Roadmap
Published 09 March 2018
This roadmap covers a range of ideas at differing stages of development. As with all roadmaps, the content is fluid, estimated delivery times are subject to change, and in some cases features will pivot and even may be removed entirely. We believe strongly in working closely with our customers to evolve our solution, and therefore we encourage feedback on all aspects of the roadmap, including suggestions on what we should work on next. You are welcome to email new ideas directly to the Product Manager or alternatively suggest/vote on ideas on our UserVoice site.
In the table below, the icons represent ![]() Schema Compare for Oracle,
Schema Compare for Oracle, ![]() Data Compare for Oracle,
Data Compare for Oracle, ![]() Source Control for Oracle, and
Source Control for Oracle, and ![]() represents the automated build and release solution available exclusively as part of the Deployment Suite for Oracle.
represents the automated build and release solution available exclusively as part of the Deployment Suite for Oracle.
Product(s) impacted | ||||
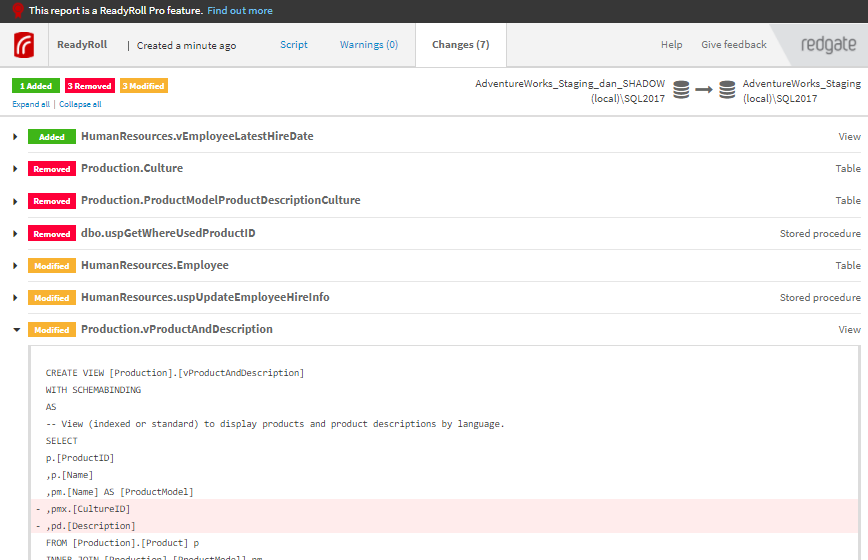
Support for migrations-based deployments - Early Access ProgramCurrently, the Redgate Oracle solution uses the "state-based" deployment methodology. The desired state of the database is stored in version control and compared to the target database at deployment time to generate the deployment script. This model was chosen to provide the lowest overhead for development teams. The state-based model works very effectively for the vast majority of changes, but there are a small number of changes that can't be inferred by a comparison engine, such as adding NOT NULL columns without a default, column/table splits/renames, transactional data updates, and other "complex" refactorings. If these changes occur, the deployment script generated by the state-based approach needs manual customization before running. If these types of changes are infrequent, this may be acceptable and using Pre/Post SQL scripts in your deployment pipeline might be fine. If these types of changes are common, it becomes a chore. This is where the migrations-based deployment methodology is arguably better suited. In this migrations model, a "migration script" (think of it as a micro-deployment script for a changeset) is saved on each checkin and stored alongside the desired state in version control. Crucially these scripts can be customized at development-time. Upon deployment, instead of generating a new script by comparing states, the deployment script is constructed from these migration scripts. A log table in the target databases keeps track of which scripts have already been applied to that database, so they only run once and don't have to be written idempotently. One downside to the migrations-based approach is the number of migrations scripts that can be generated. Our solution will feature "Programmable Objects" to treat procedures, functions, views and any "code" objects that don't impact data differently to structural changes. Instead of creating a new migration script when a programmable object is modified, the tool will simply update the "state model" and use this for the deployment. This approach vastly reduces the number of migration scripts created as part of development. Our solution will be based on the same technology as our current SQL Server technology, which is very mature and trusted. Please contact us if you are interested. Expected time-frame for release: H2 2019 |
|
|
| |
Linux-compatible command lines - Release Candidate AvailableThe use of Linux build agents (or "slaves") as part of an automated build and release process is increasing. Redgate's command lines are currently Windows-only, which necessitates separate Windows-based build agents to be spun up. With this Release Candidate, you can continue to user your existing Linux agents. Release candidate available today. Expected time-frame for release: H2 2019 |
|  | ||
Static code analysis - Preview AvailableCode analysis will reduce the number of 'code smells' that creep into your database builds and help maintain best practices, especially if database changes are made by multiple team members. This feature, implemented as a command line, would provide:
Expected time-frame for release: H2 2019 |
| |||
Find Invalid ObjectsIt can be important to understand which objects are in an invalid (uncompiled) state. This feature, implemented as a command line, would provide:
Please contact us if you are interested in finding out more. Expected time-frame: 2020 |
| |||
Improved release report artifactSchema Compare for Oracle can output a basic change report that can be used as a review/approval artifact in a release process. An improved report will include difference highlighting and deployment warnings. Expected time-frame for release: H1 2020 | ||||
Pre/Post-Deployment ScriptsOn occasion it may be desirable to run custom SQL before or after a deployment script, for example to configure server configuration settings, or to perform custom data motion. One solution is to adopt a migrations-based approach, but for teams that prefer the state-based approach, using pre/post-scripts is a pragmatic alternative. These scripts would be configurable in Source Control for Oracle, stored in a "CustomScripts" sub folder. Schema Compare would recognize the existence of these files and run them upon deployment. Expected time-frame for release: 2020 | ||||
Making the creation of multi-schema projects simplerIn Source Control for Oracle, the process of adding multiple schemas is less than optimal as described in this UserVoice post. Similarly, adding a new schema to an existing project isn't possible, requiring the entire project to be recreated from scratch. Expected time-frame for release: 2019/2020 | ||||
Better support for Shared Development DatabasesThe pros and cons of shared vs dedicated development database models are discussed in our FAQs. We support both models. For the Shared Development Database model, we already have Object Locking (as of Source Control for Oracle v2.0) to ensure your changes aren't accidentally overwritten. We're considering adding a "last changed by" column on checkin to help ensure that you checkin the correct changes that you have made (and not a change that someone else made, since these show up since you're all working on the same database). What else can we do to make working on a shared development database even easier? Or, how can we make it super easy to provision dedicated environments per developer or per feature/release branches, if this is the better way for you to go? Status: Need more user feedback. Please contact us if you are interested. | ||||
SQL Developer or other IDE integrationAn advantage of Source Control for Oracle's "connected" development paradigm, where changes to a development instance are detected and offered for checkin, is that all Oracle IDEs are "supported". It doesn't matter where or how changes are made. The Source Control for Oracle icon in the Windows Task Bar will change when a difference is detected, alerting the end user that there is a pending change to commit. Deeper integration with SQL Developer (or other IDEs) would mean that this notification is even closer to the context of the work being done. Status: Need more user feedback. Please contact us if you are interested.. | ||||


Note: The above list includes headline features and excludes improvements such as new object types and platform support.
What else should we be doing?
Please email new ideas directly to the Product Manager or alternatively suggest/vote on ideas on our UserVoice site.
Previously shipped features
This page is here. The latest release announcements can be found here.
Included here are a selection of key database DevOps improvements. For a full and comprehensive list of product release notes, including bug fixes, please consult the release note pages for the individual components.
August 2019 |
SSMS experience in SQL Change Automation 4.0SQL Change Automation version 4 allows you to create and manage migration scripts in SQL Server Management Studio. This allows teams to collaborate across Visual Studio and SSMS, and allows developers to work in their IDE of choice.
For more information, visit the SQL Change Automation release notes. |
December 2018 |
Ignore ObjectsComponent(s) impacted: Deployment Suite for Oracle 5.2.0 It is already possible to filter down the list of objects in Schema Compare for Oracle and Source Control for Oracle. However, this filter applies after the tool reads the full schema, which, if large, can be time-consuming. The new Ignore Objects feature, available across the Deployment Suite for Oracle, allows schema objects that are known to be irrelevant to be explicitly excluded from the outset, which can dramatically improve performance. For more information, see the documentation on using this feature for Schema Compare, Data Compare, or Source Control for Oracle. |
October 2018 |
Static data deployment from source controlComponent(s) impacted: Deployment Suite for Oracle 5 Source Control for Oracle v4 allowed static data to be stored in version control in csv format, which enables audit and version history as well as the sharing of changes among developers. Static data deployment takes this a step further and allows the versioned static data to be deployed alongside schema changes.
The /comparison:includeSourceTables command line switch has been added to the Data Compare for Oracle command line for cases where the target schema structure is different at the time of comparison (this would occur if you are generating schema and data deployment scripts ahead of the actual deployment step). |
Optimization of refresh behavior in Source Control for OracleComponent(s) impacted: Source Control for Oracle The project refresh mechanism has been optimized as follows:
|
September 2018 |
Rollback supportComponent(s) impacted: SQL Compare 13, SQL Change Automation 3 SQL Compare and the SQL Compare command line can now read in a SQL Change Automation project, allowing rollback scripts to be created. This can be scripted as part of a deployment pipeline, by generating a rollback script artifact based on the comparison of the production state against the SCA project. Eg, sqlcompare.exe /db1:WidgetProduction /sca2:"C:\ScaProject\ScaProject.sqlproj" /scriptFile:"Rollback.sql" |
April 2018 |
Table Mapping added to Data Compare 4Component(s) impacted: Data Compare for Oracle Improved "Tables & Views" tab dialog, with support to map tables of different names. See documentation. |
November 2017 |
Static Data supportComponent(s) impacted: Source Control for Oracle 4.05 Static data can now be checked in to version control. Data Compare for Oracle v5 will be able to deploy these static data changes against a target database. |
September 2017 |
Component(s) impacted: Source Control for Oracle SQL Compare 13 and SQL Monitor 7.1 SQL Compare now appends a logging statement at the end of the deployment script to log the deployment details to SQL Server Log in order for SQL Monitor to detect the deployment and mark it on the timeline for performance data. Note that this feature should be regarded as a preview and is therefore subject to change. This is expected to be a SQL Toolbelt-licensed feature. Find out more in this How-to guide.
|
This documentation contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved




