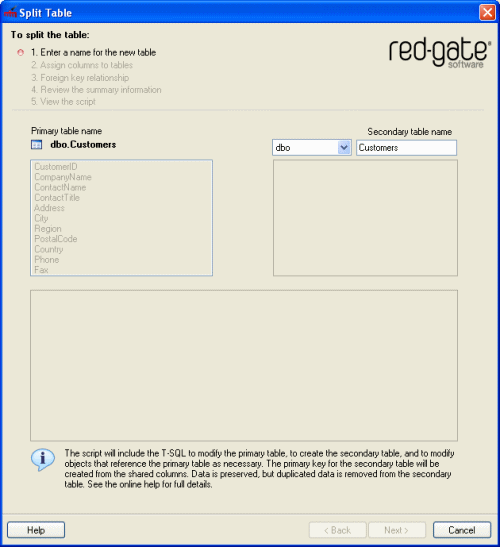
- In Secondary table name, type the name for the table to be created.
If required, you can change the owner for this table by selecting from the list.
SQL Refactor checks that you have entered a valid name and the name is not already in use. - Click Next.
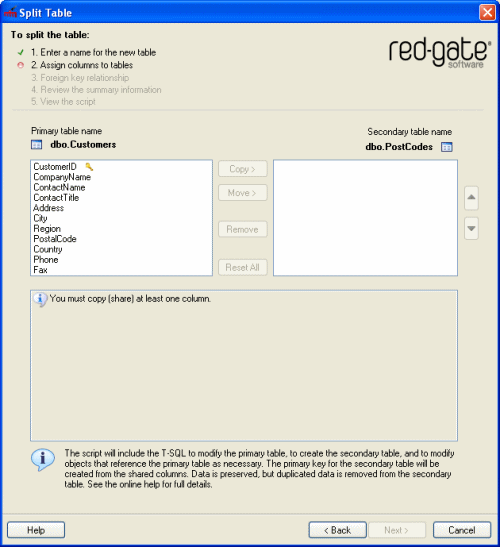
Copy or move columns from the primary table to the secondary table as required.
Note that you must copy at least one column so that the tables share a column; for more information, see Shared columns above.
If a column is shared,
 is displayed next to its name.
is displayed next to its name.- To copy a column, select the column in the primary table list and click Copy >.
- To move a column, select the column in the primary table list and click Move >.
You cannot move primary key columns from the primary table. However, you can copy these columns if required.
from the primary table. However, you can copy these columns if required. To remove a column from the secondary table, select the column and click Remove.
For example, you may want to do this if you have moved or copied a column in error.
Columns that were moved to the secondary table are moved back to the primary table; you cannot remove a column from both tables.Note that if you move a column to the secondary table and subsequently remove it, it is added to the end of the primary table's list of columns. However, when the tables are split, the columns in the primary table will not be reordered; they will remain in the original order.
- To remove all of the columns from the secondary table, click Reset All.
You can select multiple columns to move, copy, or remove by using Ctrl and Shift in the usual way. However, if any columns in your selection cannot be moved, copied, or removed the relevant buttons are not available. For example, you cannot copy a column that has already been copied. The lower section of the dialog box displays messages or warnings about your column selection.
- Reorder the columns in the secondary table as required using the
 and
and  buttons.
buttons.
You can reorder multiple columns at the same time.Note that reordering the columns will affect the order of the primary key columns on the secondary table. - Click Next.
SQL Refactor displays the options for creating the foreign key: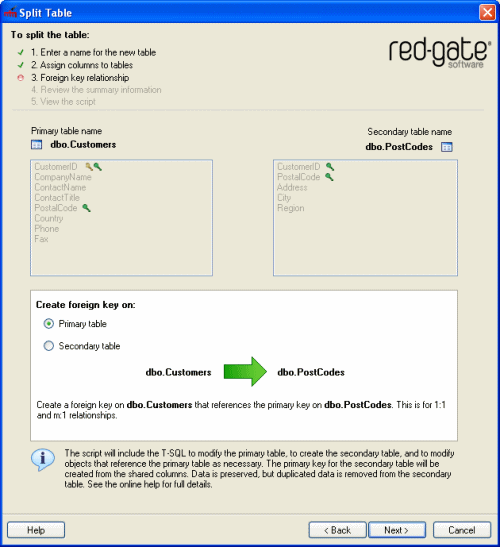
By default, the foreign key is created on the primary table, and it references the primary key on the secondary table. This is for 1:1 or m:1 relationships.
If you have copied all the primary key columns from the primary table to the secondary table, you can choose to create the foreign key on the secondary table, which will reference the primary key on the primary table. This is for 1:1 or 1:n relationships. - Click Next.
SQL Refactor generates the script and displays summary information: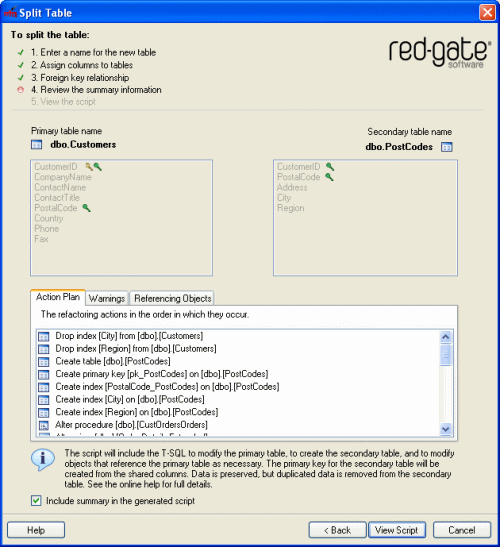
Action Plan is a summary of the actions that the script will perform in the order in which they will occur.
Warnings displays information that you should consider prior to running the script, and reasons the script may fail.
The warnings are graded according to the severity.
Referencing Objects lists the objects that will be modified by the script because they reference the table that is being split.
The action plan and warnings are included in the generated script, below the header. If you would prefer not to include this information in the script, clear the Include summary in the generated script check box. - Click View Script.
The Split Table dialog box is closed, and the SQL script to split the table and modify the referencing objects is displayed in the SQL Server Management Studio query editor.
The Split Table script
When you run the script to split a table the secondary table is created and populated with the data. The primary table, and referencing objects are modified. Details are provided below.
Primary keys
- The primary key in the primary table is unchanged.
- A primary key for the secondary table is created based on the shared columns. SQL Refactor generates a name for the primary key on the secondary table automatically.
- The primary key columns cannot contain null values. Therefore, if any of the columns that you choose to share allow null values, a warning is displayed. When the script is run, these columns will be modified to disallow nulls. If any of the data in the shared columns contains null values, the script will fail when it is run.
If you copy the primary key columns from the primary table to the secondary table, the primary key itself is not copied; a new primary key is always created on the secondary table. Similarly, any options set on the primary table's primary key (using the WITH clause, such as clustering) are not copied.
Foreign keys
By default, a foreign key is created on the primary table to reference the shared columns in the secondary table (which are used as the secondary table's primary key). SQL Refactor generates a name for the foreign key automatically.
If you chose to create the foreign key on the secondary table, SQL Refactor creates a foreign key on the secondary table to reference the primary key columns in the primary table.
Existing foreign keys that reference other tables:
- on columns in only the primary table, are preserved on the primary table
- on columns in only the secondary table, are created on the secondary table
- on columns that are shared, are preserved on the primary table and duplicated on the secondary table
- on columns in both tables that are not shared, are deleted
Permissions
Table-level permissions on the primary table are duplicated on the secondary table.
Column-level permissions:
- on columns in only the primary table, are preserved on the primary table
- on columns in only the secondary table, are created on the secondary table
- on shared columns, are preserved on the primary table and duplicated on the secondary table
Indexes
Indexes that reference:
- columns in only the primary table, are preserved on the primary table
- columns in only the secondary table, are created on the secondary table
- shared columns, are preserved on the primary table and duplicated on the secondary table
- columns from both tables that are not shared, are droppedNote that clustered indexes are created as nonclustered indexes on the secondary table. This is because the primary key on the secondary table is clustered to improve access speed when the tables are joined in queries (for more information, see Referencing objects above).
Constraints
Table-level constraints:
- that reference columns in only the primary table, are preserved on the primary table
- that reference columns in only the secondary table, are created on the secondary table
- that reference shared columns, are preserved on the primary table and duplicated on the secondary table
- that reference columns from both tables that are not shared, are droppedColumn-level constraints:
- on columns in only the primary table, are preserved on the primary table
- on columns in only the secondary table, are created on the secondary table
- on shared columns, are preserved on the primary table and duplicated on the secondary table
Note thatDEFAULTconstraints are renamed when they are created on the secondary table; the name of the secondary table is appended to the original constraint name. For example, aDEFAULTconstraint called ConstraintA that is created on a secondary table called TableB is created as ConstraintA_TableB.
Extended properties
Table-level extended properties are preserved on the primary table and duplicated on the secondary table.
Extended properties on level 2 objects (columns, constraints, triggers, and indexes):
- on objects in only the primary table, are preserved on the primary table
- on objects in only the secondary table, are created on the secondary table
- on shared objects, are preserved on the primary table and duplicated on the secondary table
- on objects from both tables that are not shared, are dropped (because the objects are dropped)
Filegroups
If the primary table was created on a filegroup, the secondary table is created on the same filegroup.
Partition schemes
If the primary table has been partitioned over a column, and that column stays in the primary table following the split, the primary table remains partitioned.
If the column over which the table is partitioned is moved to the secondary table, a warning is displayed and SQL Refactor does not allow you to generate the script.
Full-text indexes
If a full-text index exists on a column that is moved to the secondary table, the full-text index is added to the column in the secondary table.
However, note that full-text indexing cannot be added to a column from within a transaction. Therefore, if the script fails, SQL Refactor will not be able to roll back the script, and your database will be in an undetermined state. If you choose to move a column that has a full-text index, SQL Refactor displays a warning.
Referencing objects
If you have only copied columns from the primary table to the secondary table, referencing objects are not modified.
If you have moved any columns from the primary table to the secondary table, referencing objects are modified as follows.
For the object types listed below, objects that referenced the primary table before it was split are modified so that they reference both tables.
- functions
- stored procedures
- views
- DML triggers
- DDL triggers
The following modifications are made toSELECTstatements:- the table reference is replaced with a
JOINsubquery that joins the primary and secondary tables based on the shared columns - an alias is created for the
JOINsubquery - the
SELECTcolumn list and the following clauses are modified to reference the appropriate columns WHEREGROUP BYORDER BYHAVINGSELECT *clauses are expanded
- the table reference is replaced with a
- wherever possible, fully-qualified names are used
- table hints are preserved for the primary table and duplicated for the secondary table
- table samples are removed
The following modifications are made toINSERT,UPDATE, andDELETEstatements:INSERTstatements are split into two: one for the primary table, and one for the secondary table- the column list and
WHEREclause are modified to reference the appropriate columns for statements that include a
FROMclause, the table reference is replaced with aJOINstatement that joins the primary and secondary tables based on the shared columnsThe generated script for
INSERT,UPDATE, andDELETEstatements may not precisely reflect your intentions for the data, particularly for complex requirements. Therefore, you should review these statements in detail before you run the script.- Foreign keys that reference the primary key on the primary table are not changed.
All DML triggers that accessed columns on the primary table before the split are dropped.
Script failure or cancellation
If a script fails, or if it is cancelled, in most circumstances changes are rolled back. SQL Refactor uses transactions to do this.
However, there are some circumstances in which this is not possible, for example if full-text indexes are to be added to the secondary table. In these cases, SQL Refactor rolls back all the changes that it can. Your database will be in an undetermined state.
SQL Refactor always warns you if it will be unable to roll back changes.
This documentation contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved




