Can I make a Substitution rule faster?
Published 21 March 2018
V7 performance beta
Looking to speed up your Substitution rules?
Get early access to our improved masking algorithm today by enabling the enhanced performance beta
This Tech Tip focuses upon the key data masking practice of substitution using “like-for-like” replacement datasets. Let’s start with an overview of the rule design since this will help us understand the factors which may affect it and how we can consider our options. Here’s a sample rule using the Data Masker Sample Database:
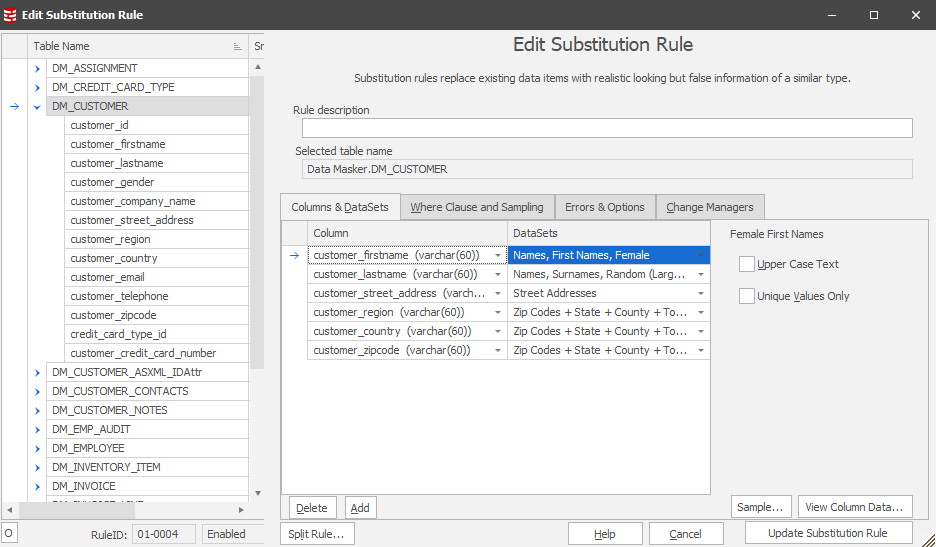
How does it work?
The Substitution rule issues update statements with 1,000 row commit intervals against the database using the replacement datasets. An advantage of this approach is that progress statistics can be displayed in the Rule Statistics tab once each 1,000 row statement is processed by the server.
In this case, the update statement looks like:
UPDATE [dbo].[DM_CUSTOMER]
set [customer_firstname]=CASE WHEN [customer_firstname] IS NULL THEN cast(NULL as varchar(60)) WHEN [customer_firstname] = '' THEN '' ELSE @u_customer_firstname END, [customer_lastname]=CASE WHEN [customer_lastname] IS NULL THEN cast(NULL as varchar(60)) WHEN [customer_lastname] = '' THEN '' ELSE @u_customer_lastname END, [customer_street_address]=CASE WHEN [customer_street_address] IS NULL THEN cast(NULL as varchar(60)) WHEN [customer_street_address] = '' THEN '' ELSE @u_customer_street_address END, [customer_region]=CASE WHEN [customer_region] IS NULL THEN cast(NULL as varchar(60)) WHEN [customer_region] = '' THEN '' ELSE @u_customer_region END, [customer_country]=CASE WHEN [customer_country] IS NULL THEN cast(NULL as varchar(60)) WHEN [customer_country] = '' THEN '' ELSE @u_customer_country END, [customer_telephone]=CASE WHEN [customer_telephone] IS NULL THEN cast(NULL as varchar(60)) WHEN [customer_telephone] = '' THEN '' ELSE @u_customer_telephone END, [customer_zipcode]=CASE WHEN [customer_zipcode] IS NULL THEN cast(NULL as varchar(60)) WHEN [customer_zipcode] = '' THEN '' ELSE @u_customer_zipcode END where [customer_id] = @j_customer_id
It looks verbose because this statement is designed to enforce the where clause :
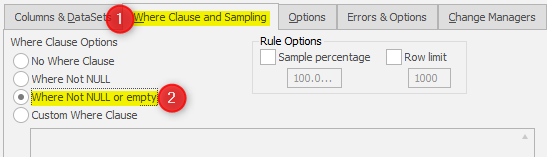
…. hence the reason that each item’s update statement is crafted as:
set [customer_firstname]=CASE WHEN [customer_firstname] IS NULL THEN cast(NULL as varchar(60)) WHEN [customer_firstname] = '' THEN '' ELSE @u_customer_firstname END
Obviously setting the rule to “No Where Clause” will simplify the update statement but this will have the effect of putting replacement data into columns which are null or empty and that’s not normally what we want in creating a masked database.
In cases where the generated where clause is know to be redundant (for example you know all rows contain non-null data), or you don't require null columns to be masked as null, setting the “No Where Clause” can significantly improve performance.
How does Data Masker identify rows to update?
Prior to the update statement being issued Data Masker queries the database for the “row identifiers” of those rows which match the where clause. Data Masker for SQL Server requires the presence of a Primary or Unique index to be able to identify each row as a masking candidate and therefore be able to select or update based upon the where clause. Data Masker for Oracle uses ROWIDs as its row identifiers. Row identifiers are downloaded to the Data Masker client and temporarily stored in one of its working directories. This temporary file is removed at the end of the update process.
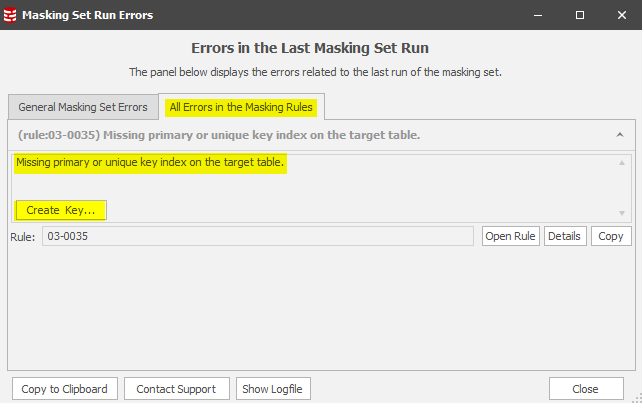
Notice the Create Key feature. This will give us everything we need to create an Identity Column (a unique row identifier) on the table and assign it as a Primary Key:
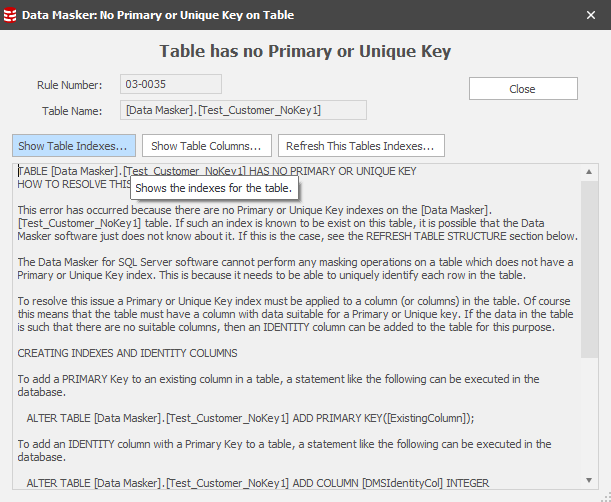
Note also the final statement in this panel. You must refresh Data Masker’s understanding of the table structure and save the masking set away.
So, can I make it faster?
There are a number of factors which affect the performance of a rule and we’ll take each in turn.
Triggers
By default, Data Masker builds “bracketing rules” which will disable all enabled triggers at the outset and then enable them at the end of the masking process. If you Run the Masking Set these rules will execute. If, however, you run a rule manually (Right Mouse Button/Run Rule) then the triggers will remain active and if you have one which fires on update of the table your rule is focused upon you will have the overhead of the trigger action.

The indexing strategy supporting the table
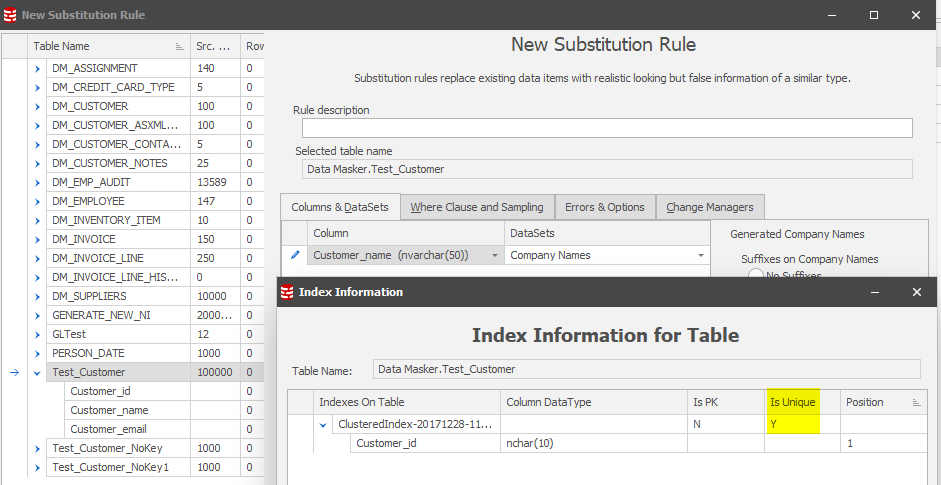
When building a substitution rule it is good practice to locate on the table name (having built the rule and chosen your columns to be masked) and, using the Right Mouse Button, display the indexes on the table.
