Shadow Database or Shadow Schema
Published 11 October 2021
The shadow database is a separate database that is only needed in your development environment. It can start as an empty database. It will be small because it will only contain the schema objects. It won't contain any transactional data.
When you go to the Generate migrations tab in Flyway Desktop, we run the migration scripts in the project against the shadow database. Then, we use our comparison technology to compare the schema model folder to the shadow database. This allows us to show what changes have been made to your development database that have been captured in the schema model folder that have not been imported into a migration script in the project yet. These are the changes that need to be scripted for deployment.
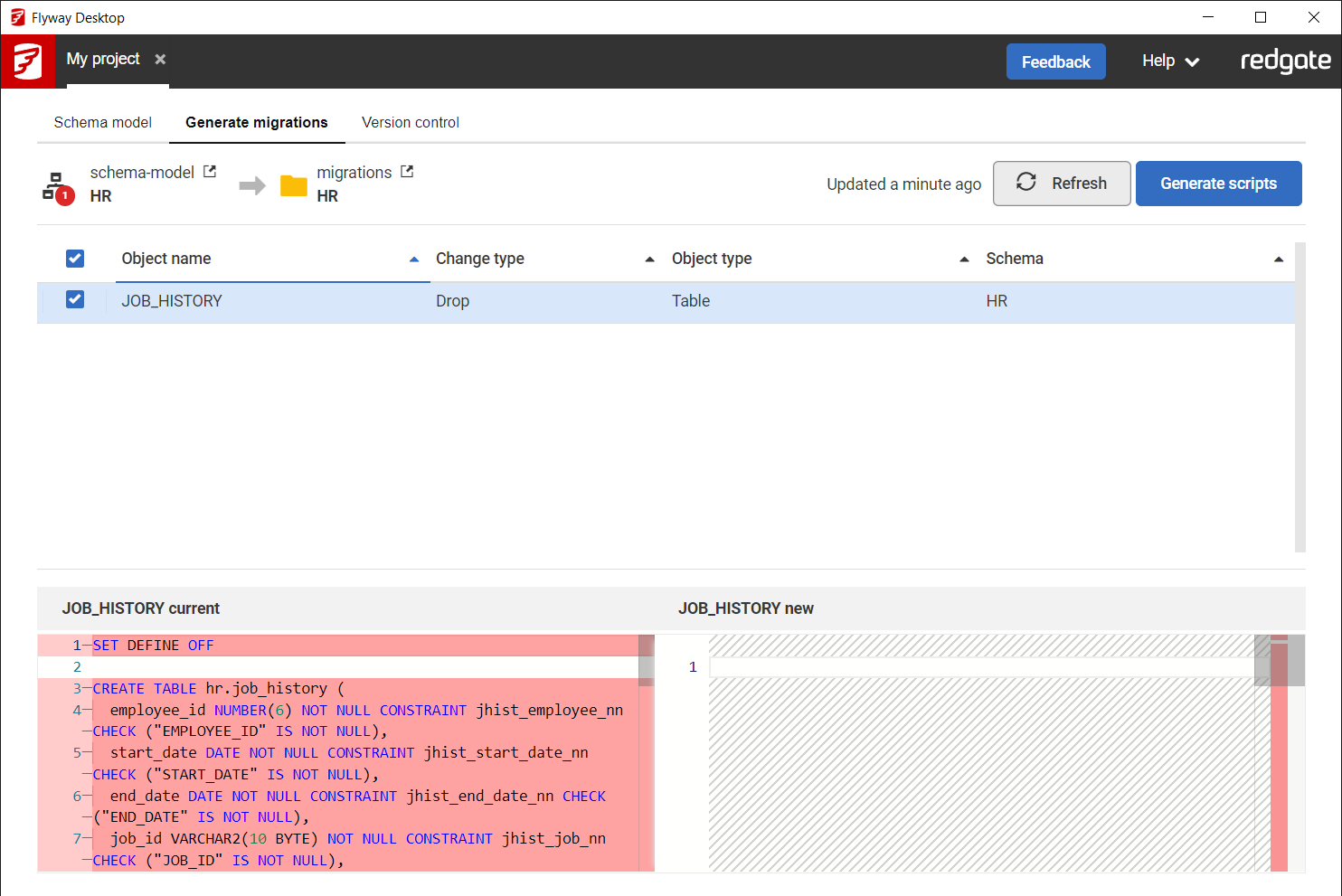
Because we run all the migration scripts in your project on the shadow database/schema, this also helps you shift-left and identify any problems in your migration scripts as early as possible during development.
You should never have to make changes to your shadow database/schema. You also don't need to baseline your shadow database/schema. It will be cleaned (meaning all objects will be dropped) as required when you visit the Generate migrations tab, so make sure that you are not using a database/schema that contains important data.
When setting the shadow database/schema connection, ensure it isn't an important database/schema as this may be cleaned and rebuilt when generating migration scripts in Flyway Desktop. There is a checkbox that you must explicitly click to confirm that all the data and schema in the shadow database can be erased.
The Shadow Database/Schema only gets updated with the migration scripts in your project, so the size should be small since there shouldn't be any transactional data in this database. It will just contain the schema objects and reference data from your migration scripts and any data updates ran on these. If you have a transactional data update in a migration script in your project, it won't do anything on the shadow since the transactional tables are empty.
Configuring the shadow database
If no shadow database is configured, you will be prompted to configure it from the GUI when navigating to the Generate Migrations tab.
Once it is configured, the connection details can be altered via the Settings Cog, which will display the following options.

It is best if there is one shadow database per developer per project. This improves performance because it won't have to be cleaned as often.
It is best to put the shadow database on the same server as your development database. This could be a shared centralized development environment or if you're using a local instance to develop against, then the shadow can go there. This is especially important if there are any cross-database dependencies because the shadow will need to reference these in order for the scripts not to fail when they are executed.
Some users like to name their shadows as z_<DbName>_shadow_<DevName>. This is especially true on a shared centralized development server so all these databases appear at the end of the list. If you are using SQL Server and SSMS, you can filter out and databases whose name contain "_shadow" from the Object Explorer view.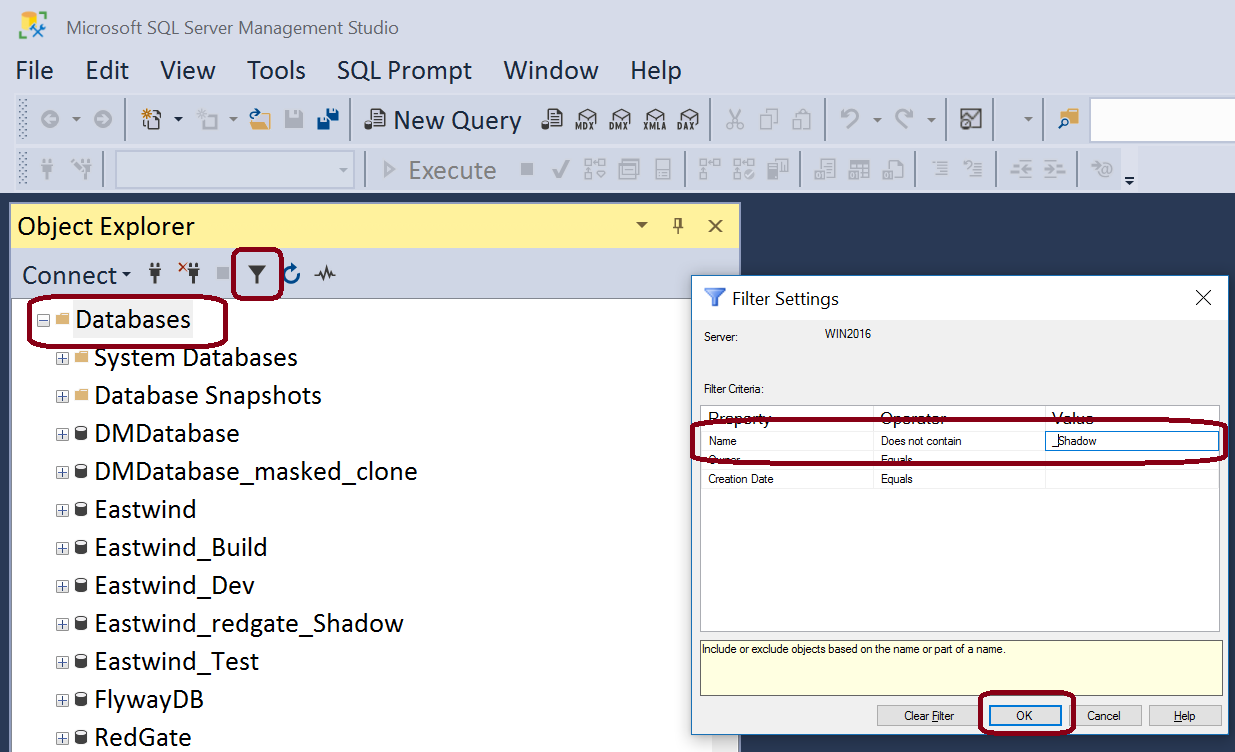
Provisioning and reprovisioning
When connecting to an existing shadow database, the state of the shadow database may be reset by cleaning it. This resets the shadow database to an empty state.
Instead it is possible to provision a shadow database at a given state, for example using Redgate Clone or Docker.
If the provisioned database is empty, then the behaviour is equivalent. Whenever the shadow state is stale, it is reprovisioned using the appropriate method instead of being cleaned. This is potentially more robust with complex databases.
If the provisioned database is populated and matches the baseline state of your production environment, then this state can be treated as the baseline and no baseline migration script is needed. This solves a lot of issues baselining with large or complex databases. For more information see our Clones as baselines documentation.
More database specific information:
SQL Server
For SQL Server, there are a few options to use for the Shadow Database:
- A database on LocalDB
- A database on SQL Server Express Edition
- Another database on the same instance as your development database (or another environment, but we usually see development)
- A database on another instance
- Redgate Clone
Spin up terabyte-scale databases in just a few seconds and only use MBs of disk space. This is ideal if your database has a lot of objects or the baseline script takes a while to run. - Containers
If you're familiar with docker/containers, you could spin up an SQL Server database in a container to use for the shadow. Since there is no transactional data, no persistence is required and therefore a transient container should just work.
Note:
- If you are using different files and filegroups, make sure these are setup on the shadow database. Or, you can add these into the top of the generated baseline script, so that if the baseline script is ran on a new database, then the filegroups/files will be created.
- If you have any x-database dependencies or linked servers, these will need to be available to the shadow
SQL Server LocalDB
To use localDB, you will need to use a fork of the jdbc driver. This is because LocalDB uses named pipes for connections, and the official Microsoft SQL Server JDBC driver doesn't support LocalDB named pipes - see this Github issue.
You will need to use the jTds driver:
- You can download the driver here. After extracting it, you will need to move jtds.1.3.3.jar to <install_dir>/flyway/drivers, and delete the existing jtds-1.3.1.jar.
- Selected jTds using the driver dropdown in the connection dialog
There are a couple of important caveats to note:
- The jTDS driver only supports named pipes when connecting to LocalDB - you can read more about this limitation in this GitHub issue. This means that the instance name for your LocalDB will change every time the service is restarted, which would mean you have to edit your connection string every time too. To avoid this, Flyway Desktop supports deferred resolution of the instance by setting the instance to
${localdb.pipeName}in the JDBC URL. This is controlled by the "local db" checkbox in the UI, which is checked by default when selecting jTds from the driver dropdown. Note thatnamedPipealso needs to be set to true in the JDBC URL for this to work (again on by default). The default localdb instance name (for entering into the instance name field) is "MSSQLLocalDB". You can read more about localdb resolution here. - With jTds SQL Server authentication works out of the box, but for Windows Authentication to work an additional dll, ntlmauth.dll, needs to be downloaded, as well as setting the
domainproperty in the JDBC URL. The ntlmauth.dll needs to be added to <install_dir>/flyway/native. It can be downloaded here. - jTds does not support using
localhostas a server name. Use.instead.
Oracle
Setting up a shadow database for Oracle
For Oracle there are a few options to use for the Shadow Database:
- Pluggable Database
If you are using Oracle 12c and above, the easiest way might be to use another pluggable database (pdb) on your development instance. - Oracle Express Edition (XE)
Oracle XE is a free version of Oracle that can be used for development purposes. There are some size restrictions, but because the shadow database does not contain any transactional data, this should be ok. Make sure you connect to the pluggable database (default service is XEPDB1) and not the container database (default service is XE). Read more about this in the Oracle docs.- If you get an "Error running flyway clean", this is usually the problem. Make sure you are using the XEPDB1 service and not XE.
- Redgate Clone
Spin up terabyte-scale databases in just a few seconds and only use MBs of disk space. This is ideal if your database has a lot of objects or the baseline script takes a while to run. - Containers
If you're familiar with docker/containers, you could spin up an Oracle database in a container to use for the shadow. Since there is no transactional data, no persistence is required and therefore a transient container should just work. - Create another Oracle instance for this.
- A separate schema within the same Oracle database (see below)
Setting up a shadow schema for Oracle
For Oracle projects that are tracking changes to a single schema, it is possible to use a Shadow Schema rather than a separate shadow database. If your project contains multiple schemas then a separate shadow database is required so we maintain the schema name in object identifiers.
Specify a different schema when setting up the shadow database, either when prompted on the generate migrations screen or via the settings cog and save the changes.

When using a shadow schema for Oracle, you must also set the ExcludeTargetSchemaName comparison option. This can be configured in the comparison options on the Schema Model tab. This will ensure migration scripts are generated without explicit schema references, so they can be deployed to the Shadow Schema.
There are a couple of caveats when writing migration scripts in this single-schema mode:
- Any references to objects in the managed schema must not be schema-qualified. Since the migration scripts will run against different schemas with different names, managed objects must always be created in the current default schema.
- Any references to objects in other schemas must be schema-qualified. You'll be responsible for making sure any dependencies of the managed schema are present in the database as appropriate.
For example:
CREATE TABLE log ( message VARCHAR2(50), timestamp INTEGER ); -- this object references log in the same schema, so log must not be schema-qualified CREATE OR REPLACE TRIGGER SetTimestampForLog BEFORE INSERT ON log FOR EACH ROW DECLARE v_today DATE; BEGIN SELECT CURRENT_DATE INTO v_today FROM DUAL; -- date2epoch is in a different schema, so must be schema-qualified :new.timestamp := util.date2epoch(v_today); END;
MySQL
Setting up a shadow instance for MySQL
For MySQL, there are a few options to use for the Shadow Database:
- Containers: If you're familiar with docker/containers, you could spin up a MySQL instance in a container to use for the shadow. Since there is no transactional data, no persistence is required and therefore a transient container should just work. Example command:
docker run -d -e MYSQL_ROOT_PASSWORD=password -p 3307:3306 mysql - Creating another MySQL instance on the same machine: One option is to run another copy of MySQL and specify something like
mysqld --port=3307on the commandline to make the second copy of MySQL listen on a different port. - Redgate Clone can spin up terabyte-scale databases in just a few seconds and only use MBs of disk space. This is ideal if your database has a lot of objects or the baseline script takes a while to run.
Setting up a shadow schema for MySQL
For MySQL projects that are tracking changes to only a single schema (aka "database"), it is possible to use a Shadow Schema rather than a whole separate instance. If your project contains multiple schemas ("databases") then a separate instance is required since each object will need to be created in the specific named database.
Specify a different schema when setting up the shadow database, either when prompted on the generate migrations screen or via the settings cog and save the changes.
There are a couple of caveats when writing migration scripts in this single-schema mode:
- Any references to objects in the managed schema must not be schema-qualified. After setting up a shadow schema as described above, newly generated migration scripts will not contain schema names in object identifiers and SQL object bodies. However, other places that object names might occur (such as in string literals) will not be processed.
- Any references to objects in other schemas must be schema-qualified. You'll be responsible for making sure any dependencies of the managed schema are present in the database as appropriate.




