Data storage issues
Published 22 December 2021
This page lists known problems, possible workarounds and debugging techniques affecting our Data storage.
Contents
MODIFY FILE encountered operating system error 31
The most common reason why the data image creation would fail with the above error message is the lack of the attached storage disk.
To understand the state & usage of the attached disk, we recommend checking-out Disk Usage (storage) dashboard.
Unable to recover after host machine was rebooted/restarted
In some scenarios a planned or unattended reboot of the primary host machine can lead to issues.
Unable to create new data-containers, or use the existing once, due to deployment/rook-ceph-osd-0 being unavailable
Problem
The most common issue with reboots is related to the Linux Kernel itself and the random reallocation of attached disks.
In short, the Linux Kernel does not ensure that the disks would get attached to exactly the same device name (e.g. sdb) & number as before after the reboot. If you wish to read more in-depth explanation, see Troubleshoot Linux VM device name changes.
Example
Let's say you have the Ubuntu Virtual Machine with 6 disks (1 OS disk, and 5 x 256GB disks attached).
You can SSH into the host machine and find the names of the disks by executing lsblk -e7 command, which would output something similar to (sda is the system disk):
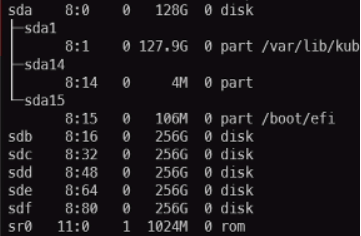
Then, in the Storage Settings (Embedded) under the Name pattern you would type in sd[b-z] which would pick up all the disks from sdb - sdz device names inclusive (see example below).
That means the OS disk (sda) would be ignored, and not used by Kubernetes cluster.
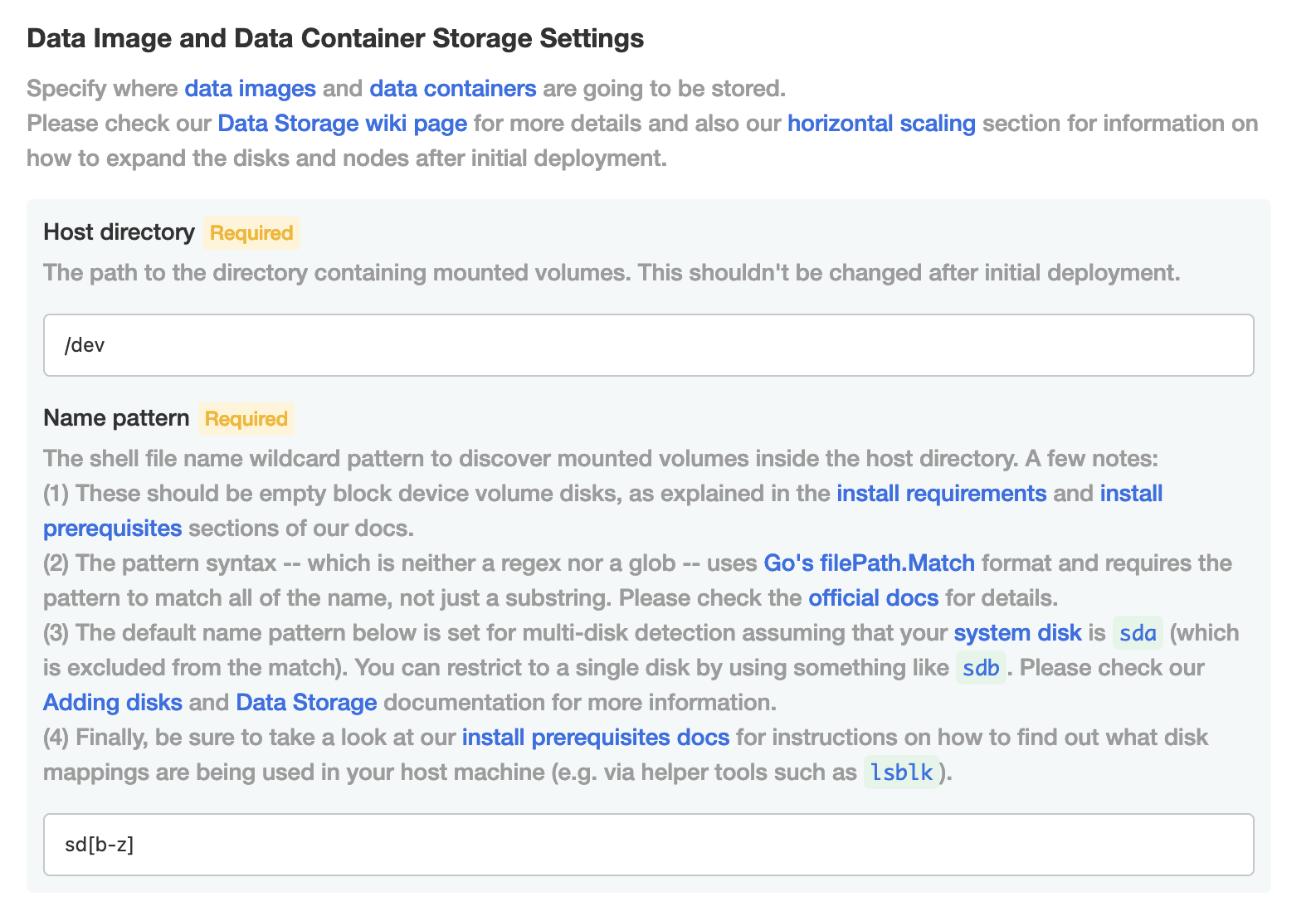
However, after you reboot the system, the disks are not guaranteed to have exactly the same device name as only disk uuids are guaranteed (not yet supported in Redgate Clone) to remain the same after a restart.
| Before Reboot | After Reboot |
|---|---|
sda → 128GB OS Disk sdb → 256GB attached disk sdc → 256GB attached disk sdd → 256GB attached disk sde → 256GB attached disk sdf → 256GB attached disk | sda → 256GB attached disk sdb → 256GB attached disk sdc → 256GB attached disk sdd → 256GB attached disk sde → 256GB attached disk sdf → 128GB OS Disk |
|
As a result, this means that the Storage Settings (Embedded) configuration you used before ( sd[b-z] ) is no longer valid, because it would pick up the sdf disk, which is the OS disk, and wouldn't pick up sda , which is one of the extra attached disks (which may have existing data image and data container data).
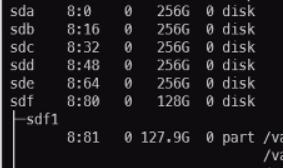 The end result is a confusion in our storage solution that leads to an invalid product state (that would then require a hack such as manual tweaking to the Storage Settings (Embedded) to pick up the new mappings – see workarounds below for more details).
The end result is a confusion in our storage solution that leads to an invalid product state (that would then require a hack such as manual tweaking to the Storage Settings (Embedded) to pick up the new mappings – see workarounds below for more details).
Workarounds
Linux Virtual Machines in Azure
If you are using Linux Virtual Machines in Azure, then we highly recommend using LUNS, instead of disk names. Please follow official Azure guide on how to identify the symbolic links (LUNS) and then apply them in the Storage Settings (Embedded)
Udev rules
Linux has a way to create rules to map various components. This is known as udev rules. Please consult the udev documentation to learn how to use them and create a mapping for your disk. Please be aware that the ceph disk is not formatted by linux and therefore, you will not be able to find a uuid. You must find another attribute to map with. These attributes can be seen with this command: udevadm info -name /dev/sda
https://wiki.archlinux.org/title/Udev
VMWare
There are mappings that can be done with VMWare. If you decide to do your own udev rules, make sure VMWare doesnt superseed those rules.
Otherwise
For any other case, please reboot your cluster until you get into the right (initial) state or update the Storage Settings (Embedded) to match the new mappings (and don't forget to deploy the new configuration update afterwards in the dashboard's UI).
This documentation contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved




