Database DevOps FAQs
Published 05 April 2021
This section answers a number of common Database DevOps questions. If you have additional questions, email us.
What is Compliant Database DevOps?
Compliant Database DevOps helps you deliver value quicker while keeping your data safe.
DevOps is a cultural change of breaking down silos and working together to deliver value to your users. Redgate helps remove the database as a bottleneck to releasing value quicker by including your database in DevOps best practices like version control, continuous integration and testing, and automated releases. We also help you handle the specific challenges that come with the database by protecting your data and keeping it safe. There are four parts to Compliant Database DevOps:
- Standardize team-based development - break down silos and enable collaboration with version control
- Automate database deployments - provide a consistent, scalable, and repeatable processes for deployments
- Monitor performance & availability - proactively monitor for problems before they impact your end-users and diagnose issues quickly
- Protect and preserve data - develop and test against realistic datasets without increasing your exposure to a data breach
For more information, see our whitepapers.
Should I use a shared or have dedicated development databases for all developers?
There are pros and cons for each approach.
Shared databases
- Easier to provision
- Limits the overhead of tracking the proliferation of databases in an organization
- Cheaper to license
But...
- Developers tread on each other's toes.
- Work can be overwritten
- Breaking changes will break everyone
- Easy to accidentally check in changes to VCS that belong to a different co-worker
Dedicated databases
- Developers can experiment on their own sandboxes without fear of breaking the database for their team
- Aligned with how application code is managed
But...
- A large number of databases is harder for a DBA to keep track of.
- A database, its environment and configuration can be complex and time-consuming to provision. If this is a manual process, this becomes impractical for an organization.
Think about using SQL Clone for dedicated development databases. Join our Early Access Program for Redgate Clone for cloning SQL Server, PostgreSQL, MySQL, Oracle, and more.
Which Version Control System (VCS) should I use?
Your organization will almost certainly use a version control system already, so the obvious choice is to use the same for your database assets.
If you are in the process of selecting or reviewing your VCS, it is worth bearing in mind that the industry trend is moving away from centralised checkout-edit-checkin version control systems to edit-merge-commit distributed version control systems, in particular, Git.
According to a 2016 survey by ZeroTurnAround, Git is leading the pack with 68% of the market share, followed by Subversion on 23%.
Should I used a state-based or migrations-based deployment model?
The state-based model is well-understood and simple, but doesn't allow developers to customize the way changes are deployed unless they use pre- and post-deployment scripts alongside the state changes. With a state-based model, the CREATE script for each object is stored in version control. At deployment time, a comparison is done to see what's different and generate a deployment script to make the target look like the source. This will undo any changes made directly to the target database because what's in version control is considered to be the source of truth. 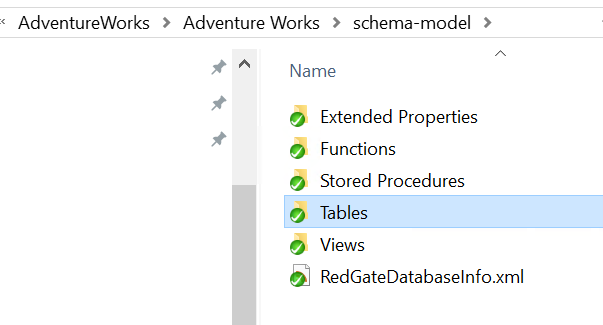
The migrations-based approach allows for more control over the deployment because each change script is stored in version control. The tool tracks which change scripts have already been applied to a target database and executes the remaining ones. However, managing the additional migration script artifacts at the development phase could come with additional overhead and adds complexity where branches are used, particularly when merges cause dependency issues.
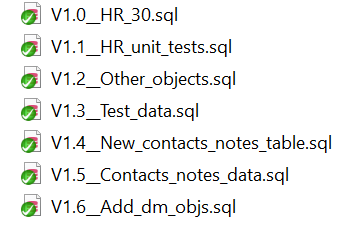
Redgate Flyway provides the best of both worlds benefiting from object-level history as well as the fine-grained control afforded by migration scripts. The object-level history also helps to identify conflicts when using branches.
How do I integrate with bug or work tracking software like Jira or Azure DevOps Work Items?
If setup, typing a Jira issue number or the Azure DevOps Work Item ID (e.g, #32) when entering a commit message in Flyway Desktop will automatically associate that commit with the issue. You can also learn more about integrating your release management system with issues to automatically update the status of them. An example of this can be seen on Stack Overflow.
Which Continuous Integration (CI) tool should I use?
Your organization will probably have a Continuous Integration system already in place, so the obvious choice is to use the same for your database assets.
According to a 2016 survey by ZeroTurnAround, Jenkins is the most popular tool with 60% market share. It helps that Jenkins is free open source, with a huge number of community-contributed plugins. We like the Blue Ocean open source plugin, which provides a more visual view of pipelines.
It is worth considering Azure DevOps (formerly VSTS), which provides a polished hosted solution covering Version Control, CI and Release Management scenarios.
Which Release tool should I use
Although it is possible to use a CI tool for release purposes, there is no substitute to implementing a purpose-built release tool such as Octopus Deploy or Azure DevOps (formerly VSTS). Again, check what is already in place in your organization.
The report artifacts don't render correctly in Jenkins
You will need to enable Javascript/CSS in Jenkins, by relaxing DirectoryBrowserSupport.CSP. This can be done temporarily by navigating to Jenkins/Manage Jenkins/Script Console, type System.setProperty("hudson.model.DirectoryBrowserSupport.CSP", "") into the textfield, and click Run. From now on, new builds will render correctly. For a permanent solution, edit your Jenkins.xml and append -Dhudson.model.DirectoryBrowserSupport.CSP="" to the arguments tag, making sure it's before the -jar and --httpPort switches. Be aware that there are security implications and if you are unsure you should consult your buildmaster or system administrator.
For more information, read the Jenkins documentation on this issue.
The links in the static code analysis report don't work
For security boundary reasons, browsers will not enable links that open local files (ie file:/// links). This means that the links to the .sql files referenced in the static code analysis report will not work when viewed directly from Jenkins. There are two solutions.
1) Simply download the report and open it locally. However, this can only be done on the Jenkins agent, as the source files need to be present.
2) Install an extension that relaxes the browser's rules, such as this plugin for Chrome.
Should I use "Pipelines as Code"?
We would say that if this is an option to you, it's worth considering as the following benefits are unlocked:
- Modifications to the pipeline workflow are versioned, allowing easy rollback
- There's an audit trail associated with changes to the pipeline
- Most powerful and sophisticated pipelines can be constructed
- It enables portability of the pipeline to different instances of the CI tool, or even different CI tools entirely
How do I avoid cleartext passwords in my Jenkins scripts?
Use the Jenkins Credentials Plugin to specify credentials. These can then be referenced from the Jenkinsfile.
Jenkinsfile snippet
withCredentials([usernamePassword(credentialsId: '4c03d5ac-8628-4fce-b1d1-1064a827a132', passwordVariable: 'MYPWD', usernameVariable: 'MYUSER')]) {
// the following proves that Jenkins obfuscates these credentials to asterisks:
echo "My user is '${MYUSER}'!"
echo "My password is '${MYPWD}'!"
// We pass the credentials to the batch file:
def status = bat returnStatus: true, script:"call Tools\\CI-Build.cmd ${MYUSER} ${MYPWD}"
}In this example the Jenkins output will be
My user is '****'! My password is '****'!
Which branching strategy should I use if I have a shared development database?
When using a shared development database, there can be only one state of the development database at any time, which means that all developers must be pushing to the same branch (usually called main or trunk). If developers need their own feature branches, each developer must then be given their own development database. Think about using SQL Clone for dedicated development databases. Join our Early Access Program for Redgate Clone for cloning SQL Server, PostgreSQL, MySQL, Oracle, and more.
Release branches can be created from main/trunk. For more information, check out Trunk Based Development, which also discusses release branches in more detail.
What if I have a shared development database, but it's really supporting multiple teams/applications? Can I use branches then?
It is possible for multiple teams to work against the same shared development database and commit their changes into different repositories. Each team member can setup their project to connect to the repository (or branch) for their team. When working in this model, it is important to make sure you are only checking in your changes, since all changes made to the shared development database will show up on the Check-in tab. If your application only touches a subset of the objects in the database, then use Ignore Rules in the Source Control for Oracle project settings to filter out these objects so that you're not accidentally committing someone else's changes. Object Locking also comes in handy when working on a shared development database to make sure changes are not being accidentally overwritten.
The different repos are maintained independently as they have different release cycles, and presumably different database changes need to be released at different cadences. If you are using different branches, then these branches can be merged back into the main branch to deploy all changes across all the different teams/applications at the same time.
An alternative way of structuring this would be to have a single project linking the shared development database to a single repo. You could then create release branches for A, B and C projects and cherry-pick the change from the development repo to the correct release branch (see the cherry-picking question below) using a VCS client.
When working on a shared development database, if 2 different developers/teams are making changes to the same object, then this needs to be coordinated across the teams, especially when it comes time to deploy the changes. This problem exists today even if you're not using source control.
How do I cherry-pick specific changes to deploy?
If only a subset of development changes can be released to production, then a branching mechanism could be used to manage this.
Some teams prefer to create dev/feature branches for their development work. Then, they only merge into the main branch when it's ready for release. This is usually done via a Pull Request (PR) process. The PR allows another developer to review and comment on the changes before they are accepted into the main branch for release.
Other teams do all their development on main or trunk (the branch in which all developers check in their changes) and then selectively merge the changes that are ready to be released into a release branch. The release branch then becomes the source of deployment.
How do I apply different changes against different environments or different customers?
Ideally this situation should be avoided as it adds additional complexity. However it may be necessary to apply different changes, for example customer-specific static data configuration, to different target databases.
To achieve this, logic needs to exist that applies different SQL statements depending on the target environment. This is achieved by running post-deployment scripts, either using conditional statements in the scripts, or by running a different post-deployment script depending on the target environment.
Conditional statements in a post-deployment script
An example of how this can be achieved is provided here, running different clauses depending on the target server name.
Note: Today, post-deployment scripts must be managed and applied in your scripts in addition to Redgate's comparison-based deployments. There is a roadmap item to add built-in support so the scripts can be managed within Redgate tools, and included as part of a single deployment process.
Applying different post-deployment scripts for each environment
Another method is to put the logic in your release scripts to apply a different script for each environment.
If using the Migrations approach for Oracle, this can be achieved using Flyway's -locations switch in conjunction with afterMigrate.sql callback script.
Eg, Place afterMigrate.sql in separate TargetA, TargetB and TargetC folders in your database scripts folder.
Call Flyway migrate with a different -locations swtich differently depending on the environment eg to apply different post-deploy scripts to targets, A, B and C:
flyway -url=jdbc:oracle:thin:@//<SERVER_A>:<PORT>/<SID> -user=<USER> -password=<PASS> -locations="filesystem:Database\migrationscripts, filesystem:Database\TargetA" migrate
flyway -url=jdbc:oracle:thin:@//<SERVER_B>:<PORT>/<SID> -user=<USER> -password=<PASS> -locations="filesystem:Database\migrationscripts, filesystem:Database\TargetB" migrate
flyway -url=jdbc:oracle:thin:@//<SERVER_C>:<PORT>/<SID> -user=<USER> -password=<PASS> -locations="filesystem:Database\migrationscripts, filesystem:Database\TargetC" migrate
How do I execute my .sql deployment scripts using sqlplus?
From PowerShell:
$output = "exit" | sqlplus "HR_PROD/Password@(DESCRIPTION=(ADDRESS=(PROTOCOL=TCP)(Host=localhost)(Port=1521))(CONNECT_DATA=(SID=XE)))" "@.\script.sql"
From a Windows batch file
Call exit | sqlplus HR_PROD/Password@(DESCRIPTION=(ADDRESS=(PROTOCOL=TCP)(Host=localhost)(Port=1521))(CONNECT_DATA=(SID=XE))) @.\script.sql
How do I configure Data Masker as part of my deployment pipeline?
You can use Data Masker to mask sensitive data, for example to provision environments that are periodically refreshed from production.
- Using the Data Masker user interface create a mask set, for example DataMasker.MaskSet
Edit the mask set file in order to specify relative paths report artifact locations, for example:
<AutoEmitRuleRunStatisticsReportToFile Value="True" />
<AutoEmitRuleRunStatisticsReportDirectory Value=".\Artifacts" />
<AutoEmitRuleStructureReportToFile Value="True" />
<AutoEmitRuleStructureReportDirectory Value=".\Artifacts" />Bear in mind that any folder or subfolder you reference must exist
- Check the DataMasker.MaskSet mask set into version control.
- Call Data Masker from your build scripts, passing in the mask set as an argument (dos batch file example):
start /wait "" "C:\Program Files\Red Gate\Data Masker for Oracle\DataMasker.exe" "DataMasker.MaskSet" -R -X - If you need an audit trail, archive the Data Masker reports as artifacts, for example (Jenkinsfile example):
archiveArtifacts allowEmptyArchive: true, artifacts: 'Artifacts/DataMasker*.txt'
How should I refresh my Development database from Production when working with Source Control?
If you refresh your Development database by restoring a backup of your Production database, then SQL Source Control or Source Control for Oracle may want to undo the changes you made in your Development Database since it thinks you've reverted to a previous state. Changes to your Development database need to be reapplied after the restore. You can do this by:
- Use SQL Compare or Schema Compare for Oracle to take a snapshot of the Development database
- Restore a cleansed Production database to your Development instance (for help with cleaning Production data, see Data Masker for Oracle)
- Use SQL Compare or Schema Compare for Oracle to reapply any changes from the Development snapshot to the Development database
The good news is that this can all be scripted with the SQL Compare or Schema Compare for Oracle cmdline as part of the restore process.
(If you don't take the snapshot, you could also use SQL Compare or Schema Compare for Oracle to go from your VCS repo to the Development database after the restore, but this would only capture changes committed to the repository and wouldn’t capture any uncommitted changes at the time of the restore. So best to use the snapshot technique described above, so you don’t lose any of your development work.)
Consider using SQL Clone, which is part of Redgate Deploy.
How do I provision databases for automated build or release testing?
Options are SQL Clone (currently SQL Server only), Oracle's Flashback databases, pluggable databases, or Snap Clone (CloneDB) or Docker containers. Read PDB snapshot copy for continuous integration testing by Franck Pachot for a detailed overview.
How do I generate an upgrade script between 2 revisions/versions?
If you are using the state-based approach:
- Use a VCS client to get a copy of the revision you want to update to. This scripts folder can be used as the source in the SQL Compare or Schema Compare for Oracle tool.
- Use a VCS client to get a copy of the revision you are starting from. This scripts folder can be used as the target in the SQL Compare or Schema Compare for Oracle tool.
- Use SQL Compare or Schema Compare for Oracle to compare the two script folders, see schema differences, and generate the deployment script.
- Use SQL Data Compare or Data Compre for Oracle to compte the two scripts folders, see data differences, and generate the deployment script for your static data changes.
This can all be scripted/automated using the cmdlines of your VCS system and the SQL Compare or Schema Compare for Oracle and Data Compare cmdlines.
This documentation contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved




