Static Data
Published 10 February 2016
Data population strategies
If you're interested in the various techniques for seeding your database in general, see Seed Data.
One thing to consider when source-controlling your database is how to maintain static/lookup data within your project.
This can include data that is needed by the calling application to work such as zip/postal codes, country lists or even application settings.
SQL Change Automation offers two distinct ways of handling static data:
- Online method – use the SQL Data Compare engine (built into SQL Change Automation) to generate migrations containing INSERT/UPDATE/DELETE statements
This is the simplest way to edit static data. Simply flag one or more tables for data tracking, edit the data directly in the target database, and then synchronize with your SQL Change Automation project to generate a migration script. Offline method – use an open-source tool to generate re-usable MERGE statements
This method has a higher learning curve than the online method but offers more flexibility. The advantage of working offline is that you can store the data in a single file, rather than generating a new file with each change, allowing you to branch and merge the data in source control.
You can choose to use either the online or offline editing approaches above, or a combination of both, in the one SQL Change Automation project.
For example, you may use the online method on tables that contain consistent data between all environments, and use the offline method on tables where the data changes between environments.
Handling larger data sets
Editing Static Data Online
In addition to synchronizing schema and code objects, the SQL Change Automation tool-window in Visual Studio can also synchronize static data..
This allows you to edit table data in an online manner, e.g. with SQL Server Management Studio, and then import changes back into your SQL Change Automation project to generate INSERT/UPDATE/DELETE statements within a new migration.
To mark a table for data tracking:
- Open your SQL Change Automation Project in Visual Studio, and switch to the SQL Change Automation tool-window (shown below).
- Click Refresh to display the list of tables available for data tracking. Expand the Identical Objects group to locate existing tables.
- Right-click a table from the list and check Include Table data.
A notification bar should appear, indicating that a Refresh is pending. - Refresh the list of differences. This time, SQL Change Automation will perform a comparison that will include data from the specified table(s).

Primary Key requirement
In order to track the data within your tables, the table must include a primary key. If a primary key is not present in a given table, the data within the table will be ignored (not imported).
You can now preview and import data from the specified tables.
Working with larger data sets
When choosing tables to track for data changes, it is important to bear in mind that SQL Change Automation is optimized for working with smaller sets of static data (< 1MB table size). This is to ensure that your projects always build quickly, as larger datasets can produce a significant amount T-SQL code which can cause performance issues during project build/deployment.
A warning will display within the SQL Change Automation tool-window if a static data table exceeds 1MB.
For larger data sets, we recommend using the data seed method with BULK INSERT instead.
Limitations in Continuous Integration / Deployment
Please note that SQL Change Automation's static data tracking is not currently supported within the drift correction feature, so the drift report will not report on any data differences. Likewise, the deployment preview feature which shows object-level changes that are pending deployment (e.g. in Octopus / Azure DevOps), does not yet support the previewing of data changes.
Editing Static Data Offline
Editing offline means that you start by preparing a data change script before actually deploying the changes to the database.
In this example, we'll use the MERGE statement to manage the deployment of our static data. What makes MERGE so useful is not only its ability to insert, update or delete data in one succinct, atomic operation but also the fact that the statements are re-runnable. This allow for the source script to be edited and re-used for deployment to all target environments. It also gives you the ability to include SQLCMD variables in place of literal values, allowing you to centralize the deployment of configuration data.
To generate MERGE statements, we will use the sp_generate_merge stored procedure utility. The script that is generated from the utility can be pasted into a Post-Deployment script in your SQL Change Automation project, as explained below.
Limitations of the offline method
There are a few draw-backs of the offline method to consider prior to selecting this approach:
- Non-determinism of the
MERGEstatement: before actually running the deployment against your target environment, it can be difficult to know what changes will be applied (if any). Worst case scenario, you could hit one of the documented issues inMERGE - The workflow isn't necessarily the most natural way to edit data, as it requires running the utility proc and copying+pasting the output back into the original file. Editing the file directly is an alternative, but isn't the most user-friendly experience especially with large amounts of reference data
- Coordinating changes to both the schema and data within the reference table can be quite difficult, given that your schema changes will be performed in a separate part of your deployment (i.e. multi-use scripts run only after all pending migrations have been executed). For example, if you need to update an ID value in the lookup table prior to adding a foreign key to the schema, then that update would need to be hand-coded and included in your project separately to your MERGE statement.
If you foresee that these limitations may be problematic for your deployments, then it may be worth considering the online approach to source controlling your static data instead.
Installing the "sp_generate_merge" proc
Download the sp_generate_merge" stored procedure from GitHub. Install it by simply running the script on your development SQL Server instance. This will install the utility as a system procedure within the [master] database so that it can be used within all of your user databases.
Open Source Project
Note that you do not need to add this script to your SQL Change Automation project, nor do you need to deploy the stored procedure to any server other than your Development environment.
Generating a MERGE statement from existing data
In this step we'll generate a single MERGE statement containing all the records from the "Sales" table.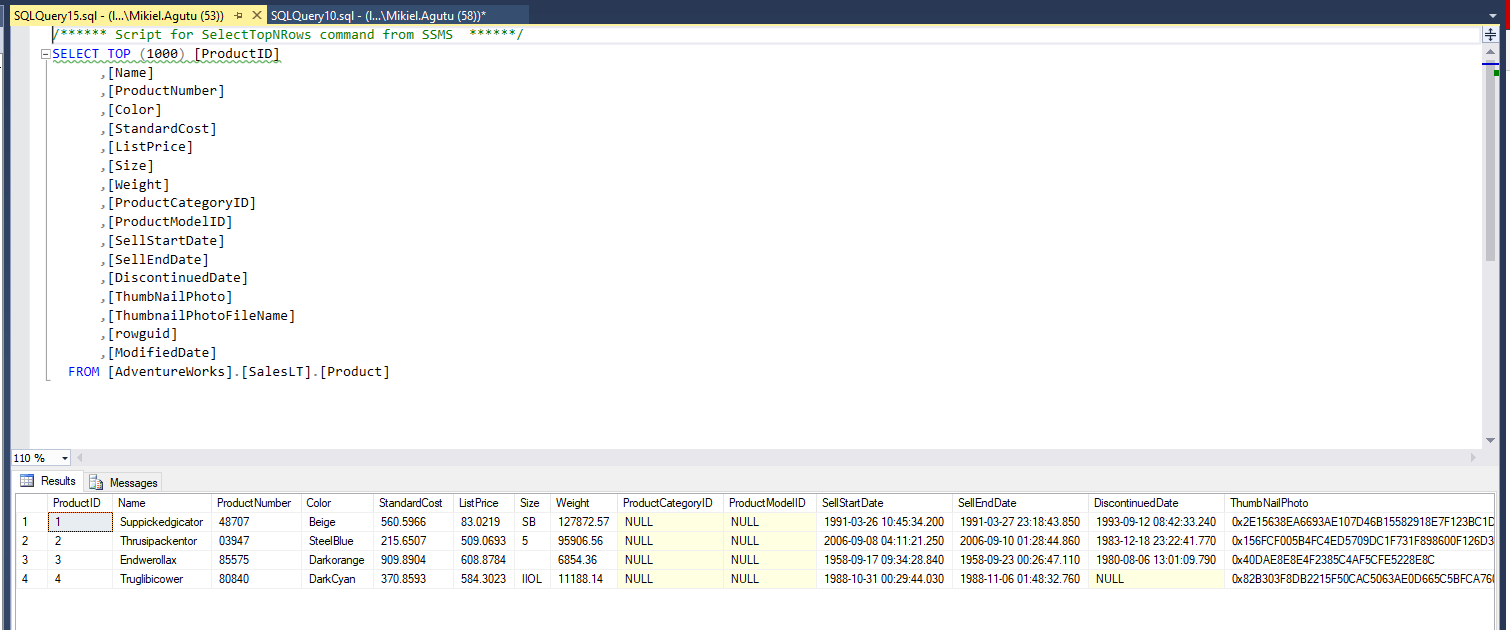
Firstly, open SQL Server Management Studio and connect to your development database server and ensure that your SQL client is configured to send results to grid, rather than text.
Execute the stored procedure, providing the source table name as a parameter. If your table is in a non-default schema, be sure to supply the @schema parameter with its name.
For example:
EXEC AdventureWorks.dbo.sp_generate_merge 'Product', @schema='SalesLT'
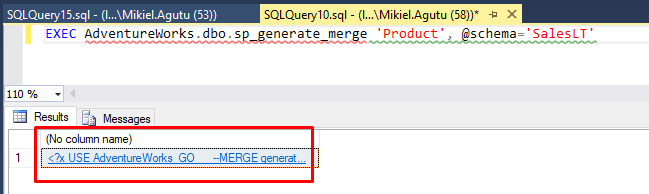
Click the hyperlink in the result set to open up the Xml fragment in a new document window.
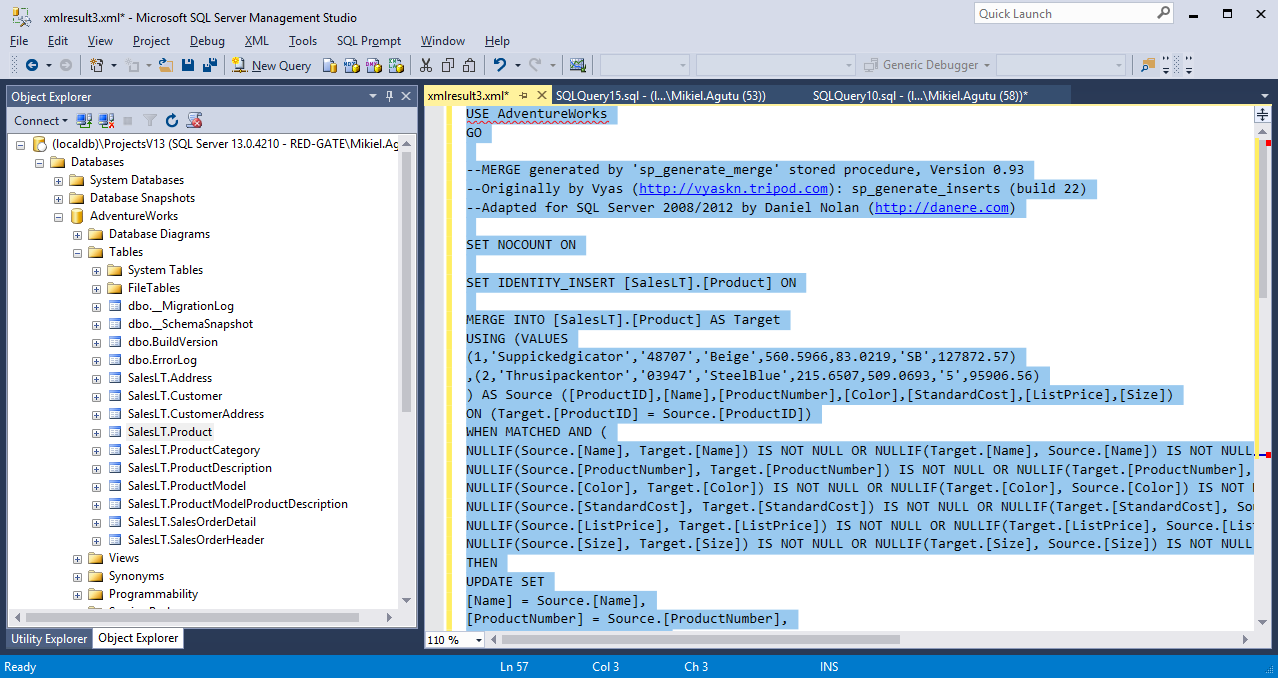
Delete the XML tags, then copy the document contents to the clipboard and switch back to Visual Studio.
In the next step we'll create a script to be executed during each deployment which will ensure that the table is always in-sync.
Add a deployment script to your project
Within Visual Studio, open the Solution Explorer tool-window (View... Solution Explorer) and expand your SQL Change Automation project's Post-Deployment sub-folder.
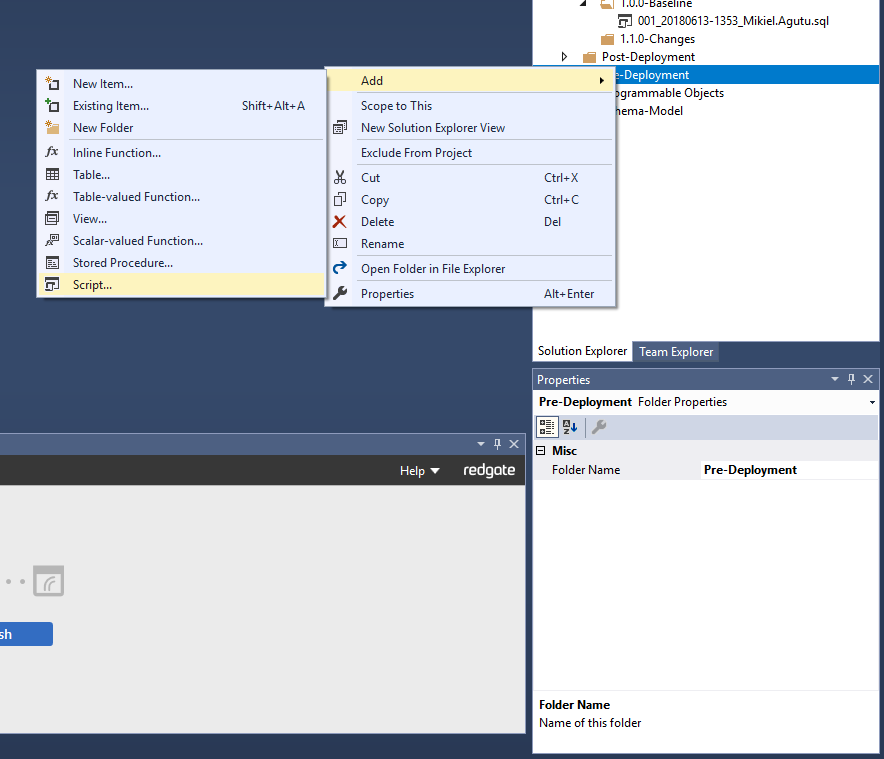
Script naming
Paste the SQL copied in the previous step into the newly created script file.
