Setting project options
Published 15 August 2013
Project options change the comparison and deployment behavior of Schema Compare for Oracle. For example, you can set a project option to ignore certain differences between objects when you run a comparison.
To set project options:
- Open the Project Configuration dialog box.
- To set options for a new project, on the toolbar, click
 New.
New. - To set options for a saved project, on the toolbar, click
 Open, select a project, and click Open.
Open, select a project, and click Open. - To review comparison results for an open project, on the toolbar, click
 Edit Project.
Edit Project.
- To set options for a new project, on the toolbar, click
- On the Project Configuration dialog box, click the Options tab. This tab lists available project options:
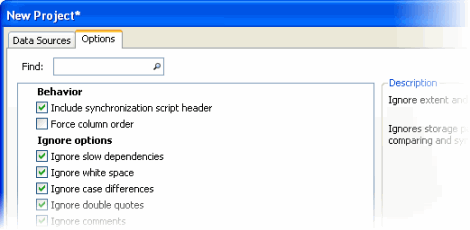
- For each option you want to set, select its check box.
To search for an option, type search text in the Find box. The list of options is filtered to display only options that contain the search text.
The options you set are saved for each project. For more information on projects, see Working with projects.
Schema Compare for Oracle project options
Behavior
Include deployment script header
Includes a comment header at the top of deployment scripts. The header includes:
- the date and time the script was created
- the Schema Compare for Oracle build number used to create the script
Force column order
If deployment requires additional columns to be inserted into the middle of a table, this option forces a rebuild of the table so that column order is preserved following deployment.
The table is rebuilt in four steps:
- A new table is created.
- Data from the original table is copied into the new table.
- The original table is dropped.
- The new table is renamed as the original table.
Use forward slash
Terminates each statement in the deployment script with a forward slash.
Include SET SQLBLANKLINES ON
Adds the SQL*Plus command SET SQLBLANKLINES ON to the top of the script, so blank lines and new lines are interpreted as part of a SQL command or script.
Include SET DEFINE OFF
Adds SET DEFINE OFF to the top of the script file, so substitution values aren't used when running the script.
Exclude schema names
Excludes schema names from the deployment script.
Detect renamed columns
Attempts to detect renamed columns by matching the strings, position in the table, and datatype.
A possible renamed column will be identified if any of the following apply (in order of priority):
- The names are the same (case-insensitive)
- The target column contains the whole of the string source (eg "Company" in "CompanyName")
- The columns are the same ordinal and type, and the names are similar
- The columns have the same type, and the names are similar
Add PURGE clause to all table drops
Immediately releases the space assocaited with dropped tables, instead of moving tables and their dependents into the recycle bin.
If this option is selected, you won't be able to recover dropped tables.
Suppress dependent ALTER COMPILE (experimental)
Turns off all calculations and scripting associated with performing an ALTER COMPILE on objects that are dependent on those that are deployed. Use with caution.
Ignore options
Ignore slow dependencies
Ignores certain dependencies that affect comparison performance when comparing databases. The following dependencies are ignored:
- type objects in your schema that are referenced by an object in another user's schema
- REF constraints in your schema that reference or are referenced by objects in another user's schema
Ignore dependent objects in other schemas
Ignores calculating dependent objects in schemas that haven't been explicitly selected for comparison.
Ignore white space
Ignores white space (newlines, tabs, spaces, and so on) in object SQL creation scripts when comparing databases.
Ignore case differences in PL/SQL blocks
Ignores case differences in object SQL creation scripts when comparing databases. For example, if you turn this option on, MYTABLE and mytable aren't considered different table names.
Ignore double quotes in PL/SQL blocks
Ignores double quotation marks (" ") around identifiers when comparing databases.
Ignore external table location information
Ignores external table location information when comparing tables.
Ignore comments in PL/SQL blocks
Ignores comments in PL/SQL blocks when comparing databases.
Ignore comments on tables, views and columns
Ignore comments on tables, views and columns when comparing databases.
Ignore constraint names
Ignores the names of foreign keys and primary keys, and default, unique, and check constraints when comparing databases.
Ignore index names
Ignores index names for comparison. If two indexes only differ by name, they will be considered identical when compared.
Ignore storage
Ignores storage properties (physical properties and partitioning clauses) on tables when comparing and deploying databases.
Ignore parallel
Ignore differences in the parallel clause on indexes and tables.
Ignore sequence current value
Ignores the current value of sequences when comparing and deploying databases.
If this option is turned on and you deploy a sequence, the current value of the target sequence is retained.
If this option is turned off and you deploy a sequence, the current value of the source sequence is used as the current value for the target sequence.
Ignore permissions
Ignore differences in object permissions.
Ignore log groups
Ignores supplemental log groups when comparing tables.
Ignore materialized view START WITH value
Ignores materialized view START WITH value.
Ignore character length semantics
Ignores length semantics differences for columns.
CHAR and VARCHAR2 columns are stored as CHAR or BYTE depending on the server configuration (NLS_LENGTH_SEMANTICS) or column specification. Normally, if a particular column is stored as CHAR in one schema and BYTE in another, Schema Compare will treat this as a difference.
If this option is set, Schema Compare will not treat it as a difference.
Include storage options
Include all storage options
Includes all storage properties (physical properties) on tables and indexes when comparing and deploying schemas.
When this option is selected, all possible storage clauses are compared and scripted, and all other "Include storage" options are ignored.
Default options
To save your option settings as the default options for all new projects, click Save as My Defaults. To revert to your default settings after making changes, click My Defaults.
To reset all the options to their original settings, click Red Gate Defaults. This turns on the following options:
- Include deployment script header
- Ignore slow dependencies
- Ignore white space
- Ignore case differences
- Ignore double quotes
- Ignore comments
- Ignore constraint names
- Ignore storage
- Ignore sequence current value
This documentation contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved




