The New Masking Rule Form
Published 22 March 2018
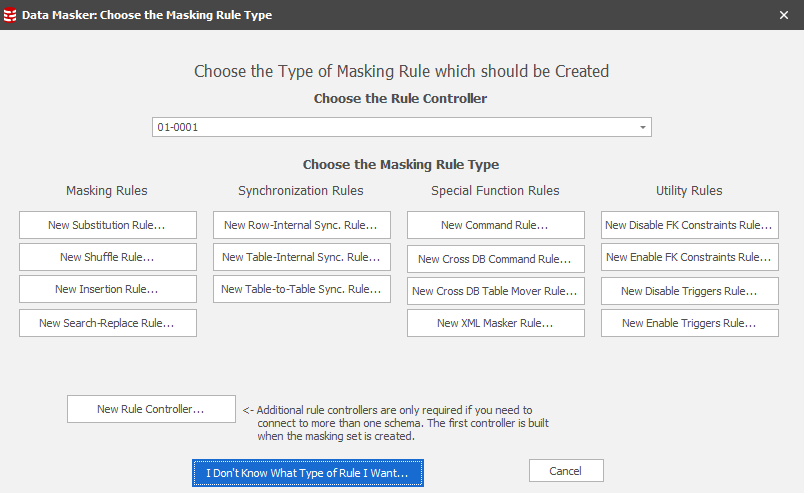
The Data Masker New Masking Rule Form
There are a number of documents and help files which will help you learn about the Data Masker software. The About Masking Rules discusses the various masking rules in detail and the Datasets help page provides an overview of the supplied sets of replacement data. The Quick Start Guide is a really useful step-by-step introduction to the Data Masker software.
Important Note: The Data Masker software is multi-threaded and will run multiple rules simultaneously. This is not always appropriate - it often happens that some rules must not start until other rules have completed. Be sure to use rule blocks and dependencies in order to control the execution sequence of the rules you create.
The Data Masker Support team is always happy to provide advice and assistance (yes, even for an evaluation copy). If you need help please email us at support@red-gate.com.
All operations performed by the Data Masker software are specified in the form of rules, called masking rules, which dictate the actions taken. In order to choose the appropriate type of masking rule for a particular task it is essential to understand both the requirements of the task and also the uses of the various masking rules. Below are a list of links to the help files on each specific masking rule type.
Substitutes the data in the column of a table. As substitution data this type of rule can use any of the supplied datasets or User Defined Datasets appropriate to the column type. This type of rule can also substitute based on a user supplied Where condition.
Shuffles the data in the column of a table (like a deck of cards) and leaves the other columns untouched. This type of rule can also shuffle based on a user supplied Where condition.
This type of rule is used to run user defined SQL or T-SQL statements within the target database.
![]() Row-Internal Synchronization Rules
Row-Internal Synchronization Rules
A Row-Internal Synchronization Rule updates a field in a row with a combination of values from the same row.
![]() Table-Internal Synchronization Rules
Table-Internal Synchronization Rules
A Table-Internal Synchronization Rule updates columns in groups of rows within a table to contain identical values.
![]() Table-to-Table Synchronization Rules
Table-to-Table Synchronization Rules
A Table-To-Table Synchronization Rule uses a join condition to update columns in another table to contain identical values.
Inserts new rows into table columns. This type of rule can use as insertion data any of the available datasets appropriate to the column type.
Enables foreign keys in the target database. Each foreign key can be individually marked for enable. Usually used after a Foreign Key Disable Rule has run.
Disables foreign keys in the target database. Usually followed by a Foreign Key Enable Rule after the other masking rules have run.
Enables triggers in the target database. Each trigger can be individually marked for enable. Usually used after a Trigger Disable Rule has run.
Disables triggers in the target database. Usually followed by a Trigger Enable Rule after the other masking rules have run.
A Rule Controller contains login information. Rule Controllers tell their dependent masking rules which server and database they should connect to in order to perform their actions. All other masking rule types must have a parent Rule Controller and every masking set must contain at least one Rule Controller.
Important Note: The first Rule Controller is created when the masking set is built. Most masking sets will only ever need one Rule Controller. If it is required to connect to a second database within the same masking set (rather than just building a second masking set) then additional Rule Controllers can be created.
Some Answers to Questions You Might Have
I want the masked data to look similar to the original data.
This is most likely a substitution operation and a Substitution Rule is usually appropriate. It is important to note that Data Masker datasets are not just simple lists of replacement information. They provide a wide range of functionality. For example, the Null Values dataset removes data by replacing it with null values, the Paragraphs of Gibberish dataset generates random collections of sentences and the Date Variance dataset can vary existing dates randomly between user defined boundaries. The Data Masker software comes equipped with datasets for just about every purpose.
The substitution is a bit tricky. I need to substitute different values depending on other column values.
This is still a Substitution rule with a dataset. Just apply a Where Clause to the Substitution rule to restrict the masking operations to a subset of the table rows. It is also possible to Sample the table contents. Often it is necessary to use multiple rules to achieve a masking operation. For example, you might mask the FIRST_NAME column in all rows with the Male First Names dataset and then add a second rule to mask the FIRST_NAME column in the rows WHERE GENDER='F' with the Female First Names dataset. Note that in cases such as the previous example, it is better to use one rule which does all rows and then add a second which picks up one of the special cases rather than two rules each with Where Clauses. See the section on Where Clause skips in the Data Masking: What You Need to Know Before You Begin white paper for a comprehensive discussion of this issue.
The substitution information is pretty specific to our organization. There is no dataset for it.
No problem, you can define your own if you need to do so. User Defined Datasets are simple text files with one item per line. They are used in Substitution Rules just like the ones supplied with the Data Masker software.
The substitution data is complex, there is no suitable dataset and User Defined Datasets are not approprate.
Think about why this might be - is it because the structure of the data is very complex? If so, investigate using a Row-Internal Synchronization rule to build the replacement data. You can even use a Row-Internal Synchronization rule type to call a user defined function or stored procedure. If a Row-Internal Synchronization rule is not the answer, consider using a custom written Command Rule. Also investigate the use of the Text, Alpha-Numeric (Formatted) and Numbers, Integer (formatted) datasets.
I would like to keep the existing data - just jumble it up among the rows in the table.
This is a task for a Shuffle Rule. Shuffle rules randomly move the existing values in a column of data between the rows. This masks the data by removing the associations between items in the same row.
I have masked some data and I need to make some other columns change to the same values.
This is synchronization - and there are three types. The way to choose the most appropriate type is to consider the location of the source and target columns. If the information has to be synchronized in columns within the same row, then the requirement is Row-Internal Synchronization and a Row-Internal Synchronization rule is the option to choose. If the data to be synchronized consists of making groups of rows in the same table contain columns with identical values, then the Table-Internal Synchronization is required and a Table-Internal Synchronization rule is the one to use. The final type of synchronization is Table-To-Table - this occurs when the data in one table needs to match the newly masked data in another. This is probably the most common type of synchronization and the Table-To-Table Synchronization rule is designed for that purpose.
I have an empty table, I need to populate it with dummy data.
This is a job for an Insertion rule. An Insertion rule works just like a Substitution rule except that it creates rows rather than substituting existing values. Usually Insertion rules are used to populate the NOT NULL columns of a table then substitution rules (with appropriate datasets) are used to fill in the other empty fields.
I need to perform an action such as truncating a table or creating a temporary index.
This is definitely a task for a Command rule. A Command rule can run any SQL command or T-SQL block. This includes such things as building or dropping tables or performing manual inserts and updates.
Some rules are running slowly because UPDATE triggers are firing.
Confirm that it is not essential for the triggers to fire and implement a Trigger Disable to disable the triggers and a subsequent Trigger Enable rule to re-enable them once the other masking rules have finished. Be sure to use rule blocks in order to make sure the Trigger Disable and Enable rules execute in the proper sequence.
This documentation contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved