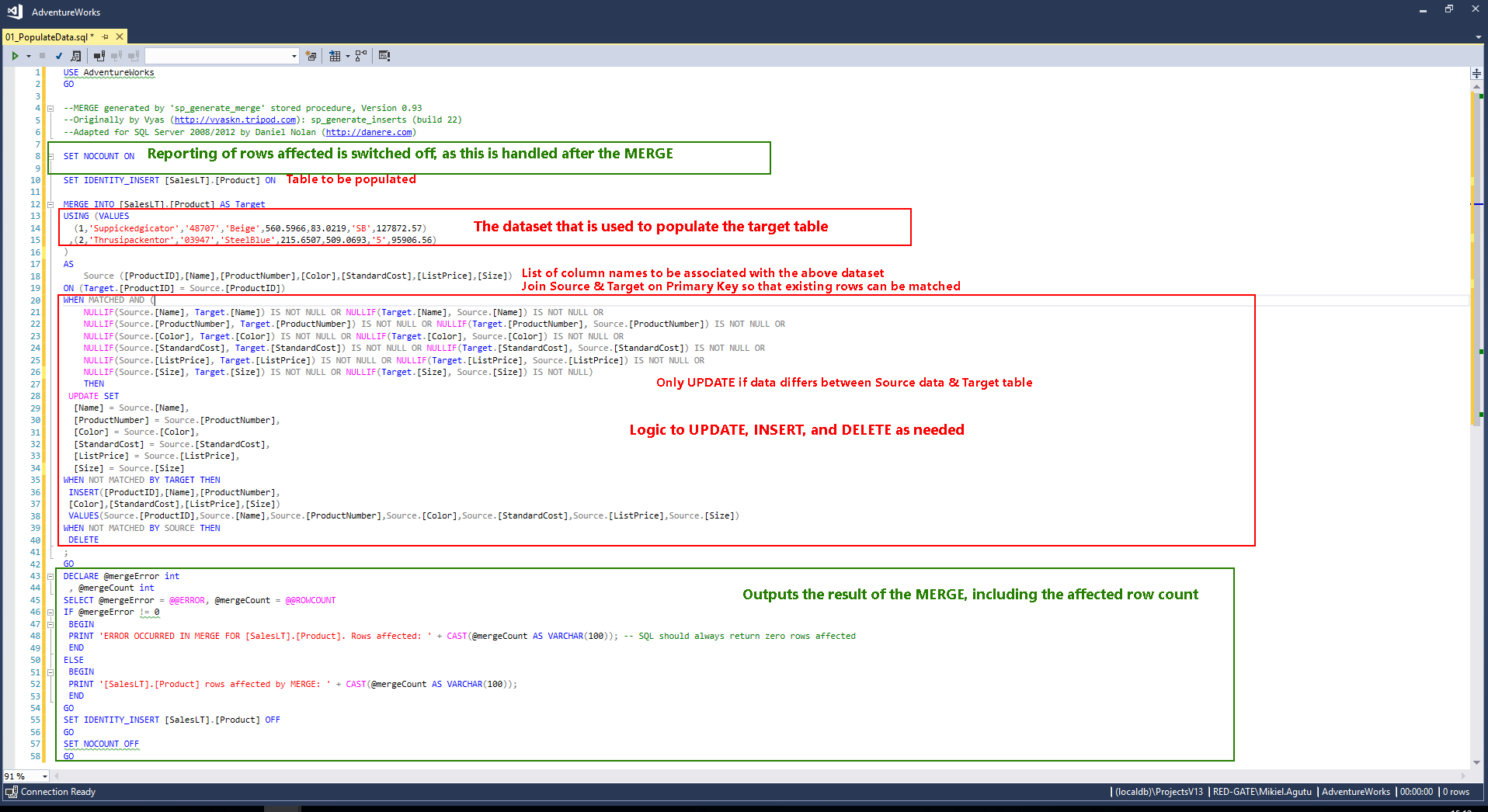

Making Changes to Static Data
To see how the script can be re-used to repeatedly deploy changes in your static data, try making changes to the data in the script and re-run the deployment. The rows affected by the MERGE should reflect your additions and modifications to the file.
If you prefer to initiate changes to data by editing the table data directly in SSMS, you can do so by simply re-running the sp_generate_merge procedure after making changes to the live data. Copy+Paste the generated code as you did in the previous steps to update your Post-Deployment script with the new changes.
Using MERGE to deploy configuration data
Using the offline method outlined above gives you the ability to include SQLCMD variables in place of literal values, allowing data from the deployment system to be passed in and stored within your tables (e.g. environment-specific variables from Octopus).
This means you could use your deployment system to centralize the storage of configuration settings, giving you a systematic and repeatable process for propagating updates to configuration data.
This documentation contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved




