Using clones for branch-based development and testing
Published 16 September 2020
Clones make branch-based develoment simple and viable, even for very large databases
Each developer can each work on a clone, created from the current build, run on it the migration script to apply the changes for their branch, and then run all the necessary tests. This reduces the risk that merging the branch into 'main' will introduce errors that subsequently break the build.
Many teams split different strands of the development effort into separate branches in the version control system. Often this is to isolate specific tasks, such as bug fixing, into a separate branch, or the team might create a branch to stabilize a certain version of the repository for QA testing or customer assessment, while the main development effort continues. Branching can also allow each developer to focus on a specific functional area of the application, so minimizing the risks of two developers working on the same set of objects, in main.
In some cases, teams can do all database development work in main, but to do it successfully requires a well-designed application-database interface and use of schema-based development to minimize conflicting changes
SQL Clone makes branch-based database development a lot more efficient, due to the ease with which each developer can recreate a clone for their branch version of the current build, complete with data, and then dispense multiples copies of the branch version, as required for testing. How might it work? As discussed in Provisioning development with the latest build using clones, the team regularly perform a full build of the current version, from source control. Assuming the build succeeds, and passes the automated integration tests, you can create an image from it and dispense clones for each development branch. The current build will be used for development until the branches that, together, constitute all the changes required for the next version are merged into main, and the next build is created.
Managing branch-based database development using GitHub and Redgate tools
See the Redgate Product Learning article, Database Development with GitHub for a detailed explanation of how you can do this.
A developer working on a clone, in their branch of source control, will makes changes to their local clone, run the necessary tests, commit the changes to that branch in source control, such as by using SQL Compare or SQL Source Control, and save the migration script to a script folder, named according to the current build version plus a git tag for that point in the branch (e.g. v2.4.12-tag). To start a test on any branch, a developer just needs a clone current build of the database, with the branch migration script applied to it, to add the new objects, modify existing objects, and make any necessary data migrations if schema changes are made that affect existing data:
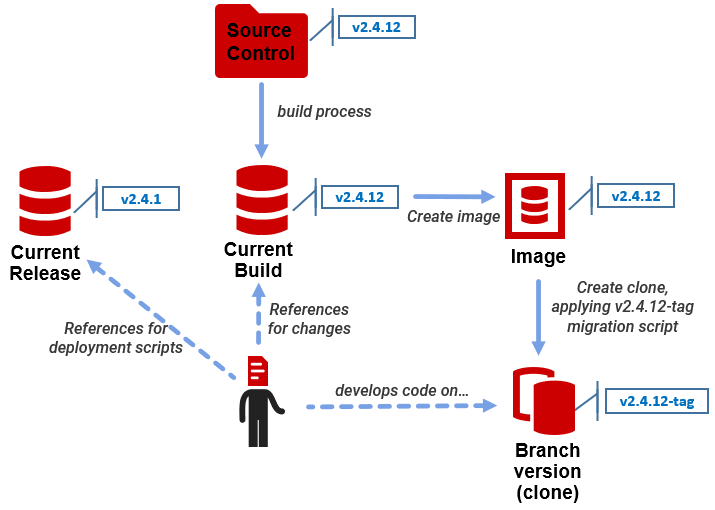
All this can be done either using a PowerShell script or through the UI. A scripted process can simply select the migration script with the right name from a source control directory, or the script can be applied to the branch clone as a SQL Clone template. With their development copy (clone) of the database to work on, and access to the current build and current release databases, any developer has a way to create and test all the required migration scripts.
Each branch clone would be named according to its tag, and you may need some mechanism to ensure that each clone could commit changes only to the correct branch in the version control system.
Automatic branch switching
If you use SQL Change Automation for your database builds and deployments, an alternative technique is to set up git hooks for the SQL Clone API that will allow developers to collaborate on difference branches, and switch between them automatically, without fear of losing work. See: Automatic cloning for Git branches
This documentation contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved




