Can I make a Table-to-Table rule faster?
Published 21 March 2018
While this article includes screenshots and code snippets that apply only to Data Masker for SQL Server, the advice applies equally to Data Masker for SQL Server and Data Masker for Oracle.
Before going too much further let’s explain what a Table-to-Table rule is and how it works.
Since we don’t live in a perfect world all the time we can come across a scenario where data items are replicated, or denormalized, across tables. Often these tables are in the same database but occasionally they’ll be in another database(s) in the same instance or server. Sometimes the synchronization may need to take place between other instances/servers but that’s for another day……
It’s important that we try to synchronize any substitution actions we may have taken against elements of a row in one table with the corresponding elements in the other table(s). If we don’t do this, the data inconsistency will lead the user of the database to believe that it is “broken”:
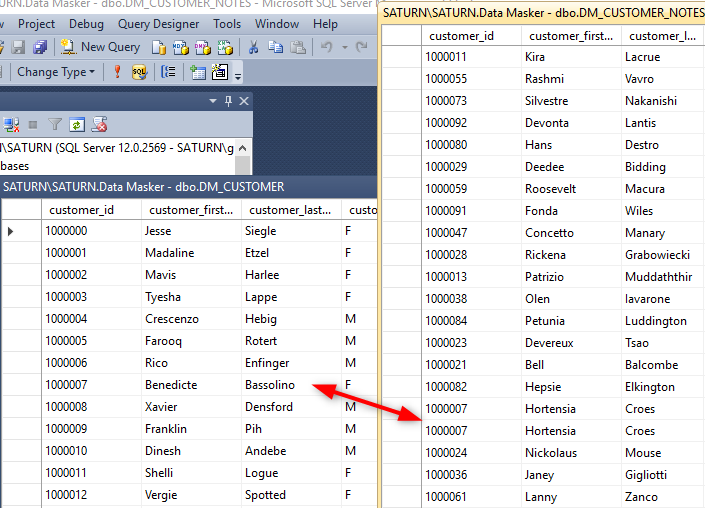
The ultimate objective of a credibly masked database and the Table-to-Table rule technique helps you ensure this.
If you are reading this Tech Tip then you have already created one of these rules and you perhaps feel that it’s running slower than you would expect. Sometimes the sheer volume of data to be synchronized by its nature will take time and require patience. Sometimes there may be things we can look at and do.
When we’re synchronizing between tables we obviously must specify a join condition. As an example:
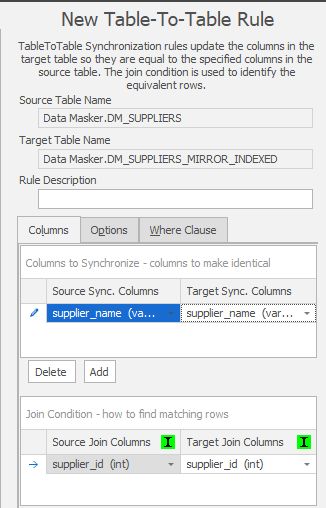
Notice the Green “I” for “indexed” on both the source and target sides. It’s the target side indexing strategy that matters to avoid full scans during the synchronization process. More on that a little later. For now, we’ll assume that we have indexes on both sides but it still “feels” slow. For the purposes of the rest of this document we’ll be using three tables, the naming conventions are self-explanatory:
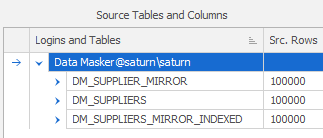
The DM_SUPPLIERS_MIRROR_INDEXED is a direct replicate of DM_SUPPLIERS and has a Primary Key.
Let’s start by looking at how that rule above works. It creates a procedure which contains:
UPDATE DMTGT
SET DMTGT.[supplier_name] = DMSRC.[supplier_name]
FROM [Data Masker].[dbo].[DM_SUPPLIERS_MIRROR_INDEXED] DMTGT, [Data Masker].[dbo].[DM_SUPPLIERS] DMSRC
WHERE DMTGT.[supplier_id] = DMSRC.[supplier_id]
AND DMSRC.[supplier_id] = @r_supplier_id;
Prior to this procedure executing, Data Masker will fetch down all of the supplier_id’s from the source table and will hold them in a temporary file on the Data Masker client. The update statement is then executed in 1,000 row tranches and committed. The benefit of this approach is that the progress indicators in the Statistics tabs will be updated.
The run-time results are:

Edit the Table-to-Table rule and have a look in the Options tab:
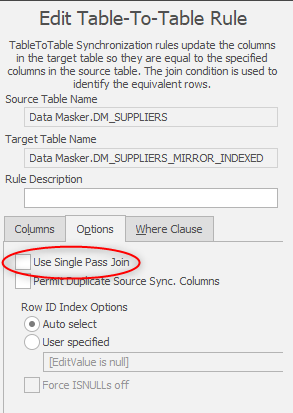
In this section there’s an option to use a Single Pass Join. This approach uses the target table as the driver and updates it from the source:
UPDATE DMTGT
SET DMTGT.[supplier_name] = DMSRC.[supplier_name]
FROM [Data Masker].[dbo].[DM_SUPPLIERS_MIRROR_INDEXED] AS DMTGT, [Data Masker].[dbo].[DM_SUPPLIERS] AS DMSRC
WHERE DMTGT.[supplier_id] = DMSRC.[supplier_id];
You’ll see that the initial row identifiers (in this case the primary keys) are no longer called down nor used as part of the update statement.
…and the performance is:

During execution the rows processed count was not displayed but the final row count is noted. Most clients don’t mind this since masking sets are often executed in batch and progress counts are irrelevant. This approach is usually the best to try first if we’re joining on PK’s. But what if we’re not?
Let’s now extend to the non-indexed DM SUPPLIER_MIRROR table and create a rule to synchronize from DM_SUPPLIERS:
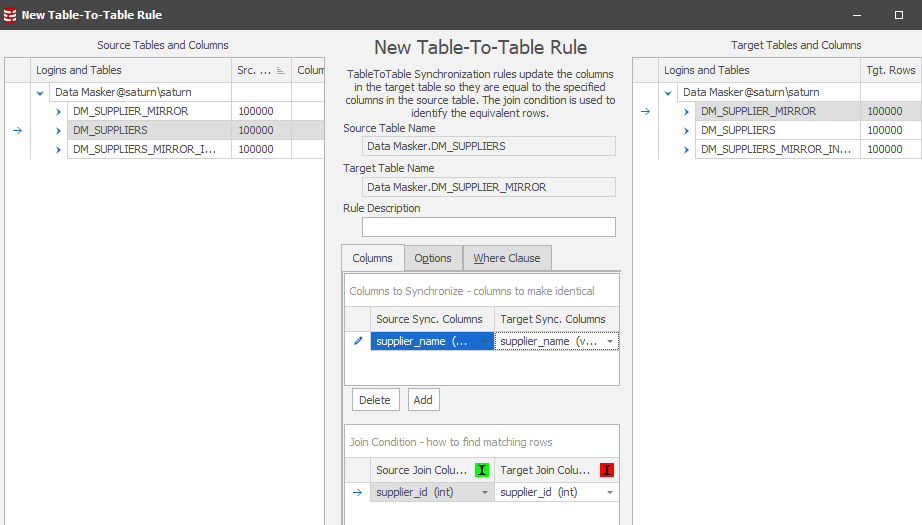
We’ll run it and watch progress:

….and watch and watch and watch – less than 1,000 rows synchronized in more than a minute! This is because the target side is being full-scanned – all 100,000 rows, 100,000 times.
Clearly adding an index must be the next stage. To help you do this, Data Masker has a tool:
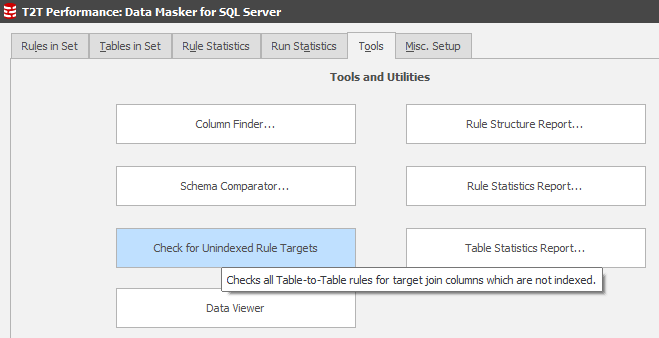
Invoking this option will list all table-to-table target join conditions which are not indexed:
