Automatic cloning for Git branches
Published 17 September 2020
Seamlessly collaborate on different branches of database development
This automation requires use of SQL Change Automation and Git hooks, as well as SQL Clone.
In order to work on and test databases for different branches of work, in source control, it requires the developer to create multiple local copies of the database, in development, each one named differently, according to the branch for which it was created. In the scheme suggested in Using clones for branch-based development and testing, the team create a clone for each branch, named according to that branch. To switch branches requires creating a fresh clone of the current build then running on it the migration script for that branch. It would also require care to ensure that each clone's changes always went to the correct branch in source control.
In SQL Change Automation (SCA), the logical connection from the SCA project in the source control repository, to the development database is defined by the database name. If your project is connected to the main branch (with an associated clone called MyClone), and then you switch to the Hotfix branch (with a clone called MyClone_Hoffix), the SCA project will now reflect the Hotfix branch but it will still be connected to the clone for main, meaning the branch and its database are out-of-sync.
However, when combining SQL Change Automation, git hooks and SQL Clone, the team can develop the database using a SQL Change Automation project, with a git hook that invokes SQL Clone, which will then create, swap and synchronize the clones, automatically, for each branch.
How to get started with automatic branch switching
You can find a full demo of how it works in the following Redgate Product Learning article: Getting Started with Automatic Database Branch Switching.
You can find all the setup details here: Git hooks. Briefly, it relies on a simple Git hook called post-checkout, which is invoked immediately after the Git checkout command is issued, to switch to a different branch, or to create a new branch and switch to it, in a single step. The hook script simply opens a PowerShell session and executes a clone-branch.ps1 script, which we also provide. This PowerShell script uses the SQL Clone API to create a dedicated development database, a clone (called MyClone, say), specifically for the current branch (main, for example). It applies any commits in that branch that don’t exist in the clone, so that it represents the exact state of the branch.
A developer can make changes to MyClone and commit them to main, and then switch to a different branch, such as the Hotfix branch. This invokes the Git hook, and SQL Clone saves a copy of the clone for the main branch (it renames it, let’s say to MyClone_main), creates a new clone for the Hotfix branch called MyClone and aligns its state with the state of the Hotfix branch. When the developer switches back to the main branch, SQL Clone saves a copy of the clone for the Hotfix branch (MyClone_hotfix) and renames MyClone_main back to MyClone, where all the developer’s committed changes on that branch, and all the data, will be preserved.
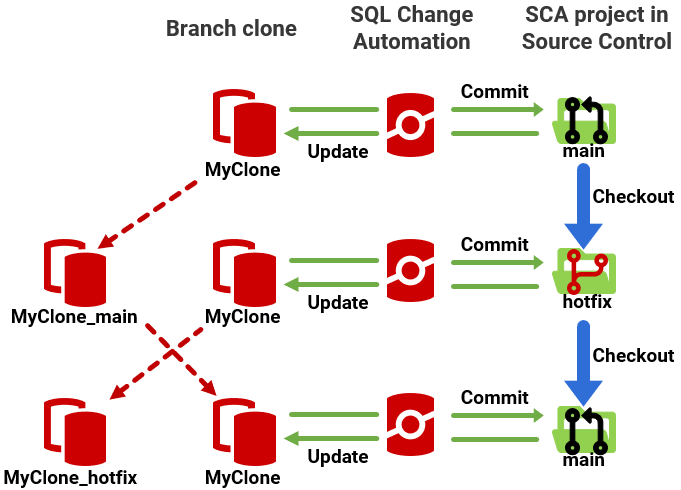
By persisting the name of a database, the same database connection string will be available regardless of which branch you’re on. This means you don’t need to reconfigure your application code depending on which branch you’re on.
This documentation contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved




