Static data
Published 25 November 2022
Flyway Enterprise
One thing to consider when working with databases is how to maintain static data in your project. This is also referred to as configuration or lookup data. This can include data such as zip/postal codes, country lists, or even application settings. This static data should be tracked in version control so users can understand how, when, and why it changed over time and who made the changes. It's also important that this data be deployed alongside other database changes. By capturing static data changes with Flyway in Versioned Migration Scripts, your static data can be tracked and deployed as part of your same version control repository and deployment pipelines.
Configure static data
- Open your project in Flyway Desktop.
- On the Schema model tab, click on the Manage Static Data button.
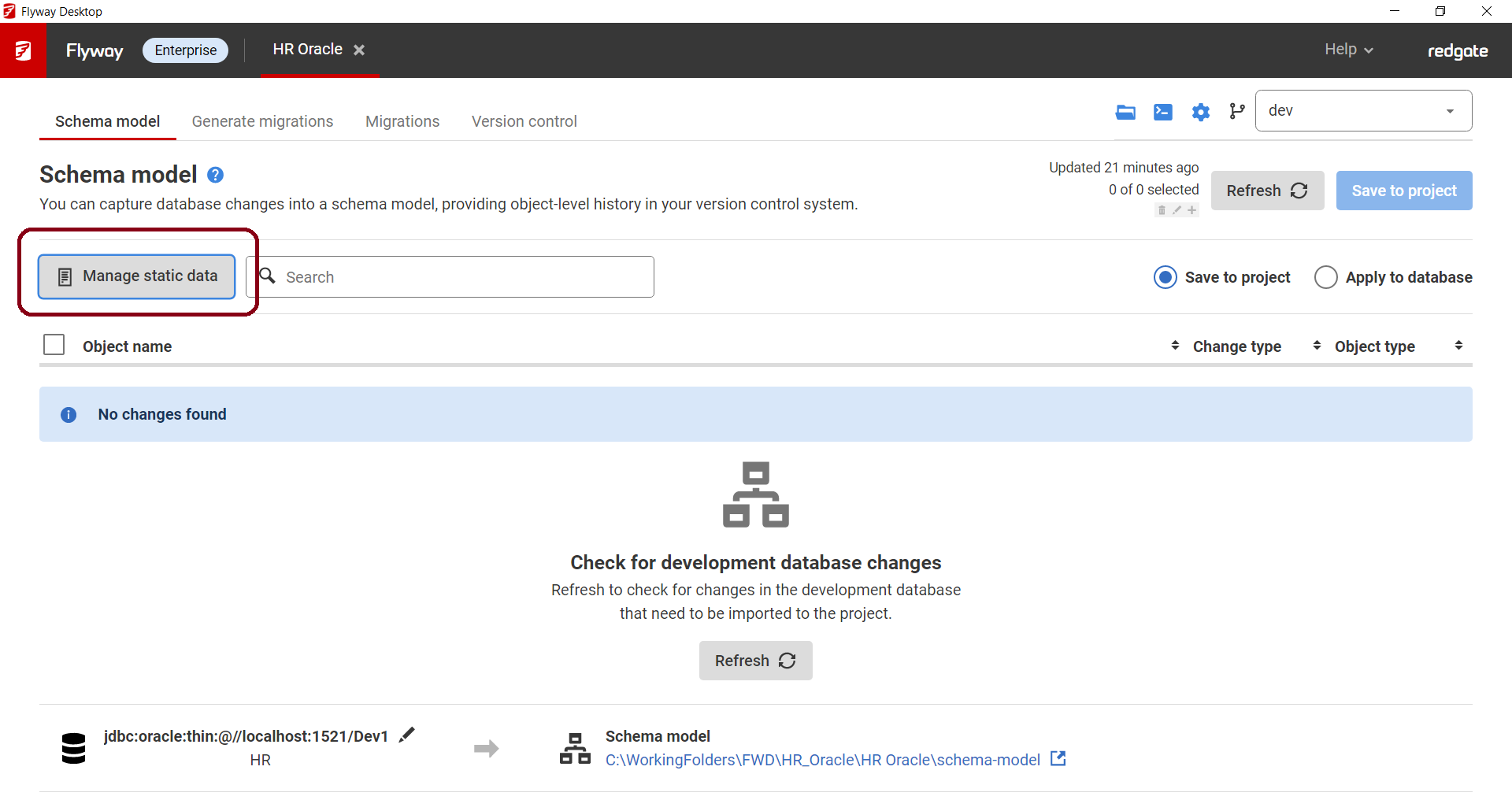
- Using the drop down, select the tables that you want to identify as containing static data from the list. You can start typing in the select box to more easily find the static tables you're interested in tracking:
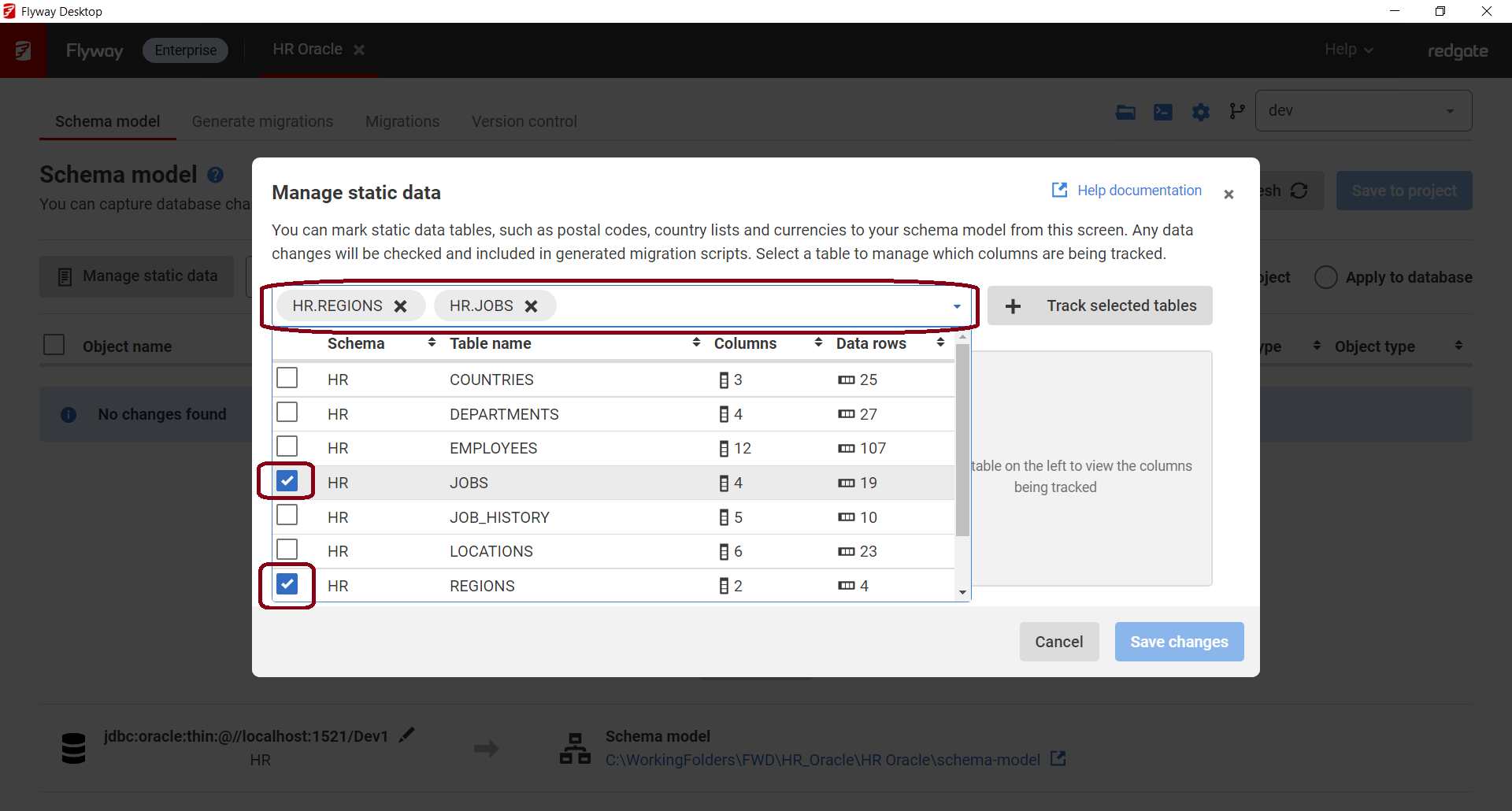
- Click + Track selected tables and close the drop down to see the tables you selected in the list below:
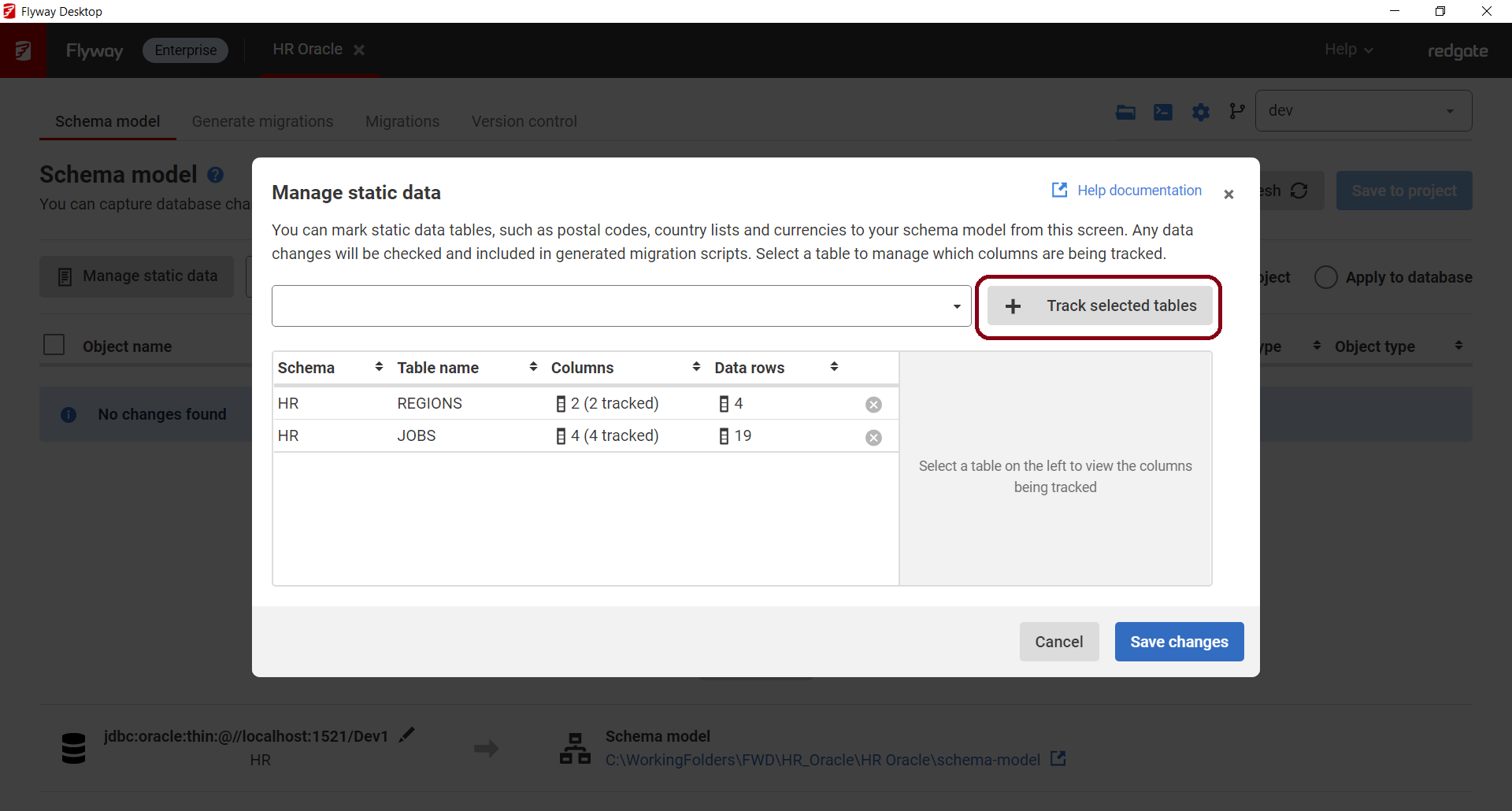
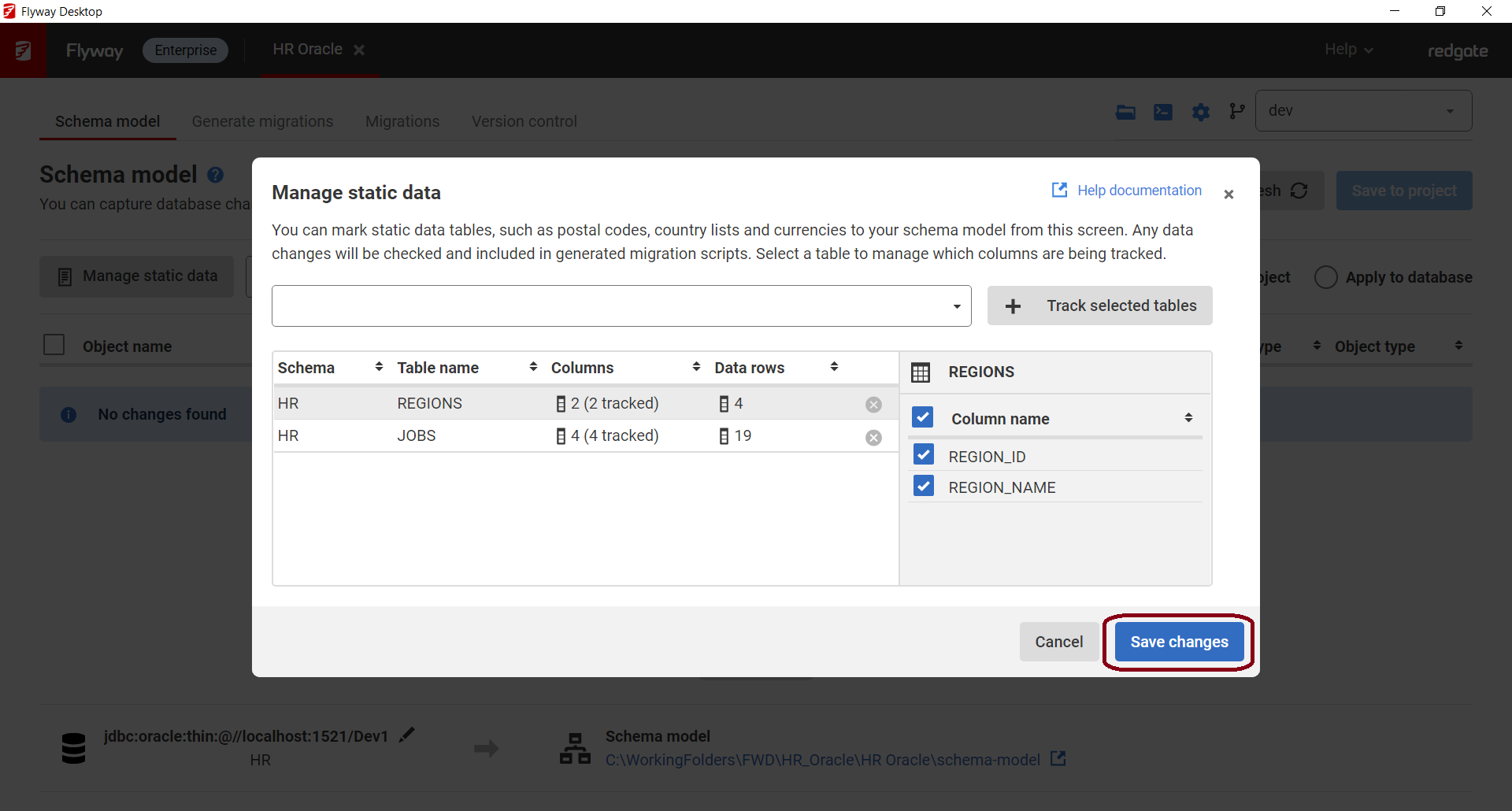
- Optionally, you can select a table from the list and choose what columns to include in version control. This could come in handy if you have a CreatedDate column that automatically gets populated when the record is created. Therefore, this column may differ across environments.

- Click Save changes.
- Since this is the first time identifying these tables as static data, they will appear in the list of schema model changes. You can click on the table name with the "Data" object type and see the data at the bottom. Select the changes you're ready to Save to project to save this changes to disk so they can be tracked in version control.
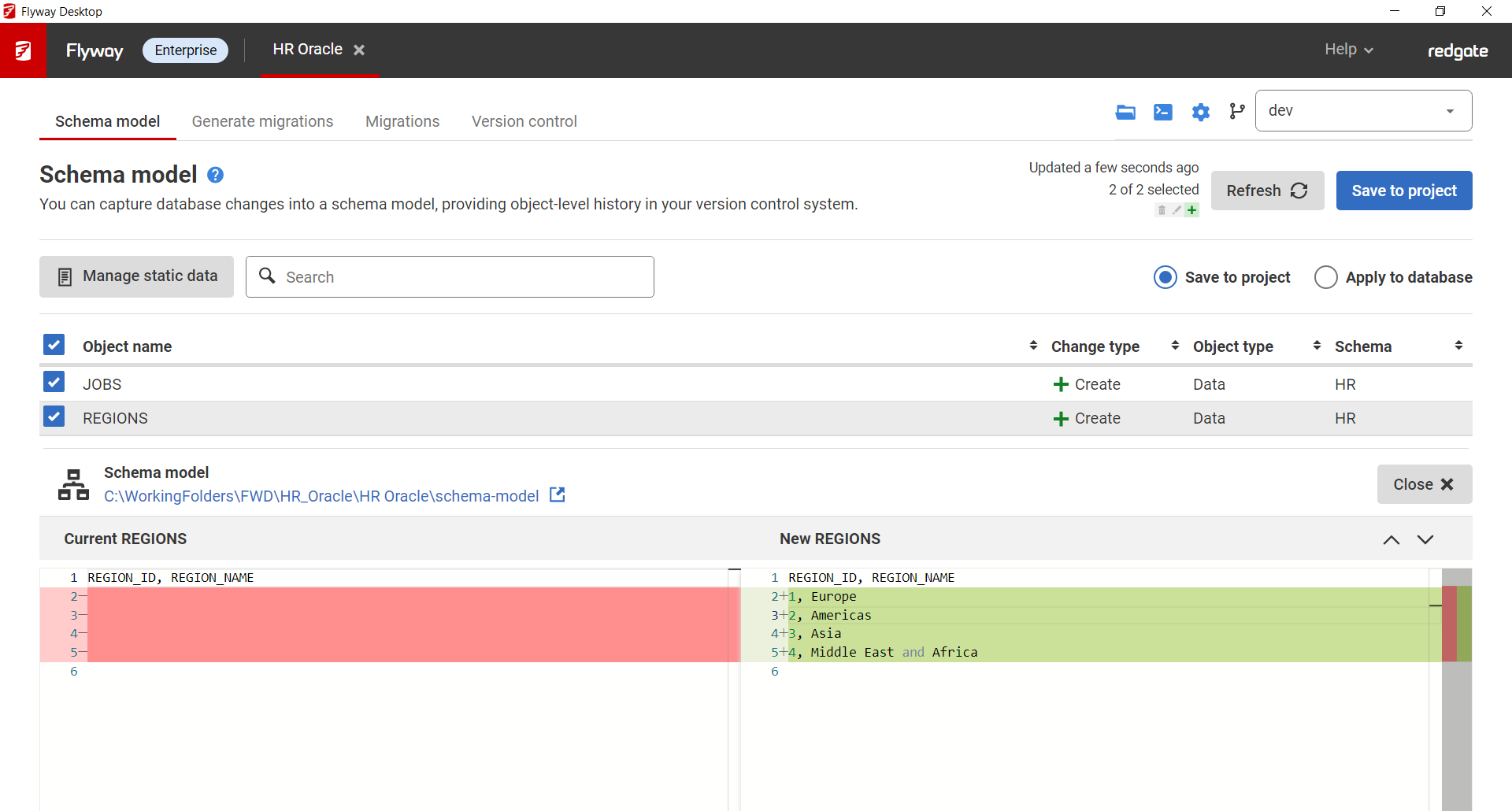
Any new changes to static data that have been saved to the project will be displayed on the Generate migrations tab and can be selected to generate INSERT/UPDATE/DELETE statements in a versioned migration script. If you're project is setup to generate undo scripts, the corresponding undo changes for the static data will also be included in the undo migration.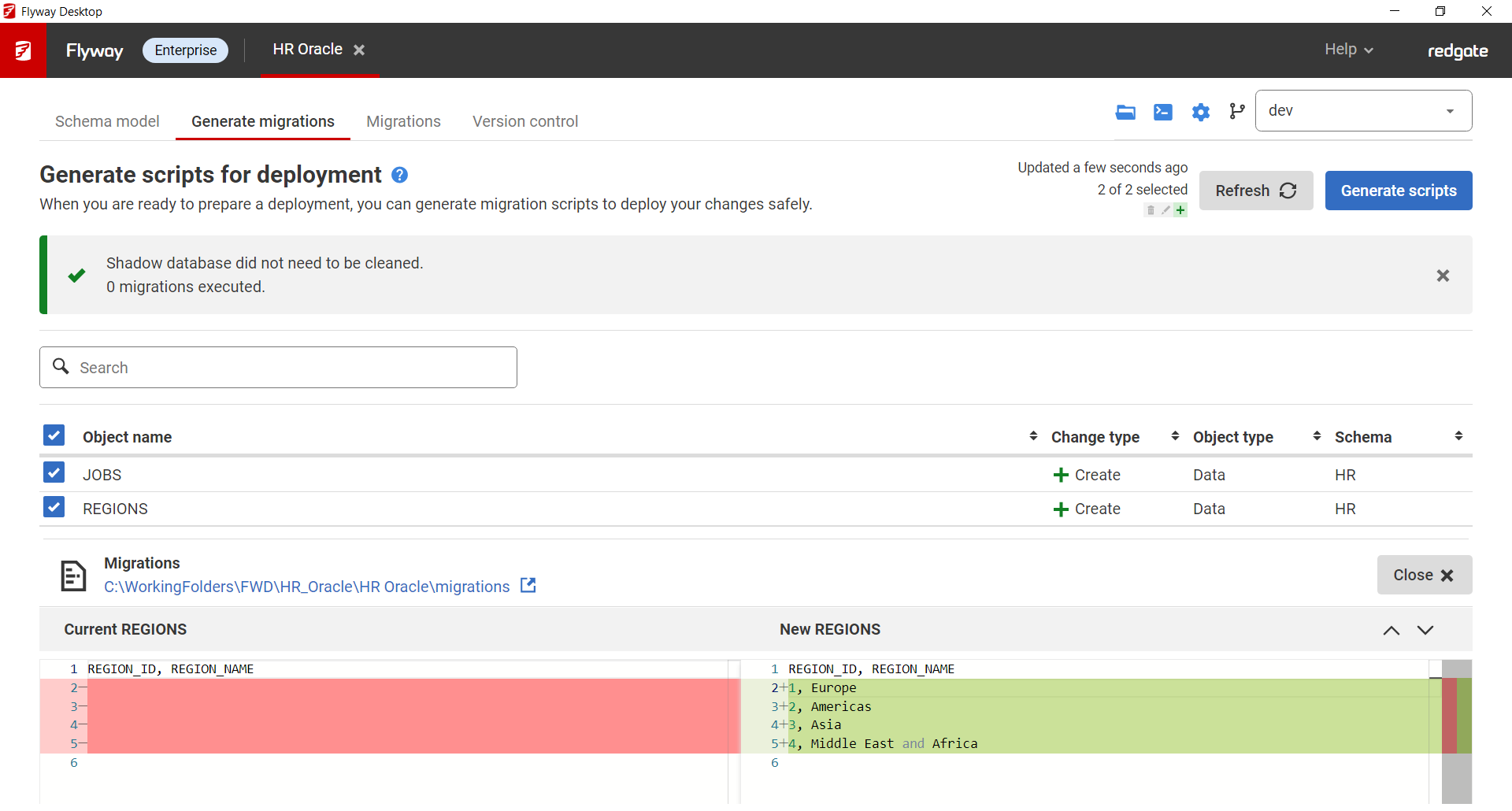 →
→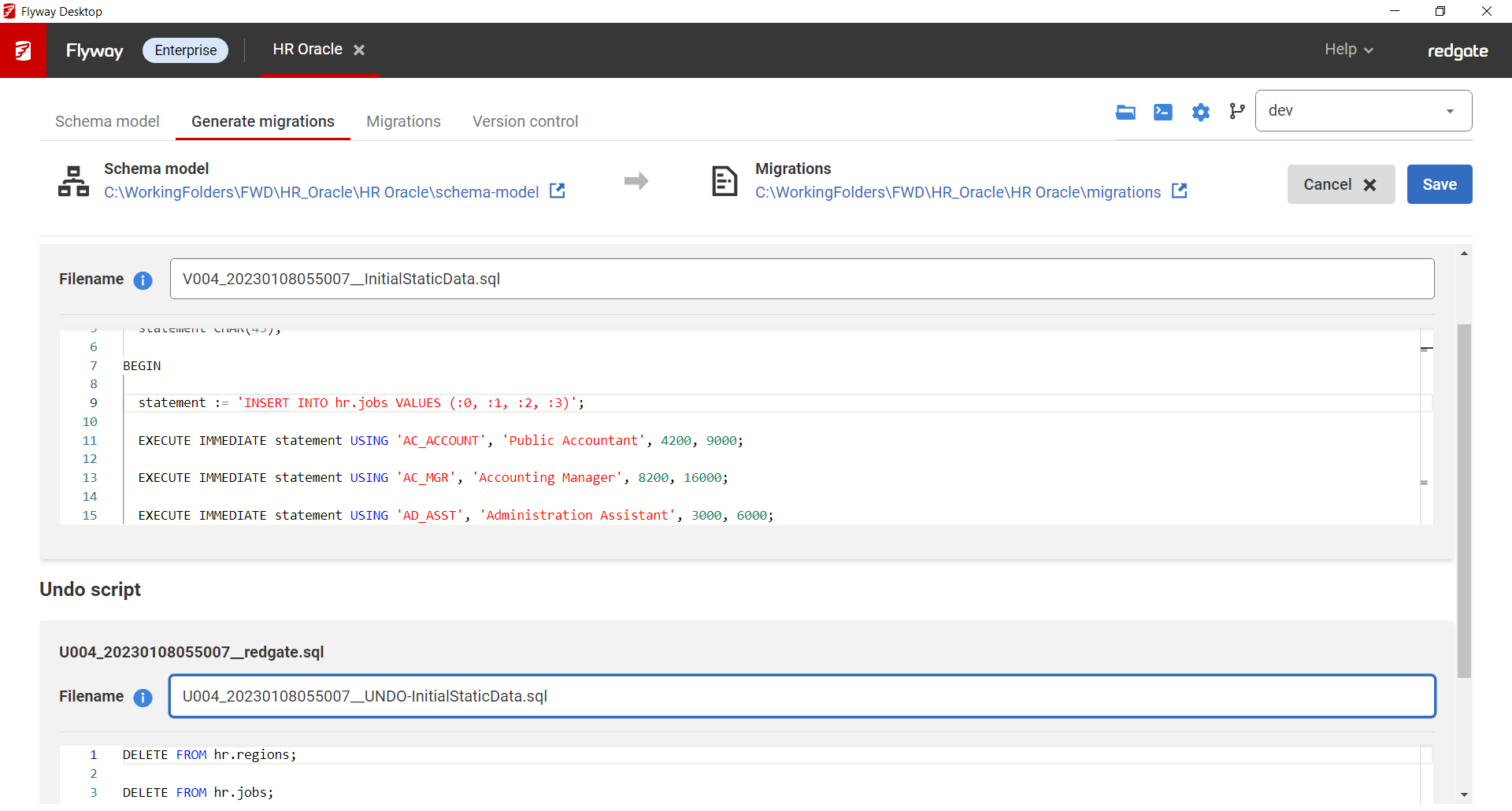
Now, the process is similar to making schema changes. Edit the data directly in your development database. Changes to static data will show up in the Schema model. Once saved to the project, migrations can be generated for deployment.
Primary Key requirement
In order to track the data within your tables, the table must include a primary key. If a primary key is not present, the data within the table will be ignored. If possible, it's best to add a Primary Key to the table. This will help performance when comparing the data. Please add a suggestion/vote to support Static Data for Tables without a primary key, if you need this.
Workaround:
Use our data comparison tools, which come with Flyway Enterprise, to compare your development database to the schema-model in your local respository. On the Tables & Views tab, you can specify a comparison key that is unique and save these changes to the schema-model on disk.
You can then Generate a deployment script using SQL Data Compare. In Flyway Desktop, go to the Migrations tab and click Add a Migration. You can then import or copy and paste the data script into the new Versioned Script. This change can then be version controlled and will be deployed through your CI/CD process just like other versioned migration scripts.
Baselining Static Data
It is important to include any static data that has already been deployed to your downstream environments as part of a baseline. This means new environments can be built from scratch using the scripts in the repository. This also means we won't generate a new migration script for static data that already exists in your downstream environments.
For new projects:
- Create a new project.
- On the Schema model tab, setup your development database.
- Click Manage Static Data and configure your static data as described above. For the baseline, only specify static data that is already deployed to your downstream environments.
- If development has additional data that has moved on from what's been deployed, you may want to edit the Data\Table.sql file in your project to remove these rows. (Or, you can just remove the extra records when you generate the the baseline script.
- If development has additional data that has moved on from what's been deployed, you may want to edit the Data\Table.sql file in your project to remove these rows. (Or, you can just remove the extra records when you generate the the baseline script.
- Save your initial object schema and static data to disk.
On the Generate migrations tab, setup your shadow database and create your baseline. Since you're static data has already been configured and saved to the schema-model on disk, this will be picked up in the baseline script.
Limitation
Note: This currently only works for SQL Server.
For Oracle, you'll need to save your table schema first, then select the static data, and then save the data to the schema-model folder. When you generate the baseline script, the static data won't be included, generate another script to pick up the baseline of the static data and copy and paste this into the end of the B script. Refreshing the Generate migrations tab should then show no changes and you can start to create your next V script from here. You will need to do one of the following as a one off step to update your shadow database:
- Manually run the INSERT scripts on your shadow database (consider this if re-running the baseline from scratch takes a while
- Empty your shadow database, so the baseline script, which now contains data, will be re-applied to it by:
- Drop your shadow database and re-create it
- Use the clean command on the Migrations tab against your shadow database. Note: You may need to add your shadow database by configuring the target database connections on this screen.
Please get in touch with our development team if you have any questions.
For PostgreSQL and MySQL, this is on our roadmap. You can manually add scripts with data for now. Please get in touch with our development team for an update on when you'll be able to track changes to static data automatically in these databases.
- After saving your generated baseline script, click Verify to execute it against the shadow database.
- Now is a good point to use the Version control tab to Commit and Push your baseline script to the repository so it's saved and other team members can start working on the project.
- You can now start generating migrations for any changes to objects and static data going forward that will need to be deployed.
For projects that have already been deployed to downstream environments:
- Configure these tables as Static data tables using the steps above.
- Capture the static data that is already in your downstream environments in your Schema model. If your development database has additional static data in an existing deployed table, you'll need to edit the Data\Table.sql file in your project to remove these rows that have not been deployed yet. (Or, you can just remove them when you generate the the migration script.)
- Generate the migration script to capture all the static data changes that have already been deployed to your downstream environments.
- Make sure the script doesn't run on the downstream environments.
- Option 1: Use the migrations tab to connect to each of your downstream environments and update them so that this script is not ran on them.
