Handling Schema Drift
Published 10 February 2016
What is 'Schema Drift'?
Schema Drift occurs when a target database deviates from the baseline that was used to originally deploy it. For instance, the SQL Change Automation project within your repository’s trunk can be considered a baseline.
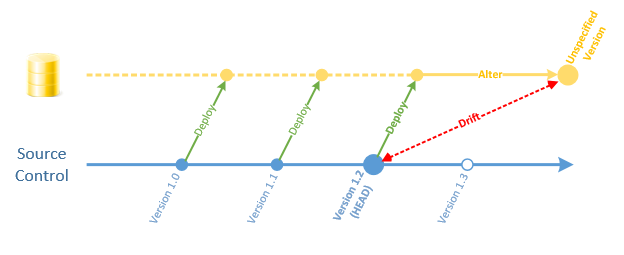
In this example, modifications were made to the live database after Version 1.2 was released. This effectively created a new version of the schema outside of source control.
This could cause a problem when Version 1.3 is deployed, because the deployment package will expect the target database to be in the state of Version 1.2.
How it works
When the New-DatabaseReleaseArtifact cmdlet is used, a comparison is performed between the schema of the target database and the source control baseline. This process produces the following artifacts:
Reports\Drift.html
A report containing details of objects that have drifted from the source control baselineDriftRevertScript.sql
If executed, the script will re-synchronize the target db with source control, undoing changes made directly to the database
To inspect these artifacts, and others related to the release process, use the Export-DatabaseReleaseArtifact cmdlet to output the artifacts to a folder.
Set up
As the generation of drift-related artifacts happens alongside the process for producing the release artifacts, you should start seeing the artifacts being generated once the steps outlined in Automating Deployments have been followed. The one exception to this is when performing the initial deployment to a given server/database: given that the drift detection process relies on a snapshot of the source control baseline inserted into your database by the Use-DatabaseReleaseArtifact cmdlet, the drift artifacts will only be produced during subsequent runs of the New-DatabaseReleaseArtifact cmdlet.
Viewing the drift report
In the following example, an index has been added to an existing table in the live production database.
USE [adventureworks]
CREATE NONCLUSTERED INDEX IX_SalesLTAddress_ModifiedDate ON SalesLT.[Address]
( ModifiedDate DESC ) ON [PRIMARY]
GOWhen generating the database release artifacts, SQL Change Automation will detect that the deployment target database is different to the version that was previously deployed. A drift report will be generated which shows the differences detected. Download this report (Reports\Drift.html).
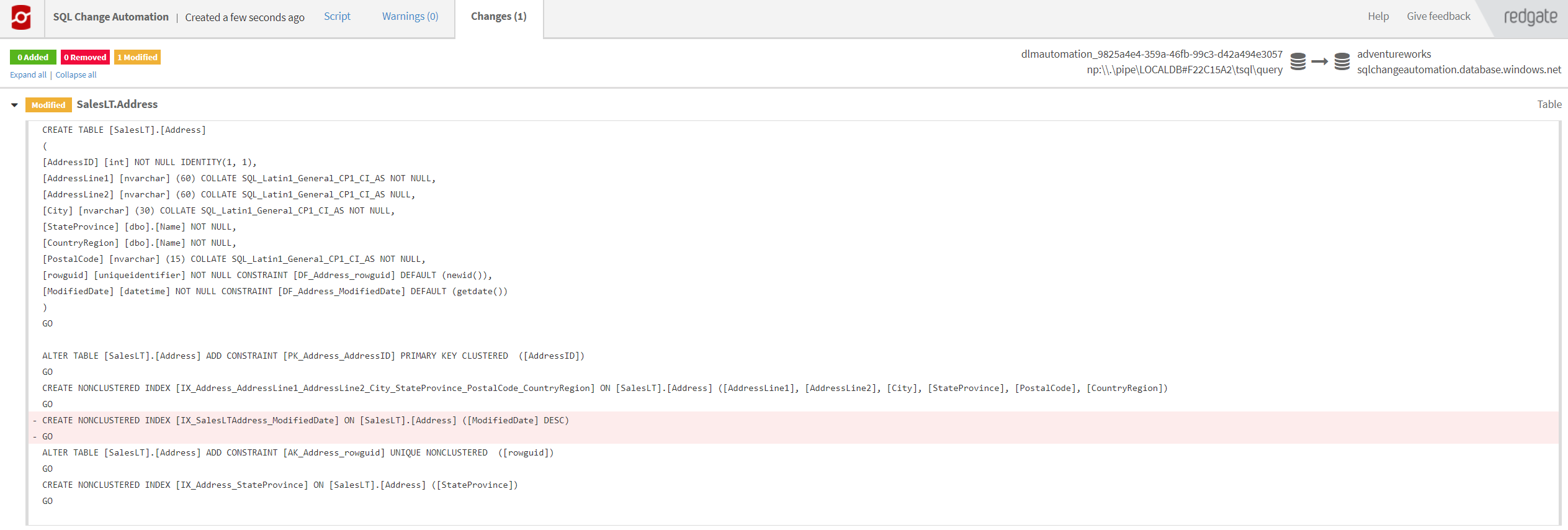
Note that this report is distinct from the changes report (Reports\Changes.html), which shows changes that originate from source control only.
Resolving instances of drift
Given that case-by-case decisions may need to made about what to do with each affected object, whether to revert the object change from the target environment or to import them back into source control, resolving drift is a task that currently must be handled manually. However, the drift detection process does provide a script which can be used as a starting point for resolving the drift in the target environment.
Reverting drift from the database
To allow the deployment target back in line with the previously deployed version in source control, SQL Change Automation generates (but does not run) a drift revert script. In this case, the script reflects what is displayed in the report: that the index object was not found in source control, therefore it should be removed from the target database. Download this drift revert script (DriftRevertScript.sql).
--------------------------------------- BEGIN DRIFT CORRECTION (GENERATED) SCRIPT ----------------------------------------
GO
PRINT N'Dropping index [IX_SalesLTAddress_ModifiedDate] from [SalesLT].[Address]'
GO
DROP INDEX [IX_SalesLTAddress_ModifiedDate] ON [SalesLT].[Address]
GO
---------------------------------------- END DRIFT CORRECTION (GENERATED) SCRIPT -----------------------------------------This is the default behavior of the script. However, another option is available.
Incorporating drift into the release
Instead of dropping the index, the drift can resolved by manually importing the changes into source control as a migration. During subsequent releases, the index will be propagated to any environments where it does not currently exist.
SQL Change Automation assists with this by producing a separate script that performs the opposite change of the drift revert script. This can be found within the commented-out section of the script footer:
------------------------------------------------------------------------------------------------------------------------ ------------------------------------------ NEW INCREMENTAL MIGRATION ------------------------------------------ ------------------------------------------------------------------------------------------------------------------------ -- DESCRIPTION: The following code performs the opposite of the above statements: it preserves the changes -- made to the target database instead of reverting them. -- HOW TO USE: Paste the following into a new migration to import changes. /* PRINT N'Creating index [IX_SalesLTAddress_ModifiedDate] on [SalesLT].[Address]' GO IF NOT EXISTS (SELECT 1 FROM sys.indexes WHERE name = N'IX_SalesLTAddress_ModifiedDate' AND object_id = OBJECT_ID(N'[SalesLT].[Address]')) CREATE NONCLUSTERED INDEX [IX_SalesLTAddress_ModifiedDate] ON [SalesLT].[Address] ([ModifiedDate] DESC) GO */
To incorporate the change into source control, copy and paste the section of code into a new migration within your SQL Change Automation project, commit the change back to source control and perform a new build.
When the new build is released, the changes will be included within the script that is deployed onto your development, test and production environments (TargetedDeploymentScript.sql). Once the script has been deployed to all environments, a new set of release artifacts will need to be generated to demonstrate that the drift has been resolved.
Although the drift import script contains idempotent logic, additional defensive logic may need to be authored within the new migration (e.g. a server/database name check) in order to ensure that the changes are only applied to the appropriate environments.
Configuring which objects are included in drift reporting
As a general rule, any objects that are included in your SQL Change Automation project will also be included in drift reporting. However the following type of objects are not included in the report:
- Static data
- Objects that are excluded by the project's filter rules
- Objects that exist in the target environment only, although this behavior can be overridden (see below)
Additionally, any database comparison options set within the project file will also affect the types of differences that appear in the report.
Reporting on objects that exist in the target environment only
By default, the drift report will exclude objects that exist in the target database but not in the SQL Change Automation project. This is to accommodate the scenario in which objects have been added to the target environment as part of a separate process. A common example of this is users that exist in Production but not in Test. Another is when objects are added for purely operational reasons, such as stored procedures used by the DBA to perform scheduled maintenance on the database.
To override this behavior and have all database objects included in drift reporting, edit your project file, add the following under the <Project> element and check the file back into source control:
ProjectFile.sqlproj edit
<PropertyGroup> <DriftOptionDropMissingObjects>True</DriftOptionDropMissingObjects> </PropertyGroup>
Objects such as indexes, constraints, primary/foreign keys and triggers are considered sub-objects of tables by SQL Change Automation. Therefore it is not necessary to set the above option if the parent table object itself is already in source control.
This documentation contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved




