Redgate Test Data Manager Implementation Checklist
Published 28 February 2024
Overview
This checklist guides new users through setting up and deploying Redgate Test Data Manager for a successful Proof of Concept (PoC).
Our product includes a user-friendly GUI along with powerful CLI tools including anonymize and subsetting.
Before You Start: What you need to know
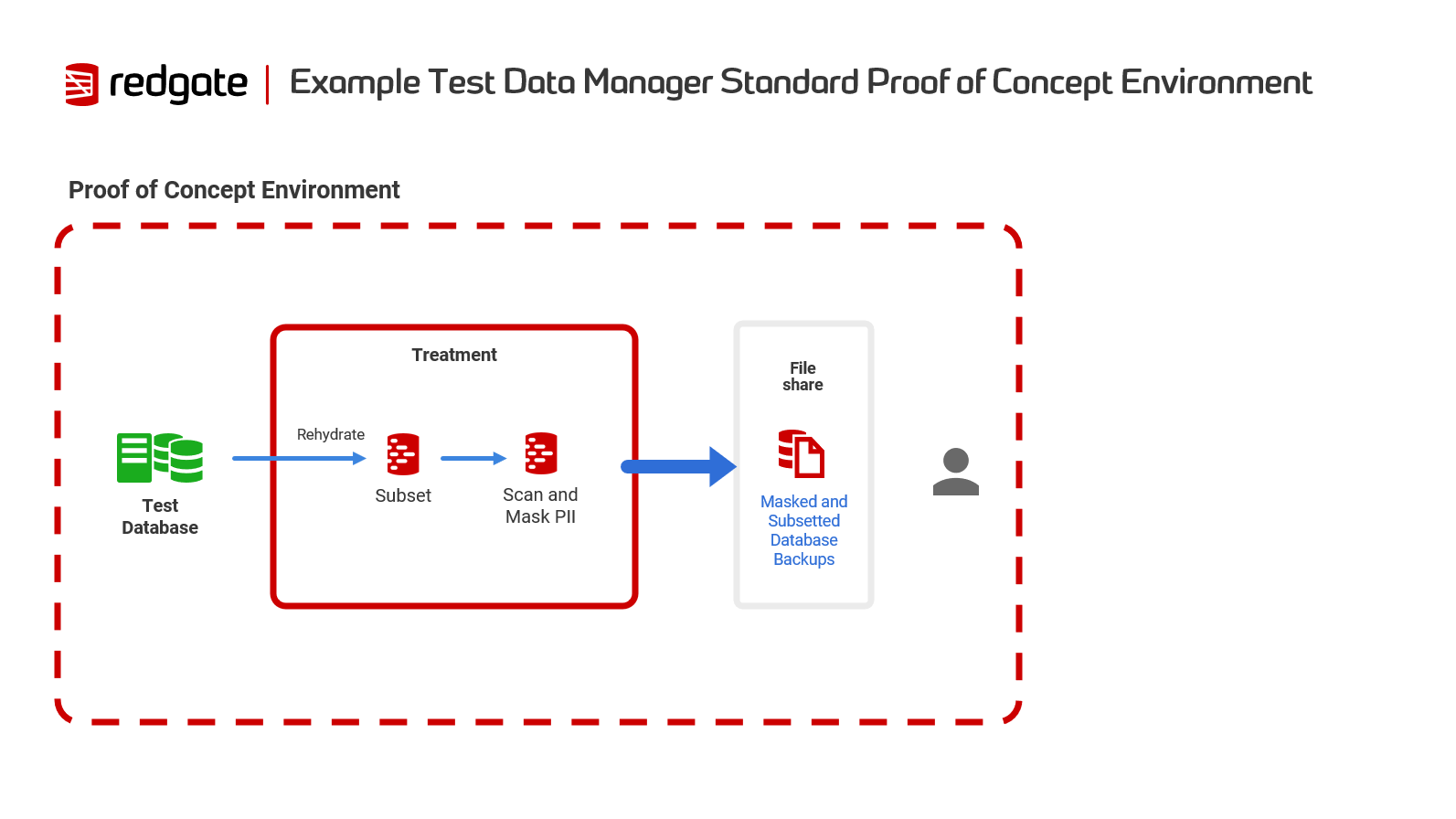
- Test Environment: Use a dedicated test environment to keep live data safe similar to the proof of concept environment below.
- System Requirements: Make sure your system meets our minimum requirements in the installation guides here for a smooth setup. And check out some suggested set up tips in our architecture diagrams.
- Check Foreign Key Relationships: Subset requires Foreign Key relationships. We've created some scripts to help you identify FK links across your database.
- Redgate University Courses: For videos and top tips from the experts, take a look at our Test Data Manager courses on Redgate University.
Installation Overview
GUI Installation
Complete GUI Installation Guide - Follow our step-by-step guide that covers:
- Hardware and software requirements
- Installation procedure with screenshots
- Initial configuration and testing
Command Line Installation
For automation, scripting, and CI/CD integration
- Anonymize: For installation and initial setup of the Anonymize tool, refer to this link.
- Subsetting: Installation instructions for the Subsetting tool and requirements.
- Download links
Getting Started
Using the GUI
The Test Data Manager GUI provides visual workflows for subsetting and anonymization.
For subsetting, you'll need to prepare source and target databases. See create an empty target database for guidance.
Using the Command Line
For automation and scripting workflows
Subsetting
Getting Started with the Subset CLI - Create your first subset
Anonymize
For a step by step guide to Anonymize, check out our Worked Example.
For more details and advanced configuration options, refer to the Anonymize command line reference.
Next Steps
- Learn More:
- Dive deeper into Test Data Manager by exploring our Redgate University videos for comprehensive tutorials and demonstrations.
- Explore Individual Capabilities:
Discover the full potential of Test Data Manager by visiting our dedicated pages for each key feature:




