About Where Clauses and Sampling
Published 19 March 2018
Important Note: Be sure to be familiar with the information in the Where Clause Skip section of this help file. It contains very important information which will help you avoid a common error when implementing Where Clauses.
Where Clause and Sampling options are available for Substitution, Shuffle, Search and Replace, Row-Internal Synchronization, XML Masker and JSON Masker Rules. The Where Clause and Sampling options are used when the choice of rows to be affected by the operation is to be based on a specific criteria. Each rule type offers a variety of options - the example below is from a Substitution rule as it contains an example of all of the available configuration parameters. Other rule types may not offer all of these options
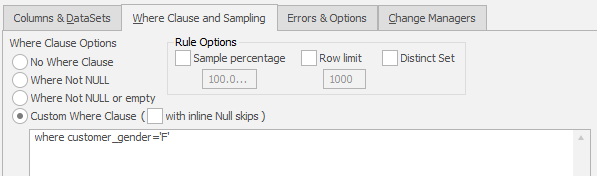
A Sample Data Masker Where Clause Options Panel
The Options
No Where Clause
If this option is chosen the rule does not use a where clause and, hence, the masking operation will be applied to all rows of the table.
Where Not NULL
If this option is selected the rule will operate only on the rows which contain a not null value in the target column. In effect this is the same as writing Where <column_name> IS NOT NULL in the Where Clause box.
Where Not NULL or Empty
If this option is selected the rule will operate only on the rows which contain a non blank value in the target column. In effect this is the same as writing Where <column_name> IS NOT NULL or <column_name> != '' in the Where Clause box. Since Oracle databases don't have the concept of empty text field, this option doesn't exist on Oracle version.
Custom Where Clause
This option enables the Where Clause box and appends the user specified contents to the rule. Any where clause which would be acceptable appended to a SQL query run interactively on the command line is usable here. This includes the use of function calls, joins to other tables and correlated sub-queries. In particular, note the use of the alias DM1 on the table name in the Pseudo Code field. This means that the the target table can be referenced by the alias and used in Join conditions within the contents of the Where Clause. The Data Masker support team would be happy to provide advice and assistance should you have questions regarding the implementation of Where Clauses on a masking rule.
Sample Percentage (only available on some rule types)
Sometimes it is desirable to apply the masking operations of the rule only to a sample of the values in the table. This option enables that feature. Note that very small percentage values can be specified here - for example a percentage of 0.001 could be specified to apply the masking operations to 10000 rows in a million row table. The percentage is always taken on the total number of rows returned by the Where Clause (if applied) and it is a true random percentage. For example a percentage of 25 with no Where Clause would operate on a random set of rows throughout the complete table - not on the top quarter of the table or on exactly every fourth row.
Row Limit (only available on some rule types)
Occasionally it is desirable to cap the number of rows operated on by the rule to a certain amount. This option enables an upper bound limit to be placed on the rule. If enabled, on the specified number of rows will be masked with the rule and the rest will be ignored.
Distinct Set (only available on some rule types)
This option forces a distinct set of rows (with no duplicates) to be selected by the Where Clause. This option is sometimes necessary when a complex join is configured in the Custom Where Clause box. Normally the Distinct Set option is not enabled and you should probably consult with the Data Masker Support Team before implementing a rule using it.
Where Clause Skips
When masking data using Where Clauses there is an important source of error which must be noted. This issue is associated with the mistake of making implicit assumptions regarding the contents of the field on which the Where Clause operates.
For example, if masking operations were to be applied to the FIRST_NAME column of the EMPLOYEE table the relevance of the column could be preserved by substituting female and male names where appropriate. All female first names in the table could be substituted by choosing the Names, First Names, Female dataset and using a Where Clause of WHERE EMP_GENDER='F'. This would cause only the female employee records to be selected and masked. A separate rule using the Names, First Names, Male dataset and a second Where clause of WHERE EMP_GENDER='M' might be used to perform a similar substitution on the male entries.
However, there is potentially a BIG problem with the above solution!
In the example above, two rules with two Where Clauses were applied to the target table. It is important to realize that if there are EMP_GENDER values in the target table which are not equal to either M or F then the FIRST_NAME fields associated with these values will NOT be masked. This effect is called a Where Clause Skip and is discussed in more detail in the Data Masking: What You Need to Know Before You Begin white paper. In such cases, a masking rule with a default value is usually applied to the columns in the target table before the update with the Where Clause takes place.
A better solution, using the above example, would implement a Substitution rule using the Names, First Names, Female dataset without a Where Clause to mask all of the FIRST_NAME fields with female first names (irregardless of gender) then a second rule with a Where Clause of WHERE EMP_GENDER='M' and the Names, First Names, Male dataset could be used to mask just the male names. This two step method, causes some rows (the male ones) to be masked twice but also ensures that all rows of sensitive data in the target table get some form of masking. This avoids the need to specifically target each case with a Where Clause and also future proofs the masking rule so that if any new values appear in the EMP_GENDER field in the future, the FIRST_NAME field will still automatically be rendered anonymous without any changes to the masking rules. Note that the execution order of the rules is critical in the two-step process just described. It is not valid to have both rules run simultaneously. To control the execution order use Rule Blocks and Dependencies.
This documentation contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved




