The New Substitution Rule Form
Published 23 March 2018
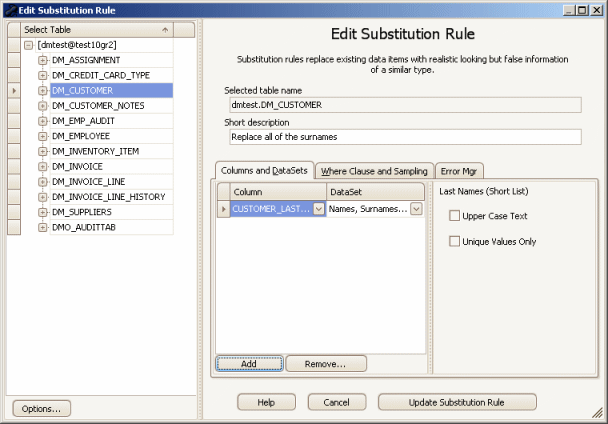
The Data Masker Create/Edit Substitution Rule Form
This form is used to create and edit Data Masker Substitution rules. Substitution rules are designed to replace data in a table column with realistic looking but random non-meaningful data. The title text and button label on the form will change as is appropriate to the create or edit mode. In the example screen shot above, the form is editing an existing Substitution rule.
A Substitution rule is configured with the target table and column names which will receive the data. The choice of the replacement data used by the Substitution rule is configurable by associating datasets with the specified table columns. Datasets for just about every purpose are included with the Data Masker software and you can make up your own if you need to do so. The choice of dataset used for a particular column is entirely up to the implementer of the Substitution rule.
Configuring the target table and column is a straightforward process. Use the mouse to select the table from the Table tab. The choice of available tables is entirely determined by the Rule Controller with which the Substitution rule is associated. Only tables from within the schema for which the Rule Controller is configured will be visible. If you do not see the tables you require, the schema structure can be refreshed using the Refresh Schema and Indexes button on Options tab of the edit Rule Controller form.
Once the table has been selected, the Column and Datasets panel will become active. Choose the table columns from the left hand section and configure the dataset for that column in the right hand section. The columns available for selection will be those of the previously selected table.
Datasets provide the required substitution values for Substitution rules. The dataset associated with a rule indicates which type of data will be substituted into the specified table and column. In the example above, the rule is configured to overwrite the existing values in the LAST_NAME column using values from the Names, Surnames, Random dataset which generates random realistic looking last names.
It is important to emphasize that Data Masker datasets are not just simple lists of replacement information. They provide a wide range of functionality. For example, the Null Values dataset removes data by replacing it with null values, the Text, Paragraphs of Gibberish dataset generates random collections of sentences and the Date Variance dataset can vary existing dates randomly between user defined boundaries. The Data Masker software comes equipped with datasets for just about every purpose and it is possible to create your own User Defined Datasets if you wish.
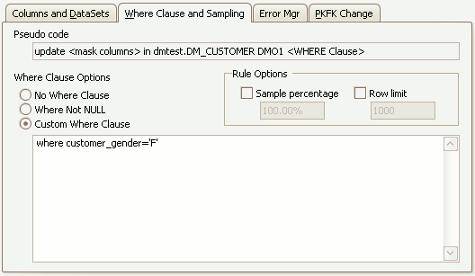
The Substitution Rule Where Clause Tab
Where Clause and sampling options are configured on the Where Clause tab and provide options which can be used when the choice of rows affected by the operation is to be based on a specific criteria. The Where Clause and Sampling help file contains a detailed discussion of these options. Please note that Substitution rules cannot use the quick NOT NULL or NOT EMPTY Where Clause configuration options if more than one column is configured in the rule.
In the above example, the Substitution rule has been applied to the FIRST_NAME column of the EMPLOYEE table and all female first names in the table are being substituted by choosing the Names, First Names, Female dataset and using a Where Clause of WHERE EMP_GENDER='F' as shown above. This would cause only the female employee records to be selected and masked. Other, separate, rules would have to be used to perform a similar substitution on the non-female entries. The temptation here is to use a Where Clause of WHERE EMP_GENDER='M' for this rule. If this is done, take care that there are no other values of EMP_GENDER than 'M' or 'F' in the table. If there are, and a rule is not specifically added to cope with this situation then the FIRST_NAME values in those rows will not be masked. This is a very important issue called a Where Clause Skip and it must always be considered when designing masking rules. There is a rule configuration technique which can be used to ensure that Where Clause Skips never happen - the Where Clause and Sampling help file contains a detailed discussion of this.
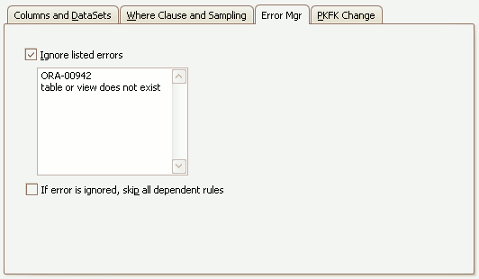
The Substitution Rule Error Manager Tab
Usually any error returned by the running masking rule will cause the running masking set to halt and no further rules will be run. Occasionally it is desirable to "handle" such errors and permit execution on other rules to continue. For example, a common reason to ignore errors are masking rules which act on a table which may not be present in the target database. In the sample above, the rule is configured to ignore any errors which contain the text ORA-00942 or table or view does not exist. Any errors which do not contain either of these items of text will still cause the masking operations to halt.
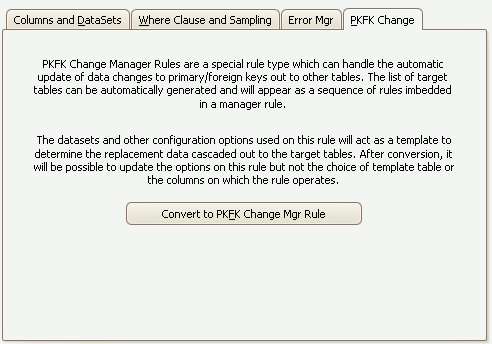
The Substitution Rule PKFK Change Tab
Sometimes it is necessary to mask the data in a primary key column of a table and to "fan-out" these changes to other tables - perhaps to ensure foreign key or logical relationships are kept intact after the masking process completes. Normally this action is performed by a Table-to-Table Synch. rule - however if multitple tables are involved, the synchronization process must necessarily ensure that the same values are updates. This can be done manually by creating a temporary correlation table which maintains the relationship between the original value and the newly masked values or, as is much easier, the Substitution rule can be converted into a PKFK Change Manager rule which automates the process. The PKFK Change Manager help file contains a detailed discussion of this process.
Existing Substitution rules can be edited by double clicking on them with the mouse. Substitution rules are created by launching the New Substitution rule form using the New Rule button located on the bottom of the Rules in Set tab.
How to Create a New Substitution Rule
This documentation contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved