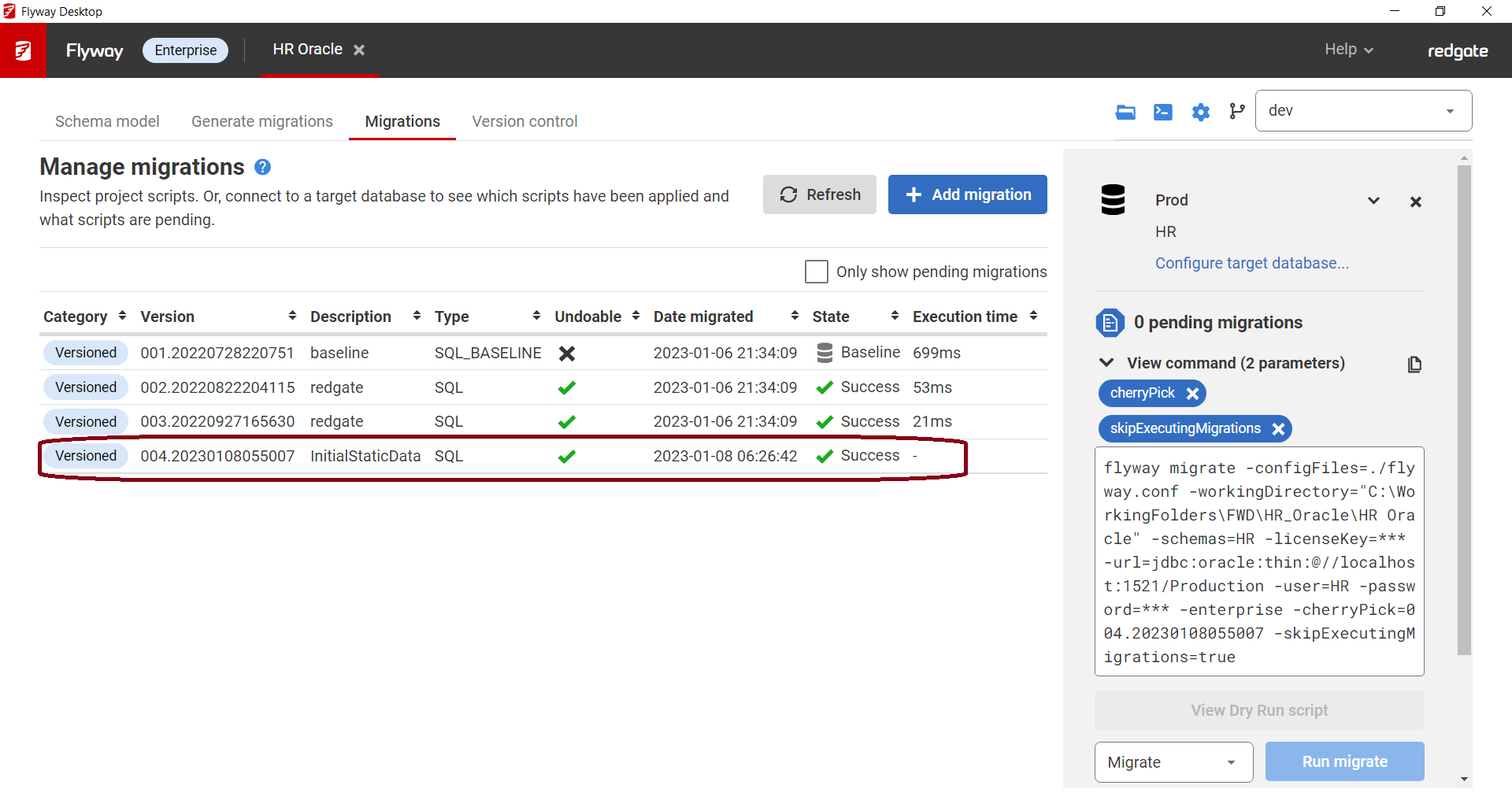
- Choose flyway migrate and add the following parameters:
-cherryPick=<yourStaticDataVersionNumber>
-skipExecutingMigrations=true
In this example, you can see the V004__InitialStaticData.sql script is Pending against my Prod database, but I don't want it to run against Prod since this data already exists in Prod. So I add the parameters above. I can then either click Run migrate or View Dry Run script to see what will happen before migrating.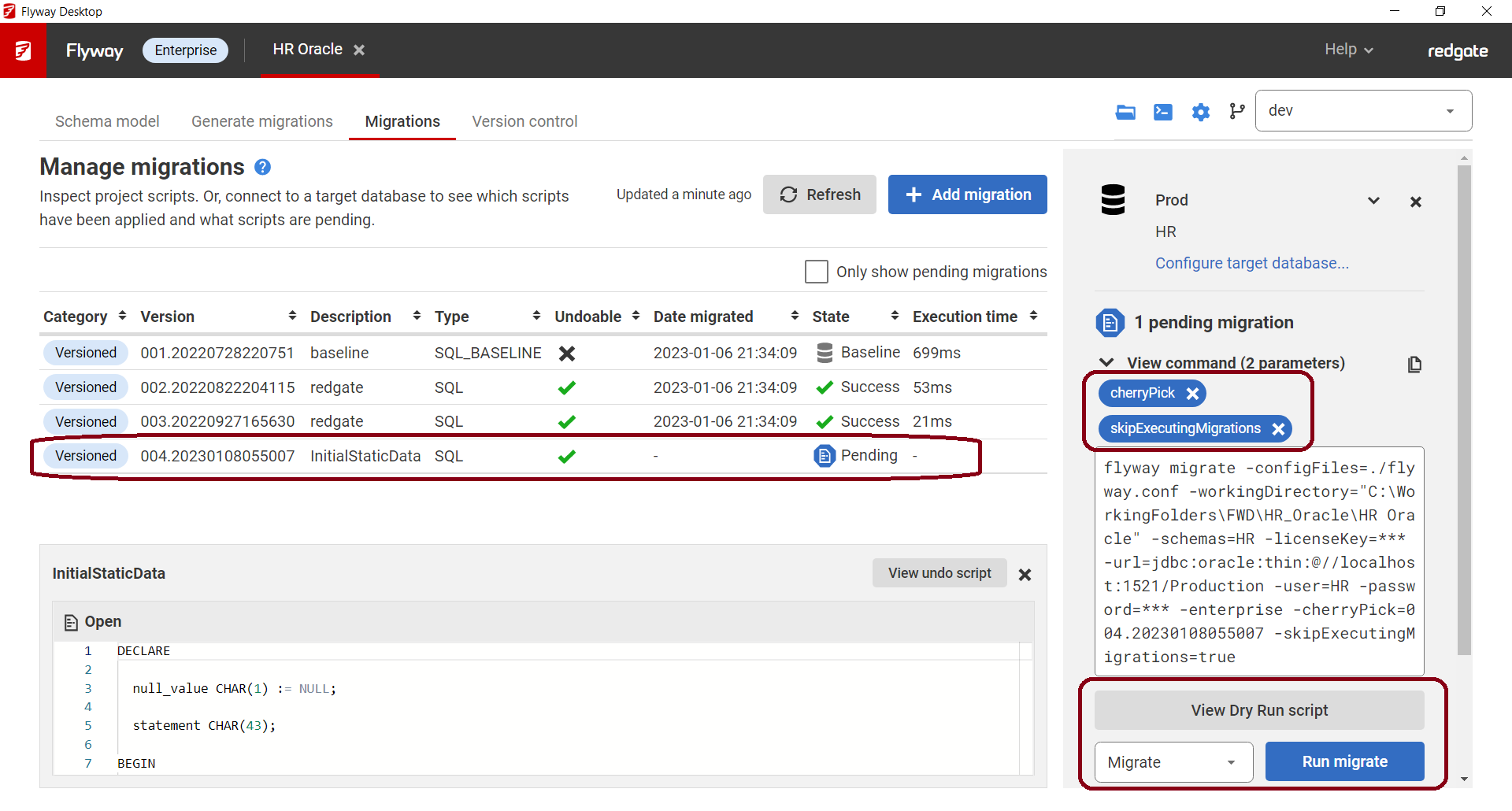
- Clicking View Dry Run script, we can see that running Migrate is only going to insert a record into the flyway_schema_history table so this versioned migration script will recorded so we don't try to execute this script against that target.

- After running migrate, you can see the InitialStaticData script has been marked as successfully applied and it did not take any execution time since it was actually skipped.
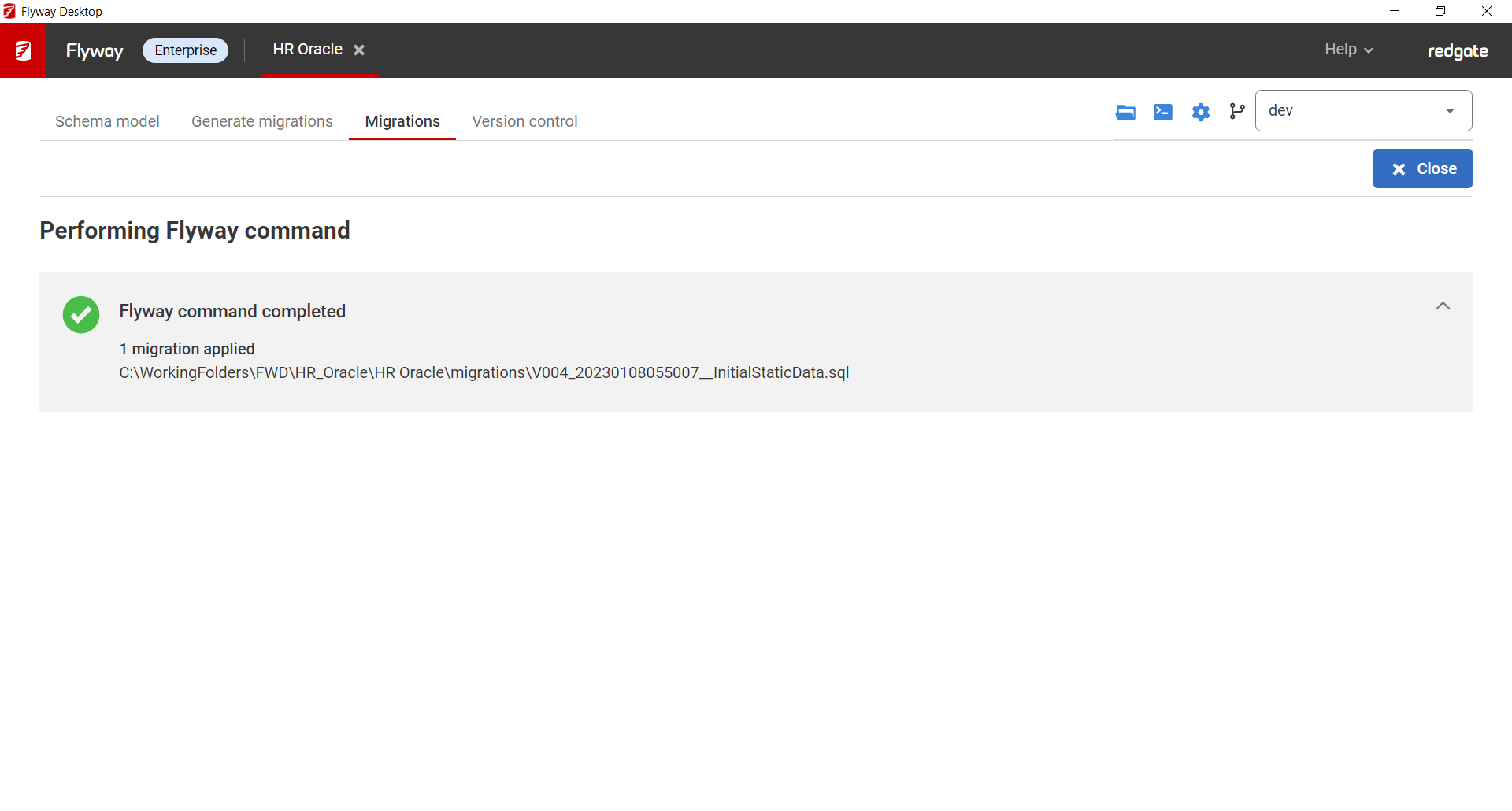 →
→ 
- Choose flyway migrate and add the following parameters:
- Option 2: Use a Guard Clause
- At the top of the generated migration script, write an IF statement to check for the data first before inserting it.
- IF (SELECT COUNT(*) FROM TABLE = <number>)
- THEN
- <do insertions>
- At the top of the generated migration script, write an IF statement to check for the data first before inserting it.
- Option 1: Use the migrations tab to connect to each of your downstream environments and update them so that this script is not ran on them.
Things to Note
Note: You'll need permissions to your downstream environments to migrate them like this. If you only have read-access, you could provide the DBA with the dry run script to update the downstream environments manually or have them fix up the baseline of your static data through Flyway Desktop using the instructions above.
Note 2: If your downstream environments are in different states, it's easier to synchronize them first and then use the process above. You can use our data comparison tools that are included in Flyway Enterprise to check that the static data across your environments are in synch.
If not, you'll need multiple V scripts to capture the different states. This can be complicated as shown in the following example:
The MyCodes table has the following values in the different environments.
| Dev | Test | QA | Staging | Production |
|---|---|---|---|---|
MyCodes | MyCodes 1 2 3 4 | MyCodes 1 2 3 | MyCodes 1 2 | MyCodes 1 2 |
You would need to:
- Create a V script (e.g., V002__MyCodes-twoRecords.sql) that inserts 1 and 2 and cherryPick V002 and skip it's execution on Staging and Prod.
- Create another V script (e.g., V003__MyCodes-thirdRecord.sql) that inserts 3. Then, cherryPick V002, V003 and skip it's execution on QA, since value 3 already exists there.
- Create another V script (e.g., V004__MyCodes-fourthRecord.sql) that inserts 4. Then, cherryPick V002,V003,V004 and skip it's execution on Test, since value 4 already exists there.
The next time you go to migrate Test, no scripts will be pending.
The next time you go to migrate QA, only V004 will be pending.
The next time you go to migrate Staging and Prod, V003 and V004 will be pending.
Advanced Configuration - Comparison Options
Static data tables selected in the GUI are saved in the capabilities > staticData section in the project settings. Static data options can be specified by adding a comparisonOptions section to the static data configuration. These cannot currently be set from the GUI.
- ...
- "capabilities": {
- "staticData": {
- "configuredTables": [
- {
- "schema": "dbo",
- "table": "Table_1"
- },
- {
- "schema": "dbo",
- "table": "Table_2",
- "excludedColumns": [
- "col2"
- ]
- }
- ],
- "comparisonOptions": {
- "trimTrailingSpaces": true
- }
- }
- }
- ...
SQL Server options
Here is a complete list of the available SQL Server options. For the definitions of these options, please see the SQL Data Compare documentation.
| Option | Type |
|---|---|
DisableForeignKeys | Boolean |
DropKeysIndexesAndConstraints | Boolean |
DisableDmlTriggers | Boolean |
DisableDdlTriggers | Boolean |
DontIncludeCommentsInScript | Boolean |
ReseedIdentityColumns | Boolean |
SkipIntegrityChecksForForeignKeys | Boolean |
TransportClrDataTypesAsBinary | Boolean |
IncludeTimestampColumns | Boolean |
CaseSensitiveObjectDefinition | Boolean |
ForceBinaryCollation | Boolean |
TrimTrailingSpaces | Boolean |
CompressTemporaryFiles | Boolean |
TreatEmptyStringAsNull | Boolean |
UseChecksumComparison | Boolean |
UseMaxPrecisionForFloatComparison | Boolean |
Oracle options
Here is a complete list of the available Oracle options. For the definitions of these options, please see the Data Compare for Oracle documentation.
| Option | Type |
|---|---|
CheckForData | Boolean |
IncludeViews | Boolean |
TrimTrailingSpaces | Boolean |
IgnoreControlCharacters | Boolean |
IgnoreWhiteSpace | Boolean |
IncludeSourceTables | Boolean |
IgnoreDateTypeDifferences | Boolean |
DatabaseTimeZone | Boolean |
Get in touch with the Database DevOps Development Team if you have any questions/feedback about this feature.
Advanced Options
- Using Repeatable Migrations to manage data
- Using Script Migrations to manage data
- Using Redgate's Data Compare technology to version control and generate migration scripts
- Different data for different environments or clients




