Rule Blocks and Dependencies – are they really necessary?
Published 21 March 2018
All actions within Data Masker are performed using a masking rule. Masking rules implement such techniques as the substitution of information from pre-supplied or User Defined datasets, the shuffling of a column (or columns) of data, or the synchronization of data.
Important note: Data Masker is multi-threaded. It can, and will, run multiple rules simultaneously. The number of rules which can run in parallel is determined by the Number of Rule Workers setting on the Run Statistics Tab. Unless strictly specified (see below) each masking rule is considered by Data Masker to be an independent entity and its order of execution is not guaranteed.
Often, it is necessary to ensure that a certain rule completes before a subsequent rule executes. This is especially true if multiple masking rules will be operating on the same table rows and columns.
Here's a typical scenario. A table of customer information needs to be rendered anonymous and it has been determined that one of the columns which requires masking is the FIRST_NAME field. As an additional requirement, it is necessary that the masked data use names (male or female) appropriate to the gender of the record. The gender information M or F for each record is available in a GENDER field and a Where Clause option on a Substitution rule can easily handle the substitution of the first names from the two standard datasets: Names, First Names, Female and Names, First Names, Male.
For this case it is decided that a Substitution rule to mask all first names (regardless of gender) using the female first names dataset will be implemented and appears in the running order as:
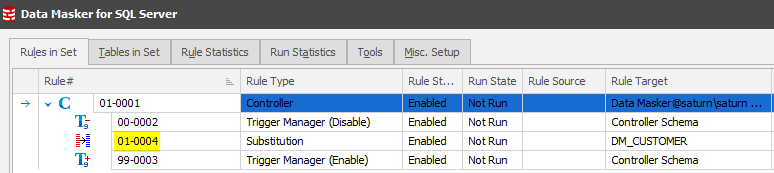
…. and a subsequent Substitution rule with a Where Clause of WHERE GENDER='M' will then make sure the male names have appropriate values.
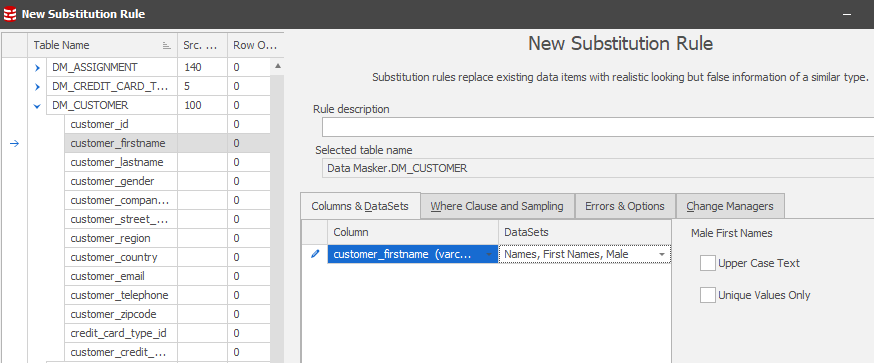
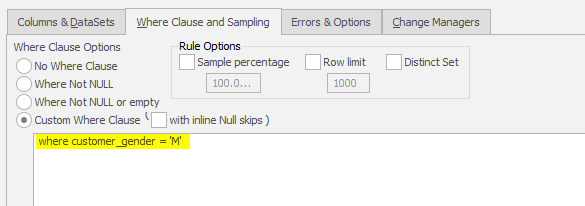
This masks everything and go back and reconcile the where clauses method avoids the Where clause skip scenario in which it is assumed that the GENDER column will always contain only M or F records.
Clearly, in the above example, it is not possible for the rule which will mask all the rows in the table to run at the same time (or after) as the rule which masks only the rows WHERE GENDER='M'. If the rule which masked all rows with female first names ran after the rule which substituted male first names, then any changes made by the male first names rule would be obliterated and the FIRST_NAME field would have only female first names. In this case, the order of execution really matters, and it must be explicitly defined within the Data Masker masking set.
There are two ways to control the execution sequence of rules and make sure that they execute in the required order: Rule Dependencies and Rule Blocks. The following sections will consider each mechanism.
Rule Dependencies
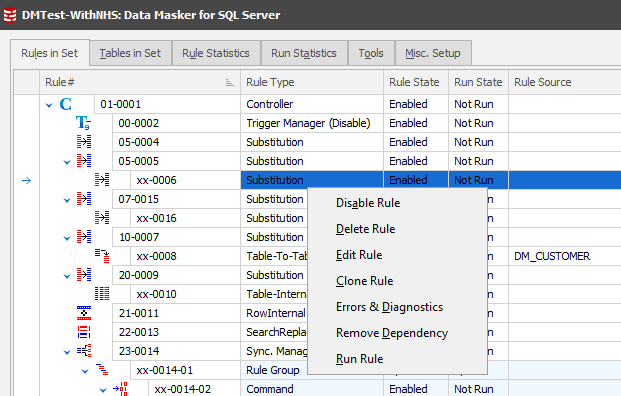
If a rule must execute after another rule completes, it is possible to build a dependency chain. Dependent rules cannot execute until their parent rule has finished execution. The dependency state of a rule is displayed on the Rules in Set tab in an indented form as shown below:
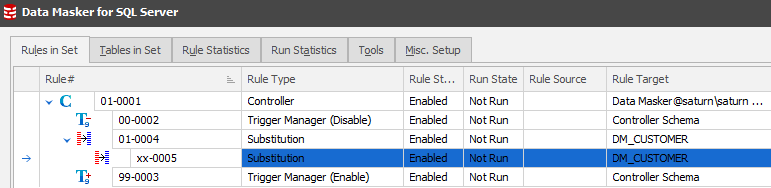
In the above illustration, rule 0005 is dependent on rule 0004 and will not execute until all substitution operations of rule 0004 complete. It is possible to build chains of any depth and complexity. To make a rule dependent on another rule simply use the mouse to drag and drop the dependent rule onto the parent rule. The screen will redraw to show the appropriate indentation once the dependency has been configured. To remove a rule dependency, drag and drop the dependent rule onto the Rule Controller.
You can make a dependent rule non-dependent by right clicking on it and choosing "Remove Dependency". If the rule itself has dependents these will be maintained.
Rule Blocks
Dependency chains are useful but there are dependency relationships under which their utility becomes less useful or practical. Imagine a scenario in which two rules (A, B) must execute to completion before a third and subsequent rules (C,D, E) can begin. Implementing this scenario with dependency chains configures a sequence like:
A-->B-->C-->D-->E
in which each rule is dependent on the rule above it in the chain. This makes the chain very long when, in fact, rules C, D and E could run concurrently if rules A and B have finished.
To simplify things and to avoid implying false dependencies, Data Masker implements a concept called Rule Blocks. A rule block is a two-digit numeric prefix listed before the rule number. Rule blocks are processed in strict numeric order and all rules in each rule block will complete before any rule in the next highest rule block begins. Inside a rule block the rules execute in random order as determined by the optimization routines and the availability of worker threads.
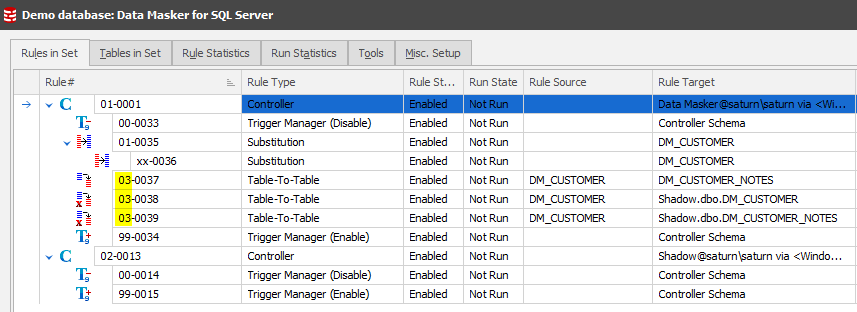
The above scenario would be handled by placing rules A and B in a numerically lower rule block than rule D, E, F. No complex dependency chain is necessary. The image below illustrates a sequence of such rules. All rules in rule block 01 will complete before the next highest rule block (rule block 03) will begin to execute.
In this case it may be desirable to increase the number of worker threads in the Run Statistics tab to get all three rules running together.
To change a rule block value (or rule number) highlight the entire rule block field and edit the rule block value as appropriate. If it is required to adjust the rule blocks of multiple rules multi-select them all (CTL or Shift and choose the range) and use the Bulk Change Rule Block tool activated by clicking on the Bulk Change Rule Block button at the bottom of the Rules in Set tab.

Rules marked with a xx will have their rule block decided at runtime based on their parent. In this example, rule 0036 will have a rule block of 01 at runtime.
When is it appropriate to control the rule execution with dependencies instead of rule blocks?
The decision is something of an arbitrary choice. Typically, dependencies are used to illustrate that the dependent rules are really just different aspects of the same masking operation. For example, rules 0004 and 0005 are both part of the same masking operation on the customer table.
Using a dependency relationship here instead of a rule block clearly illustrates to the viewer how the two operations are related. Often different rule blocks are used as a notation convention to mark operations on separate tables, or what may equally be described as “separate pieces of work”. In the above example the Table-to-Table operations have been placed in the 03 range of rule blocks. This allows concurrency of rule processing since none will deadlock each other and the synchronisation process can happen because it’s safe to assume that if the scheduler has reached this rule block then previous rules will have completed successfully.
To answer the question posed at the beginning of this Tech Tip, Rule Blocks and Dependencies are extremely important in sequencing the masking operation and achieving as great a degree of parallelism as you can to complete the masking process in good time.
This documentation contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved