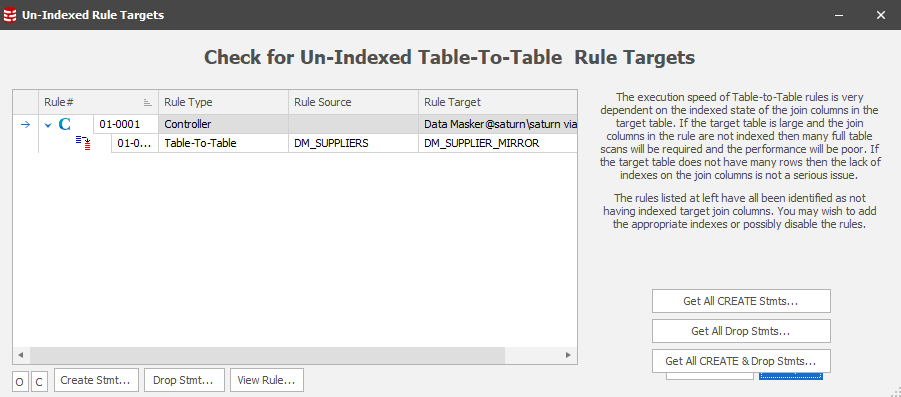
Data Masker will give you the ability to generate create and drop statements for any unindexed targets:
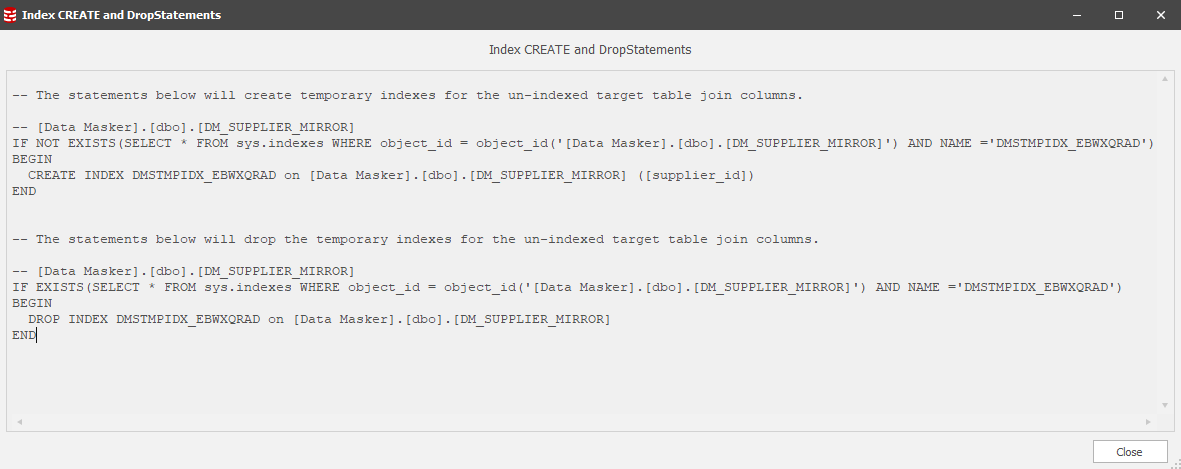
How do you make these index management actions part of the masking set? The answer is that you use Data Masker Command Rules positioned in such a way that they pre-and post-process in anticipation of the synchronization rules which may benefit from them. CTL_A / CTL_C the contents.
Placing Data Masker Pre- and Post- Processing Command Rules
In generating your masking set you will have noticed the creation of two Trigger Manager rules which will disable and enable all active triggers. Notice the Rule Block numbering convention:
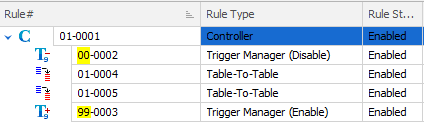
These Managers are Pre- and Post-processors – they wrap around the rules we’ve been creating. Rule block “00” is an ideal place to put the Command Rule to create the indexes and, obviously, “99” is the block where we position the index drop Command Rule. To do this, locate on the first Trigger Manager and New Rule / New Command Rule :
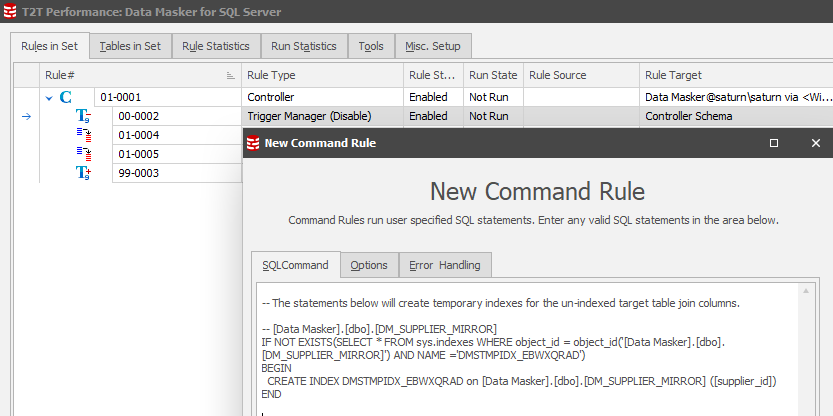
Paste the copied create and drop statements into this panel and the CUT the drop statement. Save the rule.
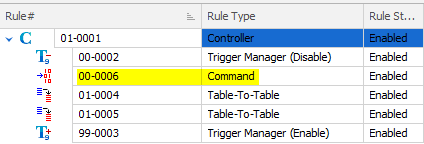
We should NEVER add or change a database object without reverting the structure to the way that we found it. If we leave an index behind we can rest assured that someone will see it and use it, assuming it’s in the production database as well.
Using the process above as a guideline, create a Command Rule in the Post-Processing rule block and paste in the index drop statement which you cut from the Pre-Processing Command Rule.
Note: The Data Masker masking set does not need to be updated to recognize the index(es) since it is the optimizer which will identify and use it during the synchronization process. Data Masker will continue to display the warning that the join condition is unindexed, but we know we’ve managed our way through this.
Note: Pre-Processing Command Rules are great places to put other actions, too. Very often there are tables which contain data which is not required down-stream – for instance log or audit tables. These are ideal candidates for a truncate table <my_audit_table>; command. In more complex masking sets these rules may also contain grant or revoke privilege statements.
Back to running the rules
If we now run the masking set the rule performs much better:

As with the first run Data Masker is using the row-identifiers in 1,000 row commit intervals to effect the synchronization. There’s a difference, however, in that we have to assume that the target join condition may have null content (which we didn’t have with the PK) and so we must use an update statement which encompasses the fact:
UPDATE DMTGT
SET DMTGT.[supplier_name] = DMSRC.[supplier_name]
FROM [Data Masker].[dbo].[DM_SUPPLIER_MIRROR] DMTGT, [Data Masker].[dbo].[DM_SUPPLIERS] DMSRC
WHERE isnull(DMTGT.[supplier_id],0)=isnull(DMSRC.[supplier_id],0)
AND DMSRC.[supplier_id] = @r_supplier_id;
The isnull construct is implemented so that target columns with a null remain null. Microsoft is evolving NULL handling. For background have a look at:
https://docs.microsoft.com/en-us/dotnet/framework/data/adonet/sql/handling-null-values
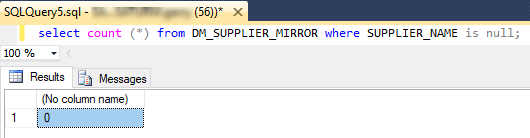
Let’s discover whether the target table has nulled SUPPLIER_NAME content:
We can now configure our Table-to-Table rule to ignore null value processing with confidence that all rows will be synchronized correctly. Navigate to the Table-to-Table options tab and set the Force ISNULLs Off option. Your challenge is that this option is initially disabled and the reasoning behind this is to ensure that you think about the zero null value confirmation phase above. Save your rule and navigate to the Misc Setup tab where you will find a switch under the Rule Default Options:
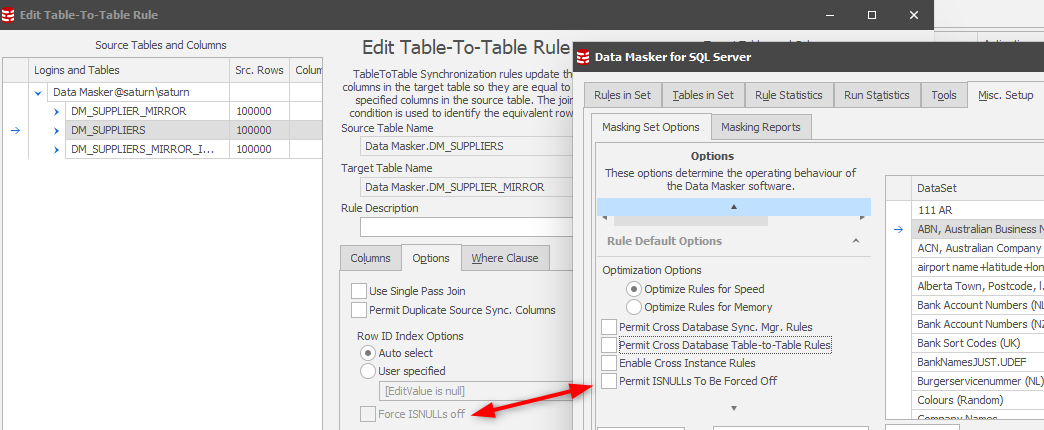
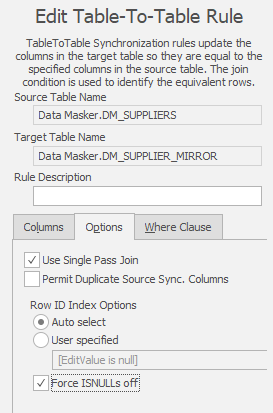
Select the switch in Misc set and save your masking set for it to take effect. You can now edit your Table-to-Table rule and enable both Single Pass Join and Force ISNULLs Off:
The resultant runtime is:

…which is just as fast as the original rule which used the primary key and the target table as the driver but remember there will be no progress indicators.
In Summary
A number of options are available to us to try to improve Table-to-Table performance. In all instances (and just the same as every other rule technique) we must be sure that we do not inadvertently “skip” masking or synchronizing values within and across our databases.
This documentation contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved




