Data Scanning
Published 14 June 2021
In order to use data scanning, the login used for the instance being scanned will need to be granted db_datareader permissions.
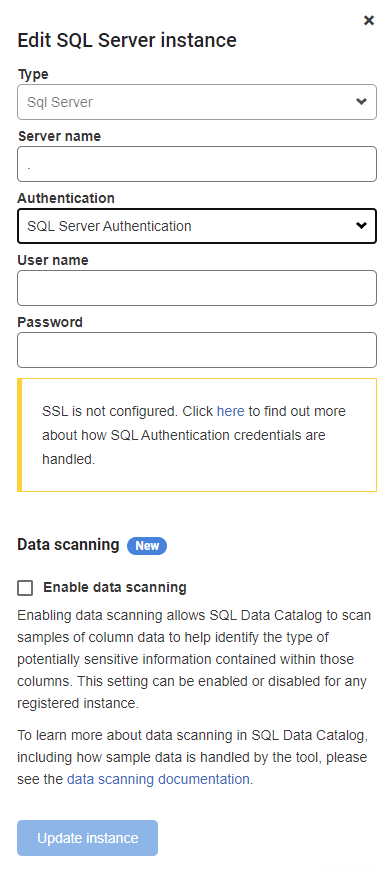
SQL Data Catalog v1.12 introduces data scanning. If enabled, SQL Data Catalog will inspect a sample of the data in each column to predict the information type contained within that column. You can enable Data Scanning on a per-instance basis by editing the instance:
Your data is safe
We know allowing third party software to have access to your data is a big concern. However, SQL Data Catalog does all of its predictions on your infrastructure. It never stores any data used to make predictions, and never sends your data back to Redgate. If you have any further security questions or concerns, please reach out to us and we will be happy to help.
Server performance
We know the performance of the servers in your estate is a vital concern. We've built the data scanning feature to have as small an impact as possible on your estate. The queries that sample data run in batches, so there are never more than 5 queries running at once. Because of this, instances can continue running at peak performance. However, large instances may take a while to scan.
How it works
Classifiers
SQL Data Catalog tries to predict as many information types from our taxonomy as possible. However, we are not able to predict certain types of information. For example, just by looking at a date we're not able to distinguish whether it's a birth date or invoice date.
SQL Data Catalog version 2.0.40 introduced support for customizing the data scanning rules. Learn more about creating your own.
We are currently able to identify:
- Bank Account Numbers (IBAN)
- Cities
- Countries
- Counties
- Debit/credit card expiry dates
- Debit/credit card numbers
- E-mail addresses
- Family (last) names
- Full names
- Genders
- Given (first) names
- Nationalities
- Occupations
- Organization names
- Phone numbers
- Social Security number (US) and National Insurance number (UK)
- Titles
- URLs
- US States
- ZIP codes (US and UK)
Usage
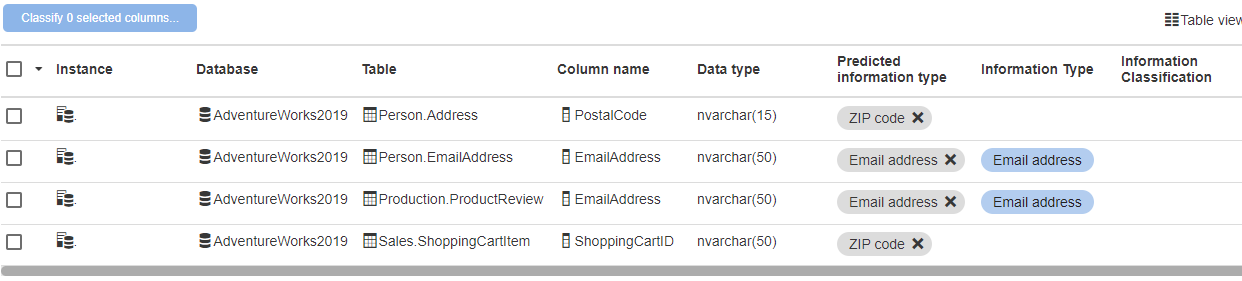
Once enabled, SQL Data Catalog will run queries against your registered instances to identify potentially sensitive columns. These predictions are then accessible in the main Classification view:
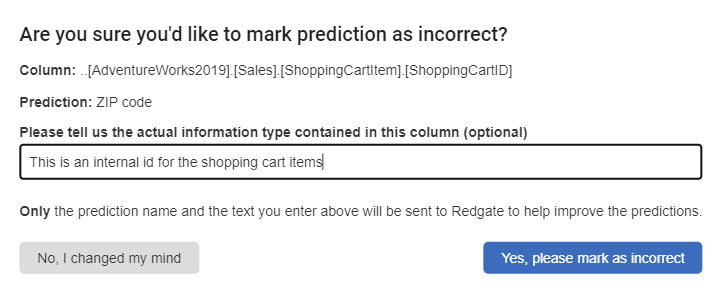
If a prediction is not correct, you can reject it. You're given the option to tell us why the prediction was wrong, which will help us improve the feature.
This walkthrough only begins to scratch the surface of data scanning. It’s not always easy to guess the contents of a column based on its name alone. Scarier still, it's sometimes quite easy to guess the wrong thing. Data scanning helps you classify more accurately by looking at the underlying data.
This documentation contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved




