About PKFK Change Manager Rules
Published 22 March 2018
Sometimes it is necessary to anonymize the values in the columns of tables which form the join keys between those tables. This type of masking and synchronization requirement can be problematic when done manually since both the masking and synchronization operations have to be performed at the same time. If the classic Substitution and Table-to-Table sync method is used the Table-To-Table rule will fail because the join keys are no longer identical due to the masking operations of the Substitution rule. The diagram below illustrates this concept:
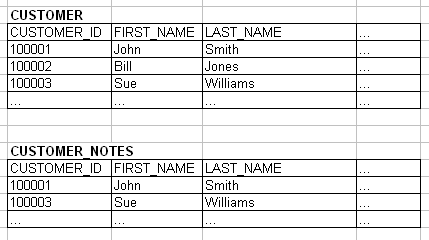
Two tables which require the CUSTOMER_ID field to be masked
The above image shows two tables in which it is necessary to mask the CUSTOMER_ID field. The CUSTOMER_ID field is a primary key in the CUSTOMER table and the child in a foreign key relationship in the CUSTOMER_NOTES table.
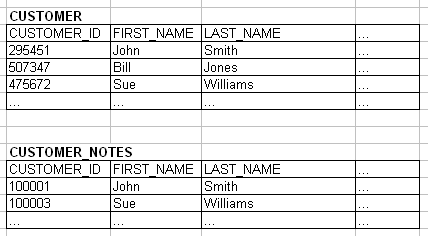
After substitution the synchronization cannot happen
After a simple substitution operation the changes to the CUSTOMER_ID field in the CUSTOMER table cannot be synchronized to the column in the CUSTOMER_NOTES table. The join keys have been changed and there is no longer any way to know which records in the two tables are associated with each other.

The build of a correlation table enables the masking to proceed
One way to achieve the desired result is to build a temporary table, known as a correlation table, which contains copies of the before and after values of the column to be masked. The generation the new column values takes place in the correlation table and then Table-to-Table rules can be used to fan the changes out to the targets. The synchronization can take place since the new value of each existing CUSTOMER_ID is known. Once the correlation table is built it then becomes a relatively simple procedure to examine each row in the CUSTOMER and CUSTOMER_NOTES table, lookup each CUSTOMER_ID value in the OLD_CUSTOMER_ID column, find the associated NEW_CUSTOMER_ID and perform the update. Once the operation has been performed on both tables the CUSTOMER_ID values will be both modified and synchronized even though it is a join key. At that time the temporary correlation table must be dropped for security reasons since it forms a lookup mechanism between the new values and the old values.
The above description forms the basic requirements needed to mask data in columns which form a join key between multiple tables. There are several other complexities which need to be considered.
- The values in the NEW_CUSTOMER_ID must be unique. If they are not then the update will fail if the target columns in the target tables (CUSTOMER and CUSTOMER_NOTES) have primary or unique keys.
- The values in the NEW_CUSTOMER_ID must be distinct from the values in the OLD_CUSTOMER_ID column. If they are not then it is possible during the update that a column will be update with a NEW value which still exists as an OLD value. In other words, if the NEW values form a distinct set but some match the values in the OLD column then during the process of the update primary or unique errors might happen as there are temporarily duplicate values in the updated column.
- It is necessary to build the OLD column with a complete distinct set of CUSTOMER_ID values from both tables. Usually this is done by inserting a complete set of CUSTOMER_ID's selected from the larger table (in this case CUSTOMER) and then inserting any CUSTOMER_ID values from the CUSTOMER_NOTES table which are not present in the OLD column of the correlation table. If CUSTOMER_ID values are present in the CUSTOMER_NOTES table which are not in the OLD column of the correlation table then those values will not get masked.
- Usually it is required that the target columns must have indexes and those indexes must remain in place during the update. Each value in the correlation tables OLD column will need to be looked up in the target table so the NEW value can be updated there. If those columns are not indexed then the operation will be extremely slow.
- The OLD column in the correlation table should be indexed it will be referenced continuously during the update.
- Both the correlation table and it's index should have accurate and up-to-date statistics generated for it after it is populated otherwise performance issues can arise.
- Foreign key relationships between the target tables should be disabled while the update is running. If they are not then temporarily invalid foreign key relationships will cause the rules to fail.
- All tables containing the masked key values will need to be involved in the synchronization operations. Leaving some tables with a CUSTOMER_ID unsynchronized will result in them becoming unusable.
- Once the masking has started, the temporary correlation table provides the only mechanism which can indicate which old values transform to which new values. Once the correlation table has been dropped there is no way to include a "forgotten" table in the process. It is best to ensure that you have masked all values in all tables prior to dropping the correlation table.
The above operations can be quite tricky to implement manually. The PKFK Change Manager rule is designed to automate the process. The PKFK Change Manager contains a number of sub-rules within it. These rules perform the following operations
- Create the temporary correlation table.
- Populate the tempoary correlation table with a unique set of values from all target tables.
- Perform the masking operation on the NEW column of the correlation table.
- Disable the foreign keys on the target tables.
- Perform a table-to-table synchronization operation on the target tables using the OLD values in the correlation table to find the correct rows to update with the NEW values.
- Enable the foreign keys on the target tables.
Unlike all other rules in the Data Masker software, the PKFK Change Manager rule is created by converting an existing rule. The creation of a PKFK Change Manager rule is performed as follows.
- Create a Substitution or Row-Internal Synchronization rule on the table and column(s) which you wish to mask. Use the Convert to PKFK Change Manager Rule button on the PKFK Change Tab of those rules to convert the existing rule into a PKFK Change Manager rule.
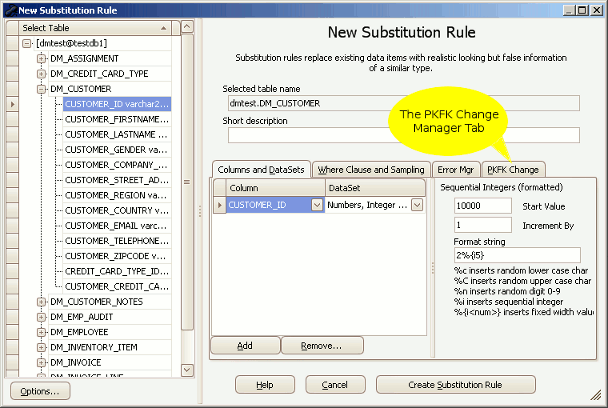
The location of the PKFK tab on a Substitution rule
- Once converted, the new PKFK Change Manager rule will be visible in the rule display with the same rule number.
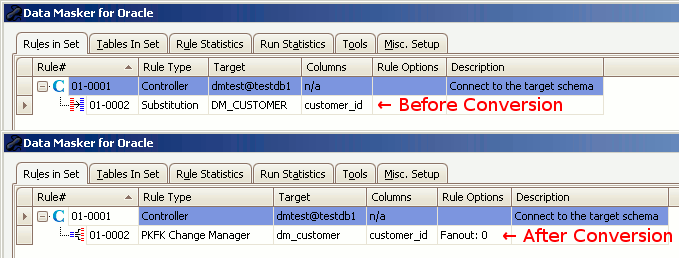
The Substitution rule has changed to a PKFK Change Manager rule
- The new PKFK Change Manager rule can be opened and the Edit PKFK Change Manager rule form will be visible.
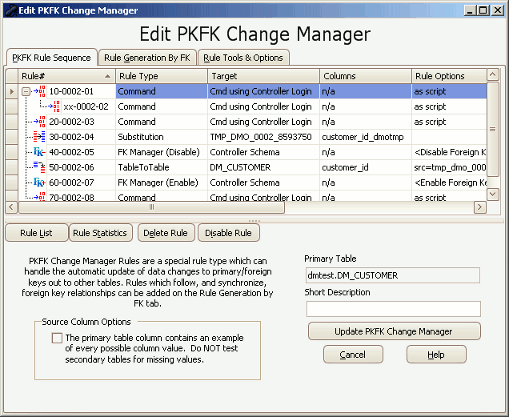
The Edit PKFK Change Manager rule form
- At this point secondary fan out tables (those that will also be synchronized) can be included in the rule using the tools on the Rule Generation by FK and Tools and Options tabs.
The PFKF Change Manager rule can be enabled, disabled or run manually like any other rule. The rules it contains will execute in parallel according to their own internal rule blocks. The Edit PKFK Change Manager rule form has more details on the configuration of PKFK Change manager rules.
This documentation contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved




