Suggested Rules for the DMTest Sample Database
Published 19 March 2018
The Data Masker software contains a set of masking rules for the sample DMTest database supplied with the Data Masker software. The scripts to build and populate this database can be found in the SampleDatabase subdirectory. You are encouraged to add your own masking rules to this masking set. The first section of this page discusses the existing rules (as supplied with the installation) and the second part provides some hints of additional rules which might be added. As you read this page you might find it useful to refer to the DMTest database ER diagram.
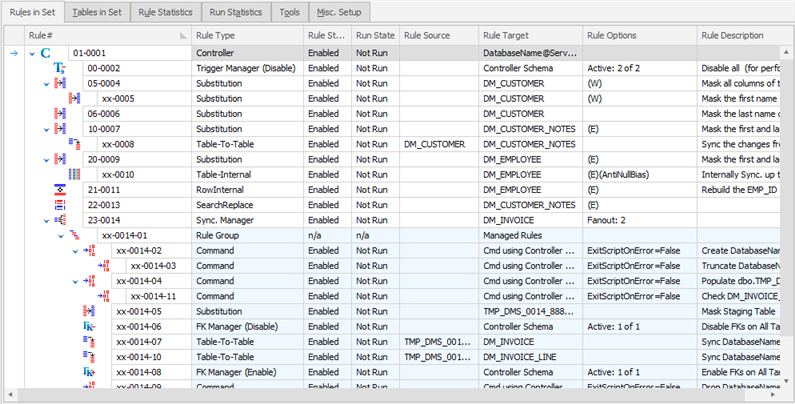
Masking Rules in the Sample DMTest Masking Set
The Existing Rules
If you wish to explore each rule further, load the masking set into the Data Masker software and double click on the rule with the mouse to launch it into editing mode. You can then explore the rules configuration in detail.
Rule 01-0001
This is a Rule Controller. Notice how the other rules are dependent on it. A Rule Controller defines the database on which the other masking rules will act. If you change the login information in the Rule Controller its rules will operate on the new database. It is up to you to ensure that the Rule Controller points at an appropriate SQL Server instance and database. All other types of masking rule must have a parent Rule Controller and every masking set must contain at least one Rule Controller.
Rule 01-0002
A Trigger Manager Rule on the DMTest database. If update triggers are enabled on the table during masking operations, the effect can be a dramatic slow down in execution speed. In this example it was determined that it was not necessary for the triggers to fire during the masking process as they update history and stats tables which will not be required in the masked test system. Rule 01-0002 disables the triggers and its companion, Trigger Manager Rule 99-0003, will re-enable the triggers again after the masking rules execute.
Rules 04-0004 and xx-0005
A group of Substitution Rules on the CUSTOMER_FIRSTNAME column in the DM_CUSTOMER table. These rules form a pair: Rule 01-0004 masks the CUSTOMER_FIRSTNAME field in all rows in the table using the Male First Names dataset. Then rule xx-0005 goes back over the same data and replaces the female first names with values from the Female First Names dataset. A Where Clause on rule xx-0005 restricts the update values to rows which match where customer_gender='F'.
Important Point: The motivation underlying this two-stage mechanism is a particularly important concept to grasp. If the rules were implemented so that both rules had a Where Clause (one for M and one for F) then any row with a CUSTOMER_GENDER of NULL would not get masked. This is called a Where Clause Skip and is discussed in the Data Masking: What You Need to Know Before You Begin white paper. You are strongly advised to read this white paper - it covers a number of very subtle issues. As the rules 01-0004 and xx-0005 are configured in the sample masking set, every CUSTOMER_FIRSTNAME gets masked with some value (rule 01-0004) and then a second rule is applied (rule xx-0005) to reconcile names with appropriate genders.
Note that we cannot permit rules 01-0004 and xx-0005 to run simultaneously. In this case, since the two rules are part of the same operation on the same column it was decided to make rule xx-0005 dependent on rule 01-0004. The dependency relationship means that rule xx-0005 will not execute until rule 01-0004 has completed. The rule execution order could also have been controlled via the rule block mechanism. If you do not understand Rule Blocks and Dependencies it is highly advised that you read the Rule Blocks and Dependencies help page to better understand how to explicitly control the execution order of the masking rules. It would also be useful to review the discussion of rules 0005 and 0006 in the Suggested Rules for the PUBS Database help page.
Rule 06-0006
A Substitution Rule on the DM_CUSTOMER table. This rule masks the CUSTOMER_LASTNAME column with the Random Surnames dataset.
Rules 10-0007 and xx-0008
The DM_CUSTOMER_NOTES table contains two columns CUSTOMER_LASTNAME and CUSTOMER_FIRSTNAME which are also present in the DM_CUSTOMER table. Masking denormalized data such as this is not an uncommon requirement. The CUSTOMER_LASTNAME and CUSTOMER_FIRSTNAME columns must be synchronized with the values masked by rules 0004, 0005 and 0006 in the DM_CUSTOMER table. The join condition between the DM_CUSTOMER_NOTES and DM_CUSTOMER table is the CUSTOMER_ID column - this is the condition which identifies which rows are associated with each other.
A Table-To-Table Synchronization rule (rule xx-0008) is used to perform the synchronization. The Table-To-Table Sync rule will take the CUSTOMER_LASTNAME and CUSTOMER_FIRSTNAME values from the DM_CUSTOMER table and update the appropriate rows in the DM_CUSTOMER_NOTES table Where the CUSTOMER_ID values are identical.
Important Point: Note that if there are rows in the DM_CUSTOMER_NOTES table with CUSTOMER_ID values which are not present in the DM_CUSTOMER table then the Table-To-Table Synchronization rule will not update them and they will be unmasked. Accordingly, the masking procedure is implemented as a pair of rules. The motivation is similar to that used for rules 0004 and 0005. The leading Substitution rule (rule 10-0007) updates the target columns in every row in the DM_CUSTOMER_NOTES table with dummy values. This ensures that all columns get masked and only then does the dependent Table-To-Table Synchronization rule perform the synchronization. Because of rule 10-0007, it is not a problem if rule xx-0008 does not operate on all rows in the DM_CUSTOMER_NOTES table. The data fields are sure to have been masked by the preceding rule 10-0007.
Important Point: Also note that rule 0007 has been placed in rule block 10. This is the "10" in the complete rule ID of 10-0007. This rule block configuration is necessary because there are previous rules (0004, 0005 and 0006) which update the fields in the DM_CUSTOMER table we are trying to synchronize. These rules must complete first and since they are in a lower rule block we know they will finish executing before any higher rule blocks begin. If you do not understand Rule Blocks and Dependencies it is highly advised that you read the Rule Blocks and Dependencies help page to better understand how to explicitly control the execution order of the masking rules.
Rule 20-0009
A Substitution Rule on the DM_EMPLOYEE table. This rule masks the FIRST_NAME column with the Male And Female First Names dataset and the LAST_NAME column with the Random Surnames dataset.
Rule xx-0010
The DM_EMPLOYEE table exhibits a less common form of denormalization - each time an employee changes an assignment they receive a new record in the DM_EMPLOYEE table. This means that for any one PERSON_ID (which identifies a unique person) there can be multiple rows in the DM_EMPLOYEE table. Since rule 20-0009 changes the names to random values, it is required that the personal information be synchronized so, that for every identical PERSON_ID, each row has the same FIRST_NAME and LAST_NAME. If this is not done, the data in the masked database will appear to indicate that each time the person changed an assignment they also changed their name. This requirement is called Table-Internal synchronization and it is handled by a Table-Internal Synchronization Rule on the DM_EMPLOYEE table. It is advisable to double click on this rule and observe how it is configured. It is also useful to disable this rule and run the masking set to see the before and after effect. Note that this rule is dependent on rule 20-0009 so that it runs after that rule completes.
Rule 21-0011
The EMP_ID column in the DM_EMPLOYEE table contains a leading alphabetic code built out of the first three characters of the employees surname. This Row-Internal Synchronization Rule builds a new value for the EMP_ID which corresponds to the newly masked LAST_NAME. It would be a good idea to double click on this rule to observe how it is configured. Note that this rule has been placed in rule block 30 so that it executes after the rules which update and row-internally synchronize the columns in the DM_EMPLOYEE table.
Rule 22-0013
The CUSTOMER_NOTE column in the DM_CUSTOMER table can contain free text. Let's assume that we know that people put in their notes names and phone numbers to call some customer at a certain time. This Search-Replace Rule builds a new phone number and names by finding them. This is the reason why you need to define a search pattern. In an example, there are defined two patterns for two replacement one for the phone number (regex replace) and for the names (dictionary replace). As you can see the first one defines regex pattern to match predicted phone number format and replaces all occurrences with hard-coded text "(phone#masked)". Dictionary replacement finds names defined from the multiple datasets and replaces with a hard-coded text "XXXX".
Rule 23-0014
The Sync Manager is responsible for synchronization of ceratin columns between multiple tables. In our database, we've got invoice_number which is in DM_INVOICE and DM_INVOICE_LINE tables. Invoice number is personal sensitive data, so we want to substitute it, but moreover, for database consistency, we want to substitute its values in all relevant places. For that reason, we are using the Sync Manager, which provides a template to do so. Please keep in my mind, that Sync Manager is converted from simpler rules and can't be added directly through adding new rule button.
As you can see Sync Manager is built from the smaller simple rule. Here is a structure with associated rule
- Command to create a temporary table with ID, original value, value to change (xx-0014-02 & xx-0014-03)
- Fill the temporary table with original data (xx-0014-03)
- Substitute value to change column (xx-0014-05)
- Disable FK (xx-0014-06)
- Synchronize invoice_number in DM_INVOICE (xx-0014-07)
- Synchronize invoice_number in DM_INVOICE_LINE (xx-0014-10)
- Enable FK (xx-0014-08)
- Delete temporary table (xx-0014-09)
Rule 98-0012
A Command Rule which truncates the DM_INVOICE_LINE_HISTORY table. It was decided that none of the historical data would be required in the masked database so this command removes it. It would be useful to double click on this rule to observe how it is configured.
Rule 99-0003
A companion Trigger Manager Rule for rule 01-0002. This rule re-enables the triggers again after the other masking rules complete. Note that this rule is in rule block 99. It is only the higher rule block value that causes it to execute after the other masking rules. If the rule block was changed to a value lower than other masking rules it would execute before those rules. If you do not understand the concept of rule blocks it is highly recommended that you read the Rule Blocks and Dependencies help page to better understand how to explicitly control the execution order of the masking rules.
Additional Rules
Below are some suggestions for additional rules which can be added to the DMTest database sample masking set. An ER diagram for DMTest is available to assist you in your analysis of the database structure. If you do add new masking rules it is a good idea to save the modified masking set under a new name - that way if you upgrade the Data Masker software you will not overwrite your enhancements.
DM_CUSTOMER:...
Examine the remaining columns in DM_CUSTOMER table and make decisions about which ones contain sensitive information and implement suitable Substitution Rules for them. Note that there are pre-built datasets for nearly all columns in this table including such items as email addresses and zip codes. Set the CUSTOMER_CREDIT_CARD_NUMBER field to appropriate values using Where Clauses on the CREDIT_CARD_TYPE_ID column and use the various credit card number datasets. Take care to mask all of the values and avoid a Where Clause Skip. See the discussion above regarding rules 0004 and 0005 for a method of ensuring all rows get masked.
DM_CUSTOMER_NOTES:customer_note
The DM_CUSTOMER_NOTES table has a field named CUSTOMER_NOTE which contains sensitive free format text. Replace these values (Where they are not already null) with random text using the Paragraphs of Gibberish dataset.
DM_EMPLOYEE:birth_date
In a small organization, a birth date can be a unique identifier. Use the Date Variance dataset to vary the BIRTH_DATE column of the DM_EMPLOYEE table by random values in a range of +/- 60 days.
DM_EMPLOYEE:first_name
The FIRST_NAME column of the DM_EMPLOYEE table is currently masked with a combined Male and Female Firstnames dataset. This is probably not appropriate since the GENDER column is available to indicate which rows should receive male or female first names. Disable rule 20-0009 so that it no longer modifies the FIRST_NAME column and add some new rules (using the techniques outlined in rules 0004 and 0005 above) to implement gender-specific names. Take care to use dependencies and rule blocks to ensure that the synchronization rules (0010 and 0011) execute after the name fields are masked. To remove a rule dependency just drag and drop the dependent rule onto the Rule Controller.
DM_EMPLOYEE:full_name
The FULL_NAME column of the DM_EMPLOYEE table contains a composite name. Implement an appropriate rule (hint: look at rule 30-0011) and concatenate the first and last names together so that the FULL_NAME column is synchronized with the masked data. Use rule blocks or dependencies to ensure the new synchronization rule executes at an appropriate point in the masking set.
DM_ASSIGNMENT:emp_id
The EMP_ID column of the DM_ASSIGNMENT table needs to be synchronized with the masked values in the DM_EMPLOYEE table. Implement an appropriate synchronization rule to ensure the appropriate rows have matching values. Note that the join condition here is a composite key of both PERSON_ID and ASSIGNMENT_ID. Use rule blocks or dependencies to ensure the new synchronization rule executes at an appropriate point in the masking set and be sure to make sure all EMP_ID values in the DM_ASSIGNMENT table get some form of masking. There are rows in the DM_ASSIGNMENT which do not exist in the DM_EMPLOYEE table so you cannot rely on synchronization alone to completely mask the data. See the discussion surrounding rules 0007 and 0008 for more information.
DM_EMP_AUDIT:...
Implement a Command rule which truncates the DM_EMP_AUDIT table. Place it in the same rule block as rule 98-0012.
This documentation contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved




