Using Clones to Automate Build and Deployment of Complex Databases
Published 17 September 2020
Clones 'unlock' DevOps processes for complex or legacy databases
This automation requires use of SQL Change Automation for database development projects. For more information see: Using a SQL Clone image as a baseline
Overcoming database build blockers
A cornerstone of database development cycle is regularly "verifying the build". You make sure you can build the new version of the database, from the source scripts stored in source control. There are numerous problems that can cause a build to fail, and raise errors, and the earlier you can catch these, eradicate them, and introduce tests to ensure they don't recur, the better.
For example, you may have cases where one database object (such as a view) references other objects (such as a table) that doesn't exist, or can't be found in the referenced schema, perhaps because it was renamed or moved. SQL Server checks these references when it executes the CREATE or ALTER statement, in the build script, and will raise an "invalid object" error on the referencing object (the view, in this example), if the referenced object doesn't exist. You'll also see this error if you are trying to build a database containing references to objects in one of more different databases to which you don't have access. Even if you have access to all the dependent databases, there might be mutual, or circular, dependencies between them, so that whichever one you build first, there is an error.
Of course, generally speaking if you have build failures caused by these sorts of problems, you need to find the cause and fix it! For example:
- You can Find invalid objects using SQL Prompt.
- To build a database with mutual, or circular, dependencies to other databases on the same server, you can create 'stub' objects . See the Product article: Database Build Blockers: Mutually Dependent Databases
- You can use synonyms if the references are cross-server, to ensure the build succeeds. See: Database Build Blockers: Cross-Server Database Dependencies
However, for large and complex legacy databases, with years of accumulation of problems that will likely cause build failures, including cross-database and cross-server dependencies, these fixes or workarounds are hard, time consuming, or simply impossible.
Builds problems in SQL Change Automation Projects
If you're developing complex, legacy databases using the SQL Change Automation for SSMS, your progress can be 'blocked' quite quickly, if such issues exist. SQL Change Automaton creates a reference database, called a shadow database, in order to verify migration scripts (and builds). When you first create a SQL Change Automation project, it will generally create a build script that describes the 'starting state' or 'baseline' for the project, and then run it to build the shadow database. Ideally, this baseline script will represent the schema of the database to which you'll be eventually deploying changes (otherwise SCA will create the shadow database from a build script for the development database).
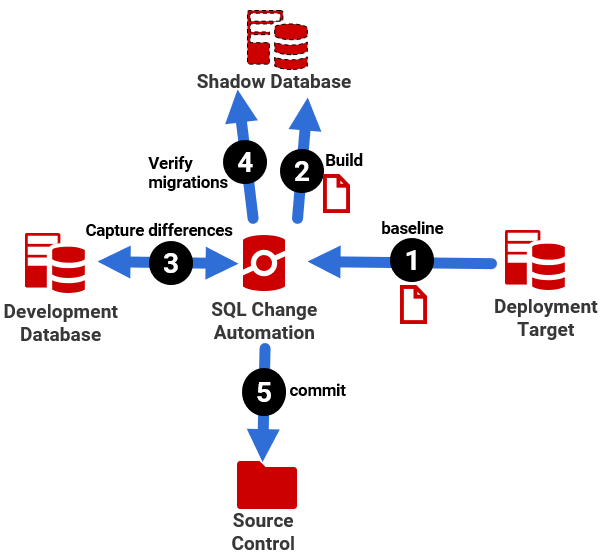
If there are any reasons why this build script won't run, such as because it include 'invalid object' references, then SQL Change Automation won't be able to create the shadow database (step 2), and you won't be able to proceed until this is resolved.
Use a clone as a 'baseline' for a SQL Change Automation project
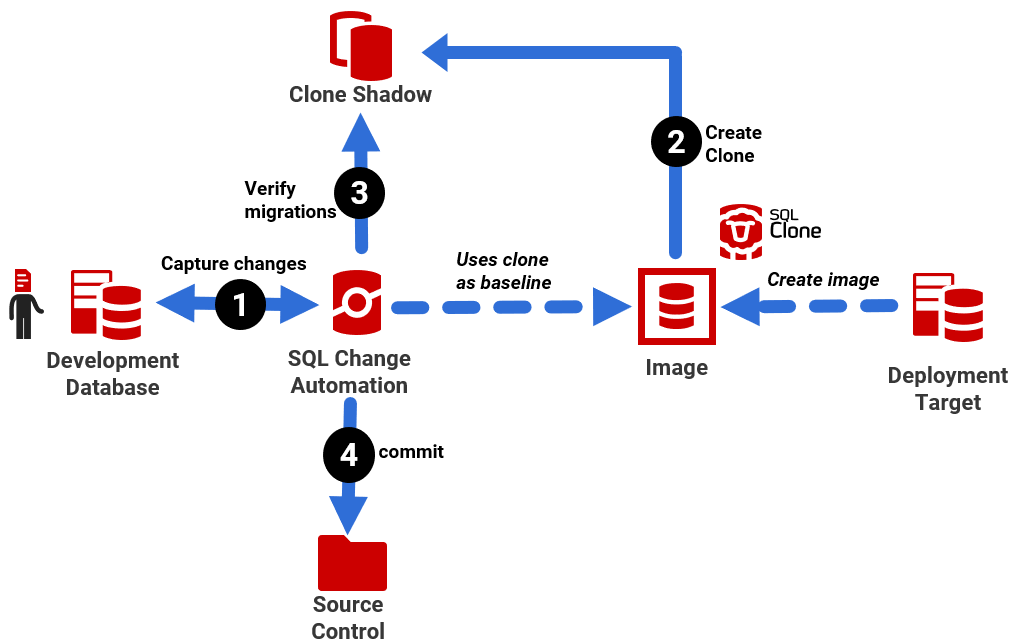
If you can't fix or remove the broken references, and you're using SQL Clone alongside the SQL Change Automation plugin for SSMS, you have an easy way around these problems: you can use a clone of the target database as the 'baseline' for the project. Instead of SQL Change Automation needing to build a copy of the shadow database from a baseline script, it can simply verify migration scripts on a fully functioning, "warts and all" clone, complete with data.
To use a clone as a baseline, you simply enter the name and location the source image for the clones. Then, each time you request to verify the migration scripts for all your latest development changes, SQL Change Automation will recreate the shadow database as a clone, deploy all the migration scripts to the shadow database to ensure they all succeed. If so, you can commit the changes to version control.
This documentation contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved




