Unit Testing and Integration Testing with Clones
Published 03 November 2020
Unit and integration testing with clones will increase database code quality
Our database tests must prove that the database always meets the requirements defined by the tests, that the individual units of code always function as predicted, that all the required units work together properly, to implement business processes, that the database performs and scales to requirements, and conforms to all security requirements. We need to automate these tests, as far as is possible, and perform them continuously throughout development.
Unit tests
Unit tests are performed on each routine, in isolation, to ensure that it returns a predictable result for each specific set of inputs that is used. They are required for all modules, such as procedures, functions, views and rules
– Testing Databases: What’s Required?
Imagine, for example, that you are developing SQL code for the part of a business process that amends a customer’s details. You need to start from a pristine copy of the database with a ‘known’ dataset and state, amend the customer’s data, run a test to make sure the result is exactly as expected, and then revert quickly to the original state, ready to make the next change and run the next test. SQL Clone makes this very easy to do.
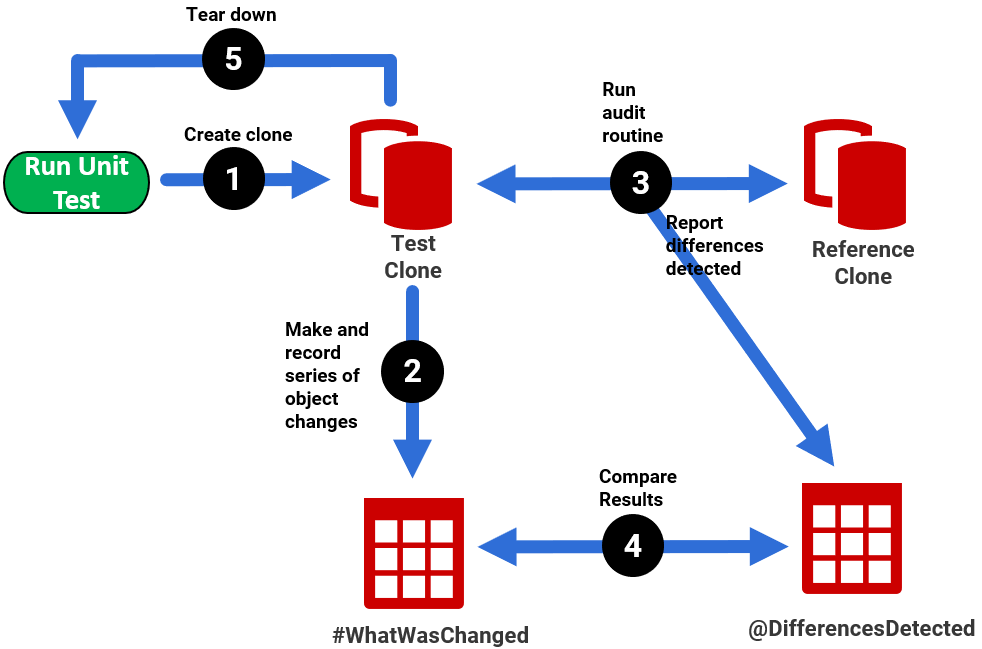
Or, let's say you are working on an audit routine to record all objects that had been added, modified or removed, in a set of databases. The unit test would require two database copies, the "test" copy on which you'd run some sample modifications, and a reference copy. The hard part to get used to for many developers is the idea that with clones, these databases are disposable resources with short life cycles. Our test can spin up a Test clone, run the test then tear it down again, ready to start the next test.
So, the unit test for our audit routine example might, when using clones, work like this:
- Create the Test clone
- Make a series of schema changes to the Test clone, recording in a #WhatHasHappened table, for each change, the affected object and the action taken
- Run the audit routine, comparing the sys.objects metadata in the Test and Reference clones and reporting the differences (in the same format as in #WhatHasHappened)
- Compare the recorded and reported differences. If there are none, the test passes.
- Tear down (remove/reset the clone)
A tool like SQL Change Automation can bundle some of these tests directly into the build process. For example, it can check for SQL code issues and run unit tests. These tests must be saved alongside the code.
See the Product article, SQL Clone for Unit Testing Databases, for a worked example of how to automate these tests, using PowerShell.
Integration and regression tests
Integration and regression tests run on every identifiable process, rather than individual object. They will validate that a set of objects work together, and the interfaces between them are correctly configured and deployed, so that that they always perform the required process and produce the expected result. – Testing Databases: What’s Required?
A typical integration test will check a specific business process, end-to-end. Each test needs to start from a known database version, with a known dataset. The test data should be realistic businesses data that conforms to experience but changes as little as possible because it must be cross-checked by the business to make sure of the validity of the result.
You will then run the entire process and check the data against a criterion that represents the correct result. For example, when testing the purchase of an item in a ‘basket’, you will set up integration tests to prove that every part of the purchasing process works, as defined by the business, and all appropriate tables are updated as expected. Having done that, you need to revert the database to its original state. Because you are likely to run all this as a scripted overnight process, you need to be able to revert automatically, maybe several times in a test run.
These automated integration tests will verify that business rules are obeyed. You have to keep adding these to the test bed, as you build new functionality, so that they also check for regressions (the re-emergence of problems you already know about. Whichever way one automates the integration tests, the results of the tests should be quickly and easily summarized and reported so that developers can quickly be alerted of any issues.
For these requirement, using clones is ideal. Once the build succeeds, you will first produce clones for the automated integration tests, Since spinning up multiple clones of the same database version is so fast, you can then run these tests in parallel, if required. If these tests pass then you create the development clones, as depicted in Provisioning development with the latest build using clones.
This documentation contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved