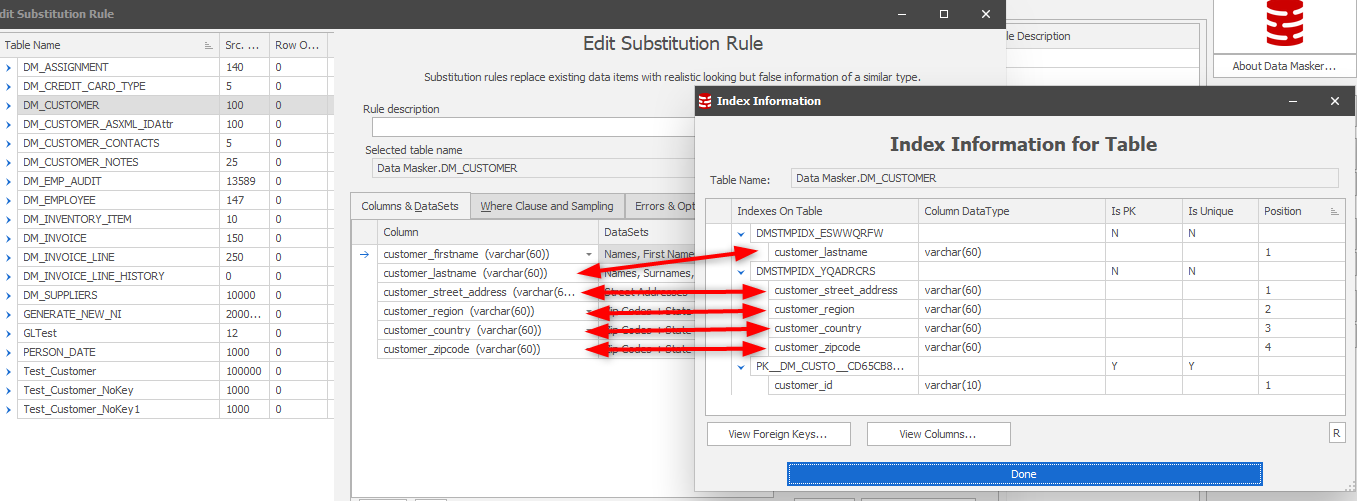
This now allows us to understand the overhead of index updating when the table is updated. Remembering always that we need to retain either the PK or a UK we may now choose to disable these two indexes and then rebuild them after the masking operation has run. We do this using Command Rules which will execute any DML or DDL which the user connecting in the Rule Controller has permissions to execute.
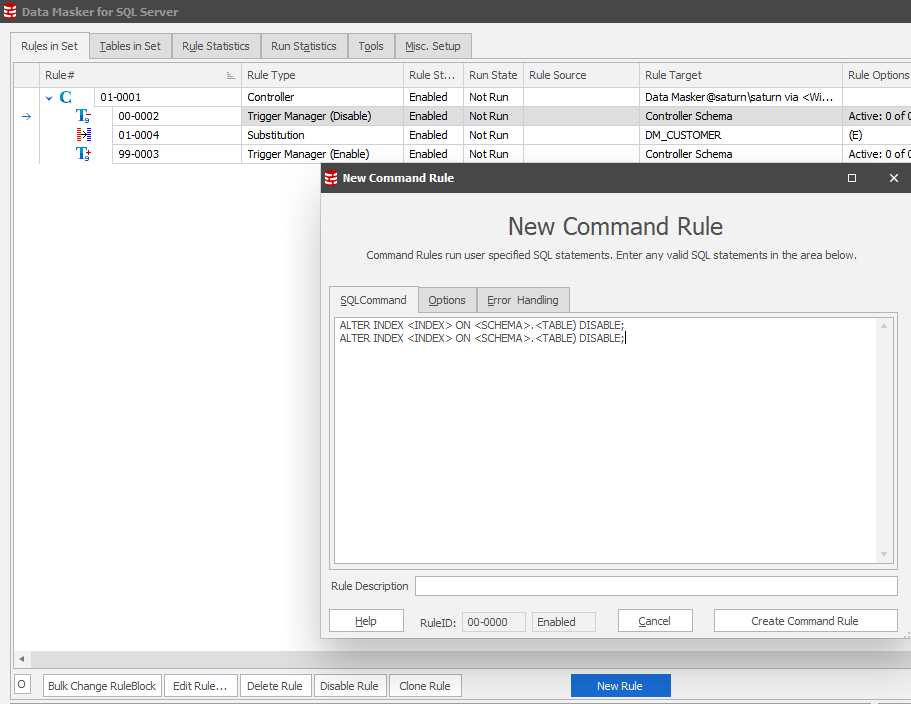
Notice that the Trigger Manager was highlighted as the rule in context when the New Rule option was chosen. This means that the next new rule will be in that same “Pre-processing” block 00:
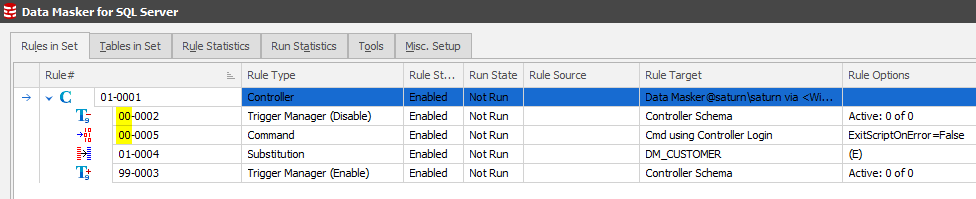
It follows that locating on the block 99 Trigger Manager and creating another Command Rule to rebuild the indexes would be your next step.
Note: Always remember that your next rule will be in the same rule block as the rule which you have in focus!
Unique Key constraints
Does your table only have a Unique Key constraint? As this would be the only unique row identifier (whether simple or compound) Data Masker will, of course, choose it.
The code executed in the example above is:
UPDATE [dbo].[Test_Customer] set [Customer_name]=CASE WHEN [Customer_name] IS NULL THEN cast(NULL as nvarchar(50)) WHEN [Customer_name] = '' THEN '' ELSE @u_Customer_name END, [Customer_email]=CASE WHEN [Customer_email] IS NULL THEN cast(NULL as nvarchar(50)) WHEN [Customer_email] = '' THEN '' ELSE @u_Customer_email END where isnull(CAST([Customer_id] as varchar),'null') = isnull(CAST(@j_Customer_id as varchar),'null')
When executed, this rule performs badly. The stats after ~ 1 hour were:

![]()
(The “Errored” is because the rule execution was terminated prior to completion).
In the Primary Key scenario earlier, performance was acceptable because the Optimiser chose an execution plan based upon the fact that a PK cannot be null. In this scenario, however, one key item “may” be NULL. The UK may equally be of a compound construct giving us a number of combinations of NULL valued key contents. The Optimiser therefore takes a different approach.
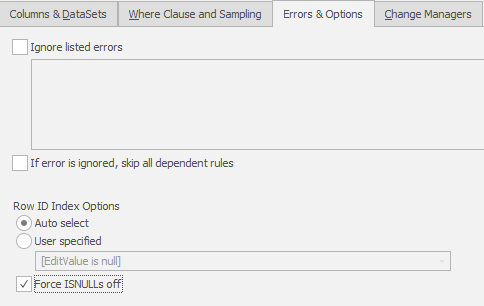
If this is the case, look at the Unique Key constraint. Is it simple or compound? Do any of the key items contain a NULL. Look at the data and confirm it. If there are no NULLS we can change the approach to this rule using an Option in the Substitution Rule context:
Update the Substitution Rule.
Run the rule and the results are very different:

Why does Data Masker use IS NULL by default? It’s to future-proof the tool as Microsoft evolves NULL handling. For background have a look at:
https://docs.microsoft.com/en-us/dotnet/framework/data/adonet/sql/handling-null-values
…. but now you know about the Force ISNULLs off switch!
Anything else I might do?
Sometimes we may have a number of items which need to be masked in a single row. There’s no fixed guidance (since it’s all resource related) as to how many columns should be updated in a single rule but we work on the rule of thumb of 6 to 8. The premise is simple – there’s going to be 1,000 rows go up to the server from Data Masker and the more columns being updated, the wider the update statement is and the greater the pressure on the RDBMS to accommodate them.
Sometimes it’s worth trying to “Split” the rule into more manageable chunks.
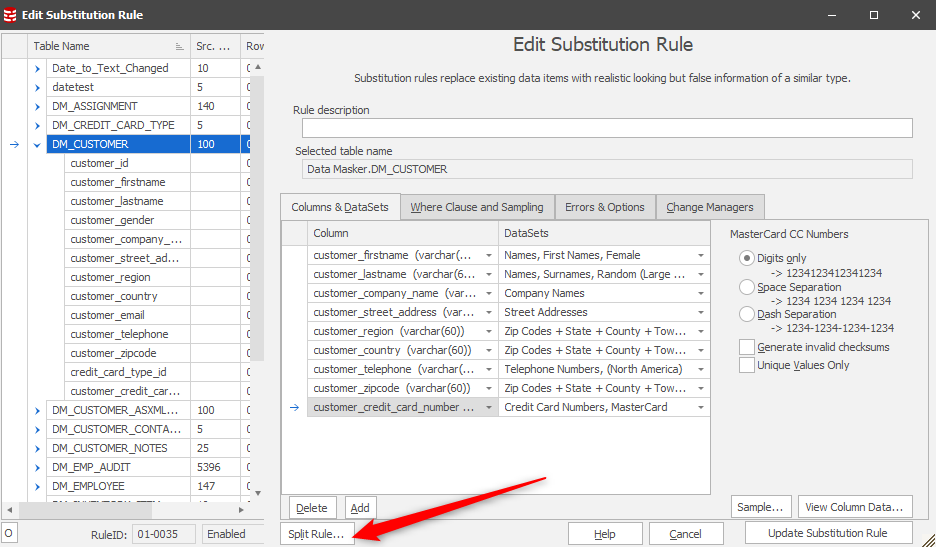
This invokes a dialogue where you can define the number of columns as the divisor:
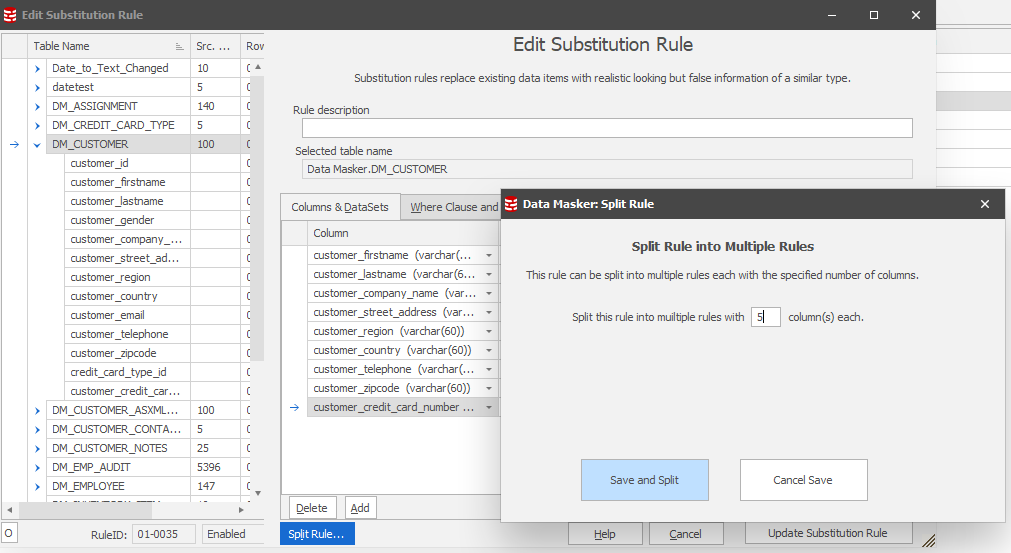
The net result is two rules:

However, we must proceed with caution!
These rules now reside in the same rule block number and are addressing the same table. It’s possible, therefore, that there may be a deadlock on them since Data Masker implements a two connection strategy by default and this can be increased to 16. The Data Masker Scheduler will therefore see these two rules as candidates for concurrent execution. To address this, we make the second rule dependent upon the first with a simple drag and drop operation.

Anything else?
Yes. There’s always support@red-gate.com . Never hesitate in contacting our team if you need help in creating your data masking sets.
This documentation contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved




